Pushing the Memory Bandwidth Wall with CXL-enabled Idle I/O Bandwidth Harvesting
By Divya Kiran Kadiyala and Alexandros Daglis
Georgia Institute of Technology, Atlanta, Georgia, USA
Abstract
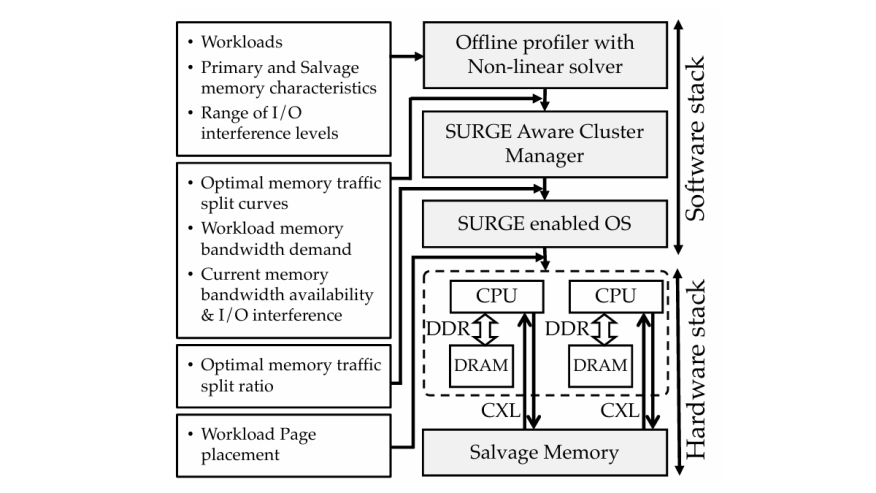
The continual increase of cores on server-grade CPUs raises demands on memory systems, which are constrained by limited off-chip pin and data transfer rate scalability. As a result, high-end processors typically feature lower memory bandwidth per core, at the detriment of memory-intensive workloads. We propose alleviating this challenge by improving the utility of the CPU's limited pins. In a typical CPU design process, the available pins are apportioned between memory and I/O traffic, each accounting for about half of the total off-chip bandwidth availability. Consequently, unless both memory and I/O are simultaneously highly utilized, such fragmentation leads to underutilization of the valuable off-chip bandwidth resources. An ideal architecture would offer I/O and memory bandwidth fungibility, allowing use of the aggregate off-chip bandwidth in the form required by each workload.
In this work, we introduce SURGE, a software-supported architectural technique that boosts memory bandwidth availability by salvaging idle I/O bandwidth resources. SURGE leverages the capability of versatile interconnect technologies like CXL to dynamically multiplex memory and I/O traffic over the same processor interface. We demonstrate that SURGE-enhanced architectures can accelerate memory-intensive workloads on bandwidth-constrained servers by up to 1.3x.
To read the full article, click here
Related Semiconductor IP
- CXL 4 Verification IP
- VIP for Compute Express Link (CXL)
- CXL 3.0 Controller
- CXL Controller
- CXL 4.0/3.2/3/2 Verification IP
Related Articles
- How to accelerate memory bandwidth by 50% with ZeroPoint technology
- Breaking the Memory Bandwidth Boundary. GDDR7 IP Design Challenges & Solutions
- TeraPool: A Physical Design Aware, 1024 RISC-V Cores Shared-L1-Memory Scaled-up Cluster Design with High Bandwidth Main Memory Link
- High bandwidth memory (HBM) PHY IP verification
Latest Articles
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks