FengHuang: Next-Generation Memory Orchestration for AI Inferencing
By Jiamin Li, Lei Qu, Tao Zhang, Grigory Chirkov, Shuotao Xu, Peng Cheng, Lidong Zhou
Microsoft Research
Abstract
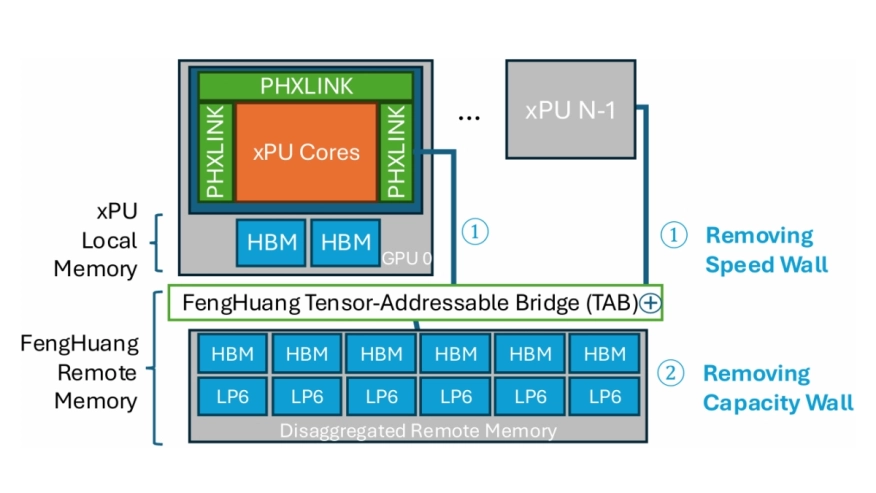
This document presents a vision for a novel AI infrastructure design that has been initially validated through inference simulations on state-of-the-art large language models. Advancements in deep learning and specialized hardware have driven the rapid growth of large language models (LLMs) and generative AI systems. However, traditional GPU-centric architectures face scalability challenges for inference workloads due to limitations in memory capacity, bandwidth, and interconnect scaling. To address these issues, the FengHuang Platform, a disaggregated AI infrastructure platform, is proposed to overcome memory and communication scaling limits for AI inference. FengHuang features a multi-tier shared-memory architecture combining high-speed local memory with centralized disaggregated remote memory, enhanced by active tensor paging and near-memory compute for tensor operations. Simulations demonstrate that FengHuang achieves up to 93% local memory capacity reduction, 50% GPU compute savings, and 16x to 70x faster inter-GPU communication compared to conventional GPU scaling. Across workloads such as GPT-3, Grok-1, and QWEN3-235B, FengHuang enables up to 50% GPU reductions while maintaining end-user performance, offering a scalable, flexible, and cost-effective solution for AI inference infrastructure. FengHuang provides an optimal balance as a rack-level AI infrastructure scale-up solution. Its open, heterogeneous design eliminates vendor lock-in and enhances supply chain flexibility, enabling significant infrastructure and power cost reductions.
To read the full article, click here
Related Semiconductor IP
- E-Series GPU IP
- Arm's most performance and efficient GPU till date, offering unparalled mobile gaming and ML performance
- Highest performance automotive GPU IP, with revolutionary functional safety technology
- High performance GPU for cloud gaming with DirectX support
- Arm’s latest flagship GPU is based on the new 5th Gen GPU architecture, bringing the next generation of visual computing to mobile
Related Articles
- A novel 3D buffer memory for AI and machine learning
- Resistive RAM for next-generation nonvolatile memory
- Why the Memory Subsystem is Critical in Inferencing Chips
- The benefit of non-volatile memory (NVM) for edge AI
Latest Articles
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks