Evolution of CXL PBR Switch in the CXL Fabric
Compute Express Link (CXL) is a transformative technology that significantly improves memory access performance. As technology continues to advance, so do the ways we connect and manage and access memory in our computing systems, there is a Port-Based Routing (PBR) in a CXL fabric is a key innovation introduced in CXL 3.0 and 3.1 that enables flexible, scalable, and efficient connected and communication across a computing environment, that revolutionized how CXL switches operate within a CXL fabric. It addresses the limitations of earlier CXL versions and enables the creation of much larger, more flexible, and more efficient topologies.
Switch Topology and CXL Fabric
CXL Switch provides a way to expand PCIe/CXL hierarchy by adding multiple devices. A device that enables a CXL fabric, allowing multiple hosts to connect to a pool of multiple CXL devices. Essential memory pooling supports up to 4,096 nodes, each able to communicate with one another via a PBR addressing mechanism.
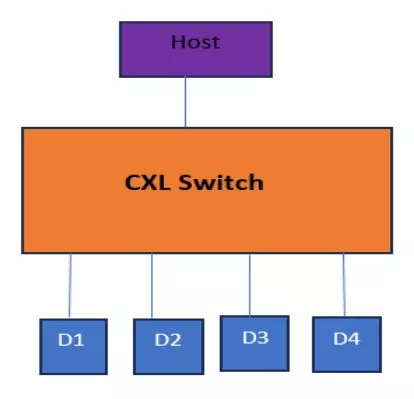
Figure 1: CXL Switch
Port-Based Routing (PBR)
Port-Based Routing is a route-based on the Port ID. A PBR switch requires an assigned PID to send and receive management requests, responses, and notifications. Transactions that target this PID are processed by a switch. Switches are managed by the Fabric Manager.
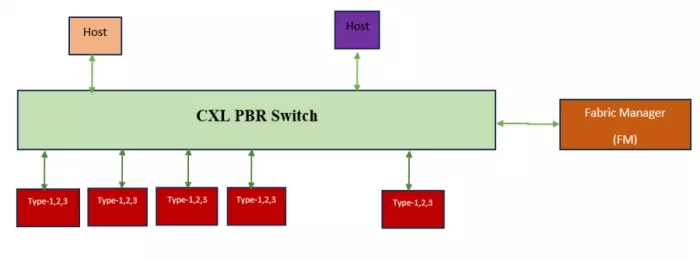
Figure 2: CXL PBR Switch with Fabric Manager
In a CXL fabric architecture with PBR switches, a transaction originating from one device and destined for another device connected to a different switch will be routed through the appropriate switches based on the Destination PBR ID in the transaction and the routing tables. CXL switch connected to a device or host (an edge port) is assigned a PBR ID. PBR routing is determined by a Port-Based Routing ID (PBR ID), which is carried out in the CXL transaction, instead of relying on a strict hierarchical address space.
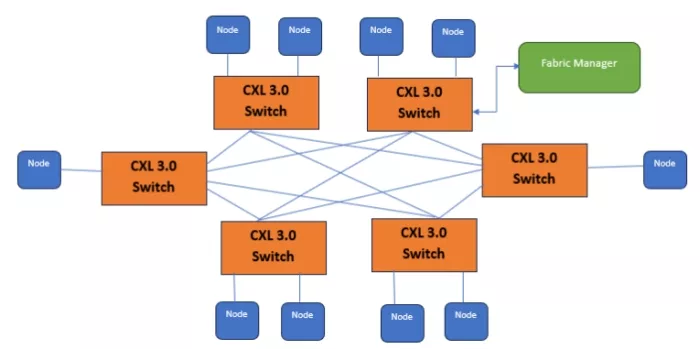
Figure 3: CXL fabric-based PBR Switch transaction
There are two PBR ID routing approaches in the CXL transaction, which are defined below:
Destination PBR ID (DPID): Each CXL transaction includes a DPID that indicates the target port on the CXL fabric.
Source PBR ID (SPID): Similarly, SPID indicates the originating or source port.
Routing Tables: CXL switches maintain routing tables that contain information about which PBR IDs are reachable through which of their ports. The CXL Fabric Manager configures and manages these routing tables.
PBR switches support both static and dynamic routing for each DPID.
PBR Routing at the Mesh Topology
In a mesh topology, a CXL switch can connect to multiple other CXL switches, providing redundant paths and better load balancing. It enables a truly composable infrastructure, where resources can be dynamically configured and reconfigured without the hierarchical constraints of PCIe. Enables non-tree (mesh, ring, spine-leaf) Topologies: HBR largely restricted CXL fabrics to tree-like structures. PBR breaks this limitation, allowing CXL switches to form complex fabric topologies like mesh, ring, or spine-leaf networks.
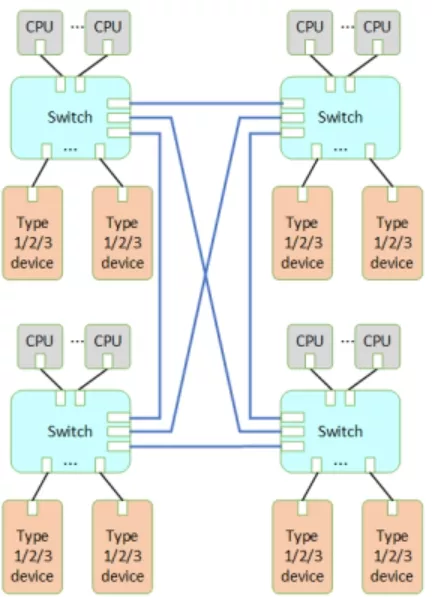
Figure 4: CXL Switch Mesh Topology
Advantages of PBR in CXL Switches
- Greatly increased scalability: PBR allows CXL fabrics to scale to thousands of nodes (up to 4,096 in CXL 3.0). Scalability is essential for rack-scale and even pod-scale memory and compute disaggregation.
- Reduced latency for peer-to-peer communication: One of the most significant benefits of PBR is enabling truly efficient peer-to-peer (P2P) communication between CXL devices.
- PBR allows devices to directly communicate with each other through the CXL switch, potentially bypassing the host CPU. This dramatically reduces latency for device-to-device transfers (e.g., accelerator to memory, or accelerator to accelerator), which is critical for demanding AI/ML, HPC, and data analytics workloads.
- Enhanced resource utilization and flexibility: By supporting complex topologies and direct device-to-device communication, PBR further optimizes resource utilization. Memory can be more fluidly shared and accessed by multiple hosts and accelerators across the fabric.
- Simplified fabric management (with fabric manager APIs): While PBR enables complex fabrics, CXL 3.0 also defined enhanced fabric manager APIs. These APIs allow software to discover, configure, and manage the PBR switches and the entire CXL fabric, making the complexity manageable for system administrators.
Application
- Large-scale AI/ML model: Multiple GPUs/accelerators can directly access shared memory pools or exchange data with each other over the CXL fabric with low latency, accelerating training times for massive models.
- High-Performance Computing (HPC): Scientific simulations and modeling often require vast amounts of memory and rapid data exchange between compute nodes. PBR-enabled CXL fabrics provide the necessary bandwidth and low latency.
- In-memory databases and analytics: PBR supports the creation of huge, shared memory pools that can be coherently accessed by many compute nodes, significantly boosting the performance of in-memory databases and real-time analytics.
- Cloud data centers: Cloud providers can achieve unprecedented levels of memory and accelerator disaggregation, leading to more efficient resource allocation, reduced stranded resources, and lower TCO.
For more information, reach out to us at talk_to_vip_expert@cadence.com.
Learn More
- For more information on how Cadence PCIe Verification IP and TripleCheck VIP enable users to confidently verify IDE. For message routing, see our VIP for PCI Express, VIP for Compute Express Link, and TripleCheck for PCI Express.
- For more information on PCIe in general, and on the various PCI standards, see the PCI-SIG website.
- For more information on CXL in general, see the CXL consortium website.
Related Semiconductor IP
- CXL 4 Verification IP
- VIP for Compute Express Link (CXL)
- CXL 3.0 Controller
- CXL Controller IP
- CXL memory expansion
Related Blogs
- The Evolution of CXL.CacheMem IDE: Insights into CXL3.0 Security Feature
- CXL Fabric Manager Advances Next-Gen Data Centers
- CXL 3.1: What's Next for CXL-based Memory in the Data Center
- Navigating Cache Coherence: The Back-Invalidate Feature in CXL 3.0
Latest Blogs
- Area, Pipelining, Integration: A Comparison of SHA-2 and SHA-3 for embedded Systems.
- Why Your Next Smartphone Needs Micro-Cooling
- Teaching AI Agents to Speak Hardware
- SOCAMM: Modernizing Data Center Memory with LPDDR6/5X
- Bridging the Gap: Why eFPGA Integration is a Managed Reality, Not a Schedule Risk