CNNs and Transformers: Decoding the Titans of AI
In the rapidly advancing field of artificial intelligence, two neural network architectures have become prominent: convolutional neural networks (CNNs) and transformers. Each architecture has brought significant advancements to various domains, ranging from image recognition, video surveillance to natural language processing (NLP), speech recognition and generation, multimodal AI and more. This article aims to compare their differences and respective strengths and highlight how specialized hardware like Tensilica Vision DSPs accelerates these models for real-world applications.
CNNs: Experts in Local Feature Detection
CNNs have been the preferred architecture for computer vision tasks for a significant period. Inspired by the human visual cortex and designed to identify local patterns in data, they process input (such as an image) through a series of convolutional layers, each using learnable filters that slide over the data to detect simple features like edges, textures, and shapes. As the data progresses through layers, these small features combine to form higher-level features (for example, edges combine into shapes, which combine into object parts).
Periodically, pooling layers reduces the spatial size of the data by down sampling, which preserves important information while discarding details. Pooling makes the network more efficient and tolerant to minor shifts or distortions in the input. Finally, one or more fully connected layers (dense neural layers) take the extracted feature maps and produce the final predictions (such as class probabilities in classification, or coordinates in detection). In essence, a CNN looks at an image in small pieces and learns which local patterns are important for the task, then uses those to make decisions about the whole image.
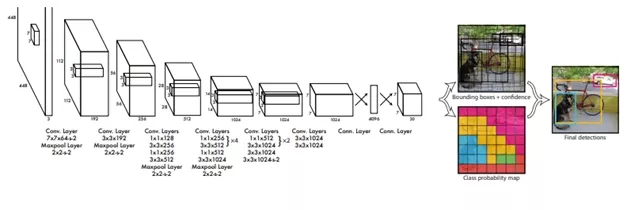
Advantages of CNNs
- Image and Video Processing: With their ability to focus on local features, CNNs are optimal for tasks such as object detection, facial recognition, and segmentation.
- Efficiency: CNNs require fewer computational resources by reusing the same filters and using fewer parameters and operations. This makes CNNs particularly well-suited for real-time applications or edge devices with limited resources.
- Intrinsic Inductive Biases: Assumptions regarding locality (that nearby pixels are more related) and translation invariance (that a pattern’s meaning doesn’t change if its position shifts) enable CNNs to learn and perform effectively even with limited data. For example, a CNN can recognize a cat in an image even if the cat appears in different positions, without needing separate training for each position.
Limitations of CNNs
- Limited Global Context: Because CNN filters and pooling focus on one region at a time, CNNs can struggle with understanding long-range dependencies, i.e. they might miss relationships between distant parts of an image. For instance, a CNN might have difficulty relating an object in the top-left corner of an image with another object in the bottom-right if those relationships are important for the task.
- Sensitivity to Transformations: While CNNs handle small shifts or distortions well (thanks to pooling), larger transformations like significant rotations, viewpoint changes, or scale differences may degrade CNN performance if not accounted for in training. For example, a CNN trained mostly on upright images of an object might perform poorly if the object appears upside-down, unless the training data included such variations.
Transformers: Harnessing Global Context (Domain-Agnostic Models)
Transformers, introduced in 2017 by the paper “Attention Is All You Need”, take a very different approach than CNNs. Rather than scanning data piece by piece, a transformer uses a mechanism called self-attention to process the entire input in parallel.
In a transformer, each element of the input (for example, a word in a sentence or a patch of an image) looks at every other element to decide what is important. This is achieved by computing attention scores – essentially, each part asks, “how relevant are all the other parts to me?” and then aggregates information weighted by those relevance scores.
In practice, an image is divided into patches (small blocks of pixels) that are embedded into vectors; positional encodings are added to retain information about each patch’s location in the original image.
For text, each word is embedded and combined with positional information indicating its place in the sequence. The transformer processes these sequences of embeddings through stacked layers of self-attention and simple feed-forward networks. The result is that each output element contains information from across the entire input sequence due to these attention links.
Critically, transformers do not assume any fixed grid or locality structure—they are largely domain agnostic. With the right input encoding, the same transformer architecture can model language, images, audio, or other sequence data. Because of this, transformers can capture patterns that span the whole input (for example, the relationship between the beginning and end of a document, or between distant regions of an image) more naturally than CNNs.
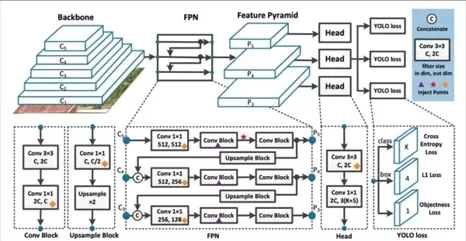
Advantages of Transformers
- Global Context Understanding: Suitable for tasks that require modeling long-range dependencies, transformers capture relationships between elements far apart in the input. For example, in an image, a transformer-based model can relate one corner of the image to the details on the opposite corner in one step.
- Parallelization: Transformers use matrix operations, which allow parallel processing of sequence elements. This makes transformers efficient for training on large datasets.
- Scalability: Transformers perform well when scaled with data and computational resources. In fact, many recent breakthroughs, such as large language models (LLMs), are simply large transformers trained on large datasets.
- Multi-Modal AI: The ability to integrate text, images, and more into unified models makes transformers domain agnostic, meaning they could be applied to applications beyond NLP, vision, audio etc. with minimal changes.
Limitations
- Data Requirements: Transformers require large datasets to learn and perform effectively, so a simpler model like a CNN might outperform a transformer in scenarios with limited data.
- Computational and Memory Demand: Transformers can be computationally intensive for long sequences or high-res images. They require significant memory to compute and store the weights. This can make transformers harder to deploy on edge devices.
- Interpretability: Less intuitive than CNNs regarding feature understanding like edge detection, transformer processing can feel like a black box, which can be a challenge in applications where interpretability is important.
Tensilica Vision DSPs: Accelerating CNNs and Transformers
As AI models grow in complexity, the need for efficient hardware becomes critical, especially on edge devices such as smartphones, cameras or even cars. Tensilica Vision DSPs are a family of highly optimized digital signal processors designed specifically for AI and vision workloads. They offer high-performance computing with power efficiency, making them suitable for a wide variety of edge devices.
Key Features of Tensilica Vision DSPs
- Specialized AI Engines: Tensilica DSPs support MAC (Multiply-Accumulate) operations, the core mathematical work in neural networks that is crucial for both CNN convolutions and transformer matrix multiplications.
- SIMD and VLIW Architecture: These DSPs use SIMD (Single Instruction, Multiple Data) and VLIW (Very Long Instruction Word), which enable parallel processing ability. This is ideal for the highly parallel nature of both CNNs and transformers.
- Custom Instruction Extensions: A standout feature is the ability to incorporate custom instructions like a 3x3 convolution or a dot-product for attention in a single operation, rather than many elementary steps. This results in a performance boost.
- Low Power, High Throughput: These DSPs are designed for edge AI applications where power efficiency is critical. They deliver high arithmetic throughput (many operations per second) while keeping energy consumption low.
- Support for Mixed Precision: Vision DSPs can leverage mixed-precision computing to speed up computation and save memory. These DSPs natively support INT8 and FP16, which are often sufficient for inference with minimal accuracy loss, as well as FP8 and FP8MX, which allow faster computation and smaller memory footprint while retaining good accuracy.
- Integrated DMA and Memory Hierarchy: Tensilica Vision DSPs feature an integrated DMA (Direct Memory Access) engine and a carefully designed memory hierarchy to efficiently move data efficiently with reduced latency.
With these features, Tensilica Vision DSPs enable on-device AI by providing the needed computational muscle. In practical terms, a Vision DSP might allow a smartphone to run a sophisticated neural network filter on images in real time (e.g. applying an AR effect or enhancing night photography), or an automotive camera to do instant object recognition for driver-assistance systems—tasks that would be too slow or power-intensive on a CPU alone. By offloading heavy math to the DSP, the overall system becomes faster and more efficient.
Customers requiring more acceleration and even higher performance for their AI workloads can pair their Vision DSP with Cadence’s Neo Neural Processing Unit (NPU), which is architected to maximize AI inference. Both are part of Cadence’s flexible and scalable AI IP solution, which also includes Tensilica HiFi DSPs for audio/voice applications, the Tensilica NeuroEdge 130 AI Co-Processor, and the NeuroWeave Software Development Kit (SDK), a single compiler for Cadence’s AI IP. The comprehensive Cadence AI IP solution can be tailored for different applications and performance requirements and is available in a variety of configurations, enabling customers to right-size their solution depending on their unique requirements.
Conclusion: Complementary Powerhouses
Despite their differences, CNNs and transformers are complementary tools in the AI toolbox. Each shines under different conditions, and increasingly, modern systems leverage both to get the best of both worlds. For example, in computer vision, there are hybrid models that use CNN components to first extract local features from images and then feed those into a transformer to capture global context—this combination can outperform either architecture alone, especially when data is limited or when the task requires understanding both detail and the big picture. Such hybrid approaches validate that CNNs and transformers can work in tandem, with CNNs providing a strong foundation in feature extraction while transformers add reasoning to those features.
Ultimately, the choice between a CNN and a transformer (or a hybrid) depends on the specific task, the available data, and the computational resources. Both architectures represent significant milestones in deep learning, pushing the boundaries of what AI can achieve in understanding and generating complex data. Capable hardware blocks such as Vision DSPs are key to unlocking the next generation of intelligent systems.
From IP to wafers and everything in between, Cadence is helping customers win, with a broad portfolio of compute and protocol IP, system and chiplet solutions, and the design services customers need to realize their silicon ambitions. Learn more about the Cadence AI IP portfolio and check out how Cadence.AI is transforming chip design.
Related Semiconductor IP
- HiFi iQ DSP
- 5G IoT DSP
- 5G RAN DSP
- Tensilica ConnX 120 DSP
- 32-bit 8-stage superscalar processor that supports RISC-V specification, including GCNP (DSP)
Related Blogs
- The Evolution of AI and ML- Enhanced Advanced Driver Systems
- MIPS and GlobalFoundries: Powering the Next Wave of Physical AI
- UEC-LLR: The Future of Loss Recovery in Ethernet for AI and HPC
- Pushing the Boundaries of Memory: What’s New with Weebit and AI
Latest Blogs
- Area, Pipelining, Integration: A Comparison of SHA-2 and SHA-3 for embedded Systems.
- Why Your Next Smartphone Needs Micro-Cooling
- Teaching AI Agents to Speak Hardware
- SOCAMM: Modernizing Data Center Memory with LPDDR6/5X
- Bridging the Gap: Why eFPGA Integration is a Managed Reality, Not a Schedule Risk