SynapticCore-X: A Modular Neural Processing Architecture for Low-Cost FPGA Acceleration
By Arya Parameshwara, Department of Electronics and Communication, PES University, Bangalore, India
Abstract
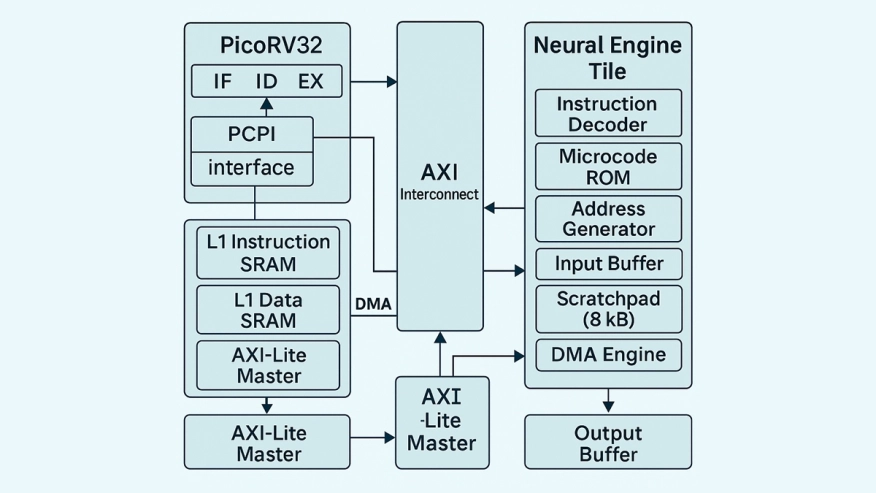
This paper presents SynapticCore-X, a modular and resource-efficient neural processing architecture optimized for deployment on low-cost FPGA platforms. The design integrates a lightweight RV32IMC RISC-V control core with a configurable neural compute tile that supports fused matrix, activation, and data-movement operations. Unlike existing FPGA accelerators that rely on heavyweight IP blocks, SynapticCore-X provides a fully open-source SystemVerilog microarchitecture with tunable parallelism, scratchpad memory depth, and DMA burst behavior, enabling rapid exploration of hardware-software co-design trade-offs. We document an automated, reproducible Vivado build pipeline that achieves timing closure at 100 MHz on the Zynq-7020 while consuming only 6.1% LUTs, 32.5% DSPs, and 21.4% BRAMs. Hardware validation on PYNQ-Z2 confirms correct register-level execution, deterministic control-path behavior, and cycle-accurate performance for matrix and convolution kernels. SynapticCore-X demonstrates that energy-efficient NPU-like acceleration can be prototyped on commodity educational FPGAs, lowering the entry barrier for academic and open-hardware research in neural microarchitectures.
To read the full article, click here
Related Semiconductor IP
- NPU
- NPU IP Core for Edge
- NPU IP Core for Mobile
- NPU IP Core for Data Center
- NPU IP Core for Automotive
Related Articles
- Finding the Right Processing Architecture for AES Encryption
- A Real-Time Image Processing with a Compact FPGA-Based Architecture
- Using parallel FFT for multi-gigahertz FPGA signal processing
- Revolutionizing AI Inference: Unveiling the Future of Neural Processing
Latest Articles
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks