3D IC 2-tier 16PE Multiprocessor with 3D NoC Architecture Based on Tezzaron Technology
D. Houzet 1, M.H Jabbar 1,2, O. Hammami 2
1 GIPSA Lab, Grenoble. 2 ENSTA ParisTech, Paris, France
Abstract :
In this paper, we describe the design flow, architecture and implementation of our 3D multiprocessor with NoC. The design based on 16 processors communicating using a 4x2x2 mesh NoC spread on two tiers is discussed in detail and will be fabricated using Tezzaron technology with 130 nm Global Foundaries low power standard library. The purpose of this work is to accurately measure NoC performances in real 3D chip when running mobile multimedia applications to evaluate the impact of 3D architecture compared to 2D.
I. INTRODUCTION
As moving to sub-nanometer transistor, design is very challenging. 3D integration is seen as an alternative to increase transistor density to meet high performance design without facing many problems as seen by scaling CMOS. By stacking dies or wafers, we can increase the performance because overall wirelength is reduced and so is power consumption. Stacking multiple dies will also reduce the total footprint of a chip making it very suitable for mobile devices. However, several challenges such as thermal and testing of 3D architectures need to be overcome before 3D technology can be implemented in consumer devices [1].
II. RELATED WORK
Many issues in 2D NoC architecture and design have been studied for the past several years such as design flow, implementation evaluation and design space exploration [2] [3] [4] [5]. However, 3D NoC architectural evaluation is limited as the technology is still under active research many organizations.
Despite performance evaluation of 3D architecture have been conducted using simulation [6] [7] [8], there is still a need for real 3D architecture implementation to accurately measure the performance as well as to validate the simulation results. Several 3D architectures have been designed and fabricated previously. T. Zhang et al developed a SoC architecture in 3D for H.264 application using Tezzaron technology [9]. Healy et al fabricated a multiprocessor architecture consisting of 64 cores with instruction memory in one layer and a total of 256 KB SRAM memory in another one layer. Buffer based architecture is used for inter processor communication [10]. Van Der Plas et al, Loi et al and Mineo et all have also demonstrated 3D architecture focusing on NoC architecture [11] [12] [13]. Their work focused on demonstrating the TSV use for inter die signalling as well as TSV characterization which is not our aim in this work.
Our objective is to design a 3D multiprocessor chip with 3D NoC architecture spread on multiple tiers (two here) and to measure the performances when running applications primarily for evaluating NoC communication in real 3D architecture. This is done also to validate the simulation of parallel applications in 3D NoC architecture. The design will be sent for fabricated through CMP [14].
III. ROUTER ARCHITECTURE
The router architecture is input buffered type as shown in Figure 1. It has 4 neighbouring ports, one vertical port for connecting to another tier and one local port to the processor. The network interface shown in Figure 2, connects processor to router through a FIFO port. Based on data address and number of words to be included in the packet, the network interface will access the processors data memory to process data blocks through DMA. Each network interface unit connects to processor through 2 FSL ports (FIFO); one master FSL for writing data to be transferred and the other one slave FSL for reading synchronization flags from other processors. The synchronization FIFO has 16 words (for 16 processors) and 5 bits wide. There is a 11 bits counter in the network interface unit for measuring packets travel timing. The timing information is included in the header flit attached when the packets enter the network as shown in Figure 3 and is processed when the packets arrive at the destination network interface.
Each input port has one buffer built using 16 words FIFO based dual port RAM architecture to support a maximum of 16 blocks data. As XY routing is deadlock free and we do not implement priority packets transfer, the virtual channel implementation is not useful. We use round robin arbitration for output port selection when there is more than one input requesting the same output route. Wormhole switching method is used for packet transfer in the NoC because it does not require large buffer and has lower latency. For the routing, deterministic coordinate based routing is implemented using XYZ coordinate. We use multiplexer based crossbar because it uses less area as well as less power compared with matrix crossbar. Each router has vertical port for connection to other router in the top tier using microbumps.
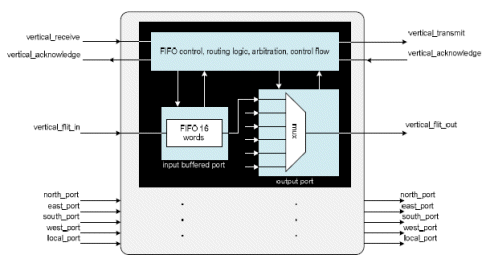
Figure 1: Router architecture
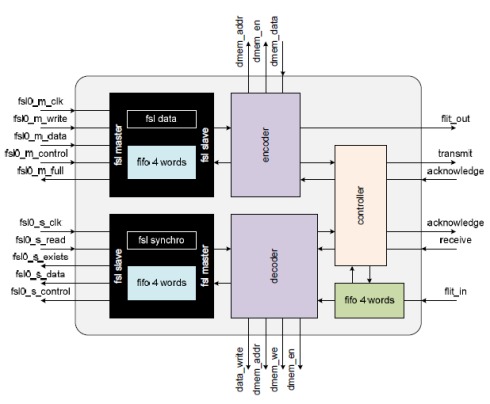
Figure 2: Network interface architecture
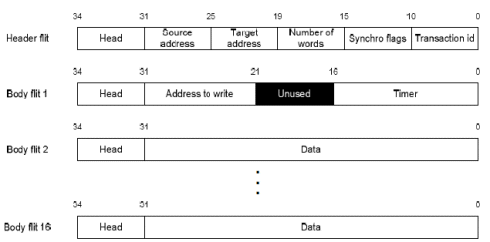
Figure 3: Packet format for the NoC
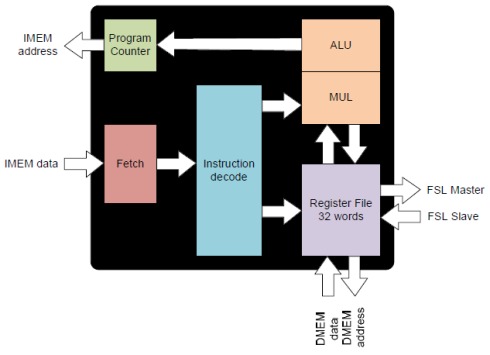
Figure 4: Openfire processor architecture
IV. PROCESSOR ARCHITECTURE
We use an open source processor for our implementation which is readily available without spending much time to develop a new processor. The Openfire processor as shown in Figure 4, is downloaded from Opencores.org [15]. It is a Microblaze clone which supports Microblaze ISA and compiler tool chain. It supports hardware multiplier only. Although there are other open source synthesizable Microblaze clones available, we choose Openfire because it has FSL ports (FIFO ports) that we need for simple data and synchronization communication between processors and NoC rather than using more complex interface such OCP and AXI which require complex logic. The Openfire processor is a simple processor developed for configurable processor research [16]. Thus, because of its simplicity, it will not require a large area and thus can be used to develop any small application for testing the NoC in 3D architecture. Also we use only 4 KB for instruction and 4KB for data memory in order to limit the die area. These memories are generated using Artisan memory compiler.
V. 3D 2 TIER 16PE MULTICORE
Our architecture as shown in Figure 6 consists of two face to face tiers. Each tier has 8 processors connected using 4x2 NoC using a mesh network. Connection in each tile block in shown in Figure 7. Connection between tiers is achieved using vertical ports of each router. Total tier to tier connection is 594 connections (35 bits flit data + 2 tx/rx signals + 2 JTAG signals for one direction vertical port router) for all 8 routers in one tier in two directions. Connections are made with 594 microbumps connecting the two face to face tiers. The microbumps are created from metal 6 layer of both tiers.
Synchronization between processors is implemented using FSL linked to the NoC. Processors communicate together through their data memory. A processor will synchronize before accessing its data memory by waiting for a tag word in its FSL sent by the writer processor. This is a simple synchronization hardware implementation in order to reduce die area.
In overall, our design fit into 4.5 mm x 3.5 mm die area for each tier. Target frequency for functional operation is 166 MHz (6 ns clock) and 10 MHz for test operation. The layout of bottom tier is shown in Figure 8 which is not much different from the top tier (without JTAG controller block).
We use an IEEE 1149.1 JTAG port for off chip interface. The JTAG controller is located at the bottom die and connected to outside chip using TSV under the I/O pad. Loading instruction and data memory for each processor is also using the JTAG port. Also the data memory of one processor (id 0) is connected outside in order to have fast access to results and be able to provide new input data.
The TSV technology from Tezzaron called FaStack is used here only for I/O pads made from Tungsten. It has 1.2 um diameter, 5 um pitch and 6 um depth. The two tier 3D stacking method is based on wafer to wafer bonding with via first approach shown in Figure 5. TSV liner is using Silicon Oxide to insulate from Silicon substrate. The wafer is bonded before thinning and thus there is no wafer handling required.
The design flow for 3D architecture design is based on 2D EDA tools as shown in Figure 9. The important step is specification where we decide the components for each tier. In this design we have the same architecture for both tiers except for the JTAG controller block. Each tier can be synthesized and placed and routed separately and thus can be done in parallel. During floorplanning stage, we need to capture the location of microbumps for inter tier connection such that we could connect the same signal to the same bump on the other tier with mirroring. Once the designs have been routed, we can integrate them in the Virtuoso environment for signoff 3D DRC and 3D LVS before submit to the foundry.
VI. CONCLUSION
We have described the architecture of our 3D multiprocessor with NoC architecture which will be sent for fabrication through CMP. The NoC architecture supports block data transfers for large data communication between processors. The 3D architecture comprises 16 processors split in two tiers connected using 4x2 NoC mesh network in each tier. Real measurements of applications running on 3D NoC can be performed after the chip is fabricated.
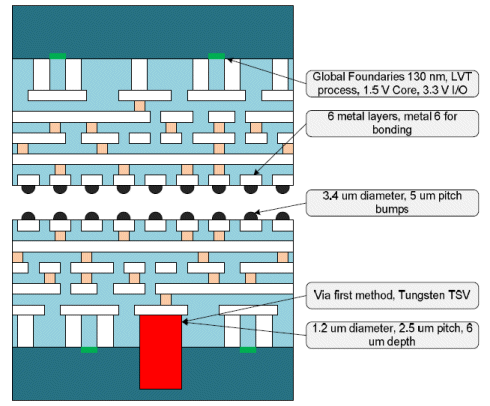
Figure 5: Tezzaron two tier technology
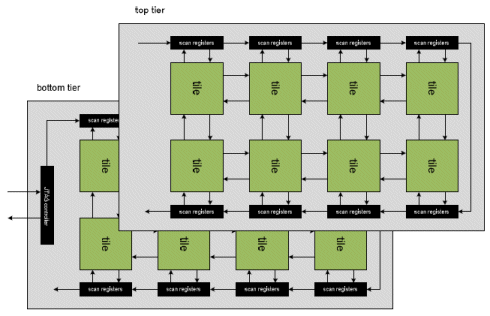
Figure 6: 2 tier 3D mutiprocessor architecture
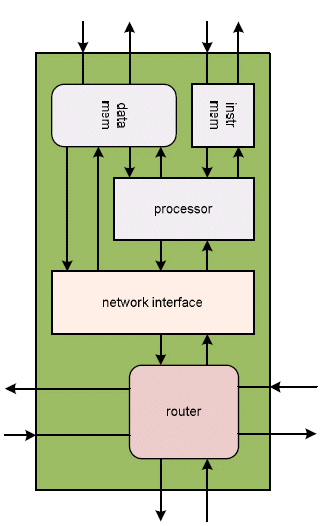
Figure 7: Tile block diagram
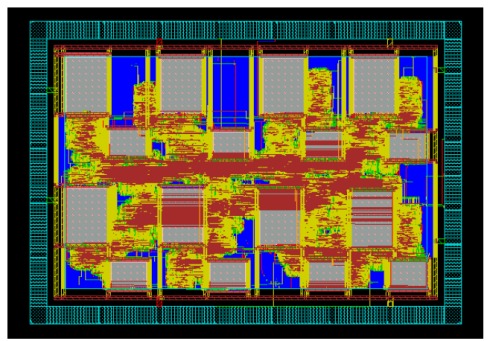
Figure 8: Bottom tier routed layout
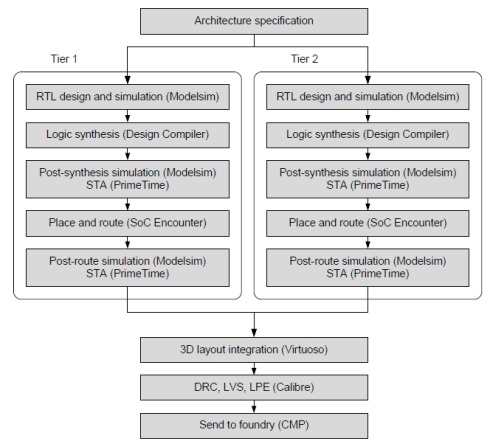
Figure 9: Design flow
REFERENCE
[1] R. S. Patti, Three-Dimensional Integrated Circuits and the Future of System-on-Chip Designs, Proceedings of the IEEE, 94 (2006), pp. 1214-1224.
[2] W. Yun Jie, D. Houzet and S. Huet, A Programming Model and a NoC-Based Architecture for Streaming Applications, Digital System Design: Architectures, Methods and Tools (DSD), 2010 13th Euromicro Conference on, 2010, pp. 393- 397.
[3] S. Evain, J. P. Diguet and D. Houzet, uspider: a CAD tool for efficient NoC design, Norchip Conference, 2004. Proceedings, 2004, pp. 218-221.
[4] L. Zhang, V. Fresse, M. Khalid, D. Houzet and A.-C. Legrand, Evaluation and Design Space Exploration of a Time-Division Multiplexed NoC on FPGA for Image Analysis Applications, EURASIP Journal on Embedded Systems, 2009 (2009).
[5] M. H. Jabbar and O. Hammami, Performance Analysis of a NoC-based 16PE Embedded Multicore: Processor Configuration Impact, International Design and Test, IDT 2010, IEEE, Abu Dhabi, 2010.
[6] V. F. Pavlidis and E. G. Friedman, 3-D Topologies for Networks-on-Chip, Very Large Scale Integration (VLSI) Systems, IEEE Transactions on, 15 (2007), pp. 1081- 1090.
[7] K. Nomura, K. Abe, S. Fujita, Y. Kurosawa and A. Kageshima, Performance analysis of 3D-IC for multi-core processors in sub- 65nm CMOS technologies, Circuits and Systems (ISCAS), Proceedings of 2010 IEEE International Symposium on, 2010, pp. 2876-2879.
[8] B. S. Feero and P. P. Pande, Networks-on- Chip in a Three-Dimensional Environment: A Performance Evaluation, Computers, IEEE Transactions on, 58 (2009), pp. 32-45.
[9] Z. Tao, W. Kui, F. Yi, C. Yan, L. Qun, S. Bing, X. Jing, S. Xiaodi, D. Lian, X. Yuan, C. Xu and L. Youn-Long, A 3D SoC design for H.264 application with on-chip DRAM stacking, 3D Systems Integration Conference (3DIC), 2010 IEEE International, 2010, pp. 1-6.
[10] M. B. Healy, K. Athikulwongse, R. Goel, M. M. Hossain, D. H. Kim, L. Young-Joon, D. L. Lewis, L. Tzu-Wei, L. Chang, J. Moongon, B. Ouellette, M. Pathak, H. Sane, S. Guanhao, W. Dong Hyuk, Z. Xin, G. H. Loh, H. S. Lee and L. Sung Kyu, Design and analysis of 3D-MAPS: A many-core 3D processor with stacked memory, Custom Integrated Circuits Conference (CICC), 2010 IEEE, 2010, pp. 1-4.
[11] G. Van der Plas, P. Limaye, I. Loi, A. Mercha, H. Oprins, C. Torregiani, S. Thijs, D. Linten, M. Stucchi, G. Katti, D. Velenis, V. Cherman, B. Vandevelde, V. Simons, I. De Wolf, R. Labie, D. Perry, S. Bronckers, N. Minas, M. Cupac, W. Ruythooren, J. Van Olmen, A. Phommahaxay, M. de Potter de ten Broeck, A. Opdebeeck, M. Rakowski, B. De Wachter, M. Dehan, M. Nelis, R. Agarwal, A. Pullini, F. Angiolini, L. Benini, W. Dehaene, Y. Travaly, E. Beyne and P. Marchal, Design Issues and Considerations for Low-Cost 3-D TSV IC Technology, Solid-State Circuits, IEEE Journal of, 46 (2011), pp. 293-307.
[12] I. Loi, P. Marchal, A. Pullini and L. Benini, 3D NoCs - Unifying inter and intra chip communication, Circuits and Systems (ISCAS), Proceedings of 2010 IEEE International Symposium on, 2010, pp. 3337-3340.
[13] C. Mineo, R. Jenkal, S. Melamed and W. R. Davis, Inter-die signaling in three dimensional integrated circuits, Custom Integrated Circuits Conference, 2008. CICC 2008. IEEE, 2008, pp. 655-658.
[14] Tezzaron Design Kit, CMP, http://cmp.imag.fr.
[15] Openfire Processor Core, (http://opencores.org/project,openfire_core).
[16] S. Craven, C. Patterson and P. Athanas, Configurable Soft Processor Arrays Using the OpenFire Processor, Proceedings of the 8th Annual Conference on Military and Aerospace Programmable Logic Devices, MAPLD 2005, COSMIAC, Washington D.C., 2005.
Related Semiconductor IP
- NoC System IP
- Non-Coherent Network-on-Chip (NOC)
- Coherent Network-on-Chip (NOC)
- High speed NoC (Network On-Chip) Interconnect IP
- Smart Network-on-Chip (NoC) IP
Related White Papers
- An HDTV SoC Based on a Mixed Circuit-Switched / NoC Interconnect Architecture (STBus/VSTNoC)
- Performance Measurements of Synchronization Mechanisms on 16PE NOC Based Multi-Core with Dedicated Synchronization and Data NOC
- Consumer IC Advances -> Altering algorithms to create '3D' sound
- Design of a C library for the implementation of 3D graphics applications on a SoC
Latest White Papers
- Ramping Up Open-Source RISC-V Cores: Assessing the Energy Efficiency of Superscalar, Out-of-Order Execution
- Transition Fixes in 3nm Multi-Voltage SoC Design
- CXL Topology-Aware and Expander-Driven Prefetching: Unlocking SSD Performance
- Breaking the Memory Bandwidth Boundary. GDDR7 IP Design Challenges & Solutions
- Automating NoC Design to Tackle Rising SoC Complexity