CXL Topology-Aware and Expander-Driven Prefetching: Unlocking SSD Performance
By Dongsuk Oh *, Miryeong Kwon *, Jiseon Kim *, Eunjee Na *, Junseok Moon *, Hyunkyu Choi *, Seonghyeon Jang *, Hanjin Choi *, Hongjoo Jung *, Sangwon Lee *, Myoungsoo Jung *†‡
* Next-Generation Silicon and Research Division, Panmnesia, Inc., Daejeon, South Korea
† Advanced Product Engineering Division, Panmnesia, Inc., Seoul, South Korea
‡ KAIST, Daejeon, South Korea
Abstract
Integrating compute express link (CXL) with SSDs allows scalable access to large memory but has slower speeds than DRAMs. We present ExPAND, an expander-driven CXL prefetcher that offloads last-level cache (LLC) prefetching from host CPU to CXL-SSDs. ExPAND uses a heterogeneous prediction algorithm for prefetching and ensures data consistency with CXL.mem’s back-invalidation. We examine prefetch timeliness for accurate latency estimation. ExPAND, being aware of CXL multi-tiered switching, provides end-to-end latency for each CXL-SSD and precise prefetch timeliness estimations. Our method reduces CXL-SSD reliance and enables direct host cache access for most data. ExPAND enhances graph application performance and SPEC CPU’s performance by 9.0× and 14.7×, respectively, surpassing CXL-SSD pools with diverse prefetching strategies.
Introduction
Compute Express Link (CXL) is emerging as a key interface for enabling memory disaggregation, where memory resources are decoupled from computing servers to provide scalable access to largecapacity memory [1–3]. This shift is particularly relevant as storage class memory (SCM) technologies, such as PRAM [4], Z-NAND [5], and XL-Flash [6], offer significant capacity advantages compared to DRAM. SCM’s ability to store large datasets with byte-addressable access makes it an attractive candidate for new memory systems. As a result, both industry and academia are exploring the potential of byte-addressable solid-state drives (SSDs) that leverage the CXL protocol to combine SCM’s memory semantics with scalable interconnects. For example, one approach integrates CXL into Optane SSDs to extend memory hierarchies, while several proof-of-concepts (PoCs) are building CXL-SSDs using advanced flash memory technologies like Z-NAND and XL-Flash [7–9].
Despite the potential of CXL-SSDs for addressing the increasing demand for memory capacity, the underlying SCM technologies remain significantly slower than DRAM. PRAM, for instance, has been shown to exhibit access latencies up to 7× higher than DRAM [10], while Z-NAND and XL-Flash introduce latencies that are approximately 30× slower [5]. To mitigate these, many designs incorporate SSD-side DRAM buffers as internal caches, mimicking the architecture of high-performance NVMe storage equipped with substantial internal DRAM [11–13]. These buffers are effective in reducing write latency but are insufficient to address the long read latencies caused by slow SCM backend media.
Addressing read latency in CXL-SSDs requires a departure from traditional SSD design principles. Unlike conventional block devices managed by file systems [14, 15], CXL-SSDs directly serve memory requests using load/store operations, bypassing the host-side storage stack. This fundamental shift necessitates understanding the execution patterns of host applications and managing the CPU cache hierarchy to align with the unique performance characteristics of CXL-SSDs. However, current SSD technologies have largely been designed to handle block-level requests, leaving them ill-equipped to address the challenges associated with high-latency memory requests [14]. As a result, there remains a pressing need for solutions that can bridge this gap, ensuring that CXL-SSDs can fully realize their potential in emerging memory disaggregation architectures.
When CXL-SSDs are integrated into the system memory space as host-managed device memory, existing CPUside cache prefetching mechanisms can still provide some performance benefits. However, two primary challenges limit the effectiveness of current prefetchers within the cache hierarchy in fully exploiting the advantages of the last-level cache (LLC) for CXL-SSDs: i) hardware logic size constraints that hinder the handling of diverse memory access patterns encountered in the CXL memory pooling space, and ii) latency variations caused by the differing physical positions of CXL-SSDs within the CXL switch network.
Rule-based cache prefetchers, such as spatial [16–18] and temporal algorithms [19–21], often require tens of This manuscript is an extended version of the original paper accepted by IEEE Micro. megabytes of storage—comparable to the size of a typical CPU last-level cache (LLC). Due to these high storage requirements, modern CPUs employ simpler prefetching algorithms, such as stream cache prefetchers [22]. While these are efficient in hardware implementation, they are insufficient to mask the increased latency introduced by CXL-SSDs.
An additional complication arises from the interconnect topology used in CXL-based memory disaggregation. To enable scalable memory expansion, CXL employs a multilevel switch architecture, where each switch level introduces a processing delay. The cumulative latency depends on the position of the target device within the switch network, with deeper levels resulting in higher delays. This latency variation prevents existing prefetchers from retrieving data from CXL-SSDs distributed across the network. The inability to account for such latency differences further exacerbates the challenge of achieving consistent performance across the disaggregated memory space [23].
This paper presents an expander-driven CXL prefetcher, ExPAND, designed to offload primary LLC prefetching tasks from the host CPU to CXL-SSDs, addressing CPU design area constraints. Implemented within CXL-SSDs, ExPAND employs a heterogeneous machine learning algorithm for address prediction, enabling data prefetching across multiple expander accesses. The host-side logic in ExPAND ensures that CXL-SSDs remain aware of the execution semantics of host-side CPUs, while the SSDside logic maintains data consistency between the LLC and CXL-SSDs using CXL.mem’s back-invalidation (BI) mechanism. This bidirectional collaboration allows user applications to access the majority of data directly at the host, thereby significantly reducing reliance on CXL-SSDs for frequent memory requests.
Accurate estimation of prefetching latency is essential for optimizing the limited capacity of on-chip caches. To address this, we define the concept of prefetch timeliness, representing the latency constraints inherent to CXL-based prefetching. ExPAND incorporates a detailed understanding of prefetch timeliness by identifying the CXL network topology and device latencies during PCIe enumeration and device discovery. Using this topology information, ExPAND calculates precise end-to-end latency values for each CXLSSD within the network and writes these values into the PCIe configuration space of each device. This information enables the offloaded cache prefetching algorithm to determine the optimal timing for transferring data to the host LLC, effectively mitigating the long read latencies caused by the slower backend media of CXL-SSDs.
Our evaluation results show that ExPAND enhances graph application performance and SPEC CPU’s performance by 9.0× and 14.7×, respectively, surpassing CXLSSD pools with diverse prefetching strategies.
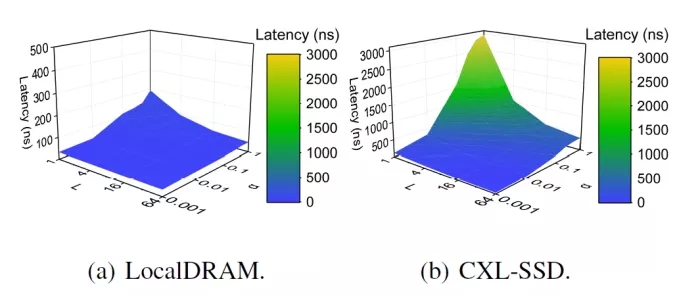
FIGURE 1: Analyzing the impact of locality.
BACKGROUND
Memory Pooling using CXL
Protocol primary. CXL is a cache-coherent interconnect designed for heterogeneous devices, enabling scalable memory expansion. It consists of three sub-protocols: CXL.io, CXL.cache, and CXL.mem. Built on the PCIe physical layer, CXL.io functions as a direct counterpart to the PCIe protocol. CXL.cache facilitates efficient access to host memory for accelerators, while CXL.mem enables hosts to access memory attached to devices across the CXL network. Together, CXL.io and CXL.mem support the connection of multiple memory expanders to create large-scale memory pools. Note that memory expanders can connect to the host system memory without requiring CXL.cache, appearing to CPUs as locally-attached memory. This is possible because CXL allows endpoint (EP) devices to be mapped into the cacheable memory space [1, 24–26].
Incorporating CXL into storage. CXL.mem and CXL.io allow CPU to access memory via load/store instructions, using a CXL message packet called a flit. This flit-based communication enables various memory and storage media to be integrated into the CXL pool. SCMs having greater capacity than DRAM is leading to an interest in integrating CXL into block storage, known as CXL-SSDs. CXL-SSDs often use large internal DRAM caches to store data ahead of backend SCMs, achieving performance akin to DRAMbased EP expanders. Samsung’s PoC employs Z-NAND and a 16GB DRAM cache, claiming an 18× write latency improvement over NVMe SSDs [27]. Kioxia’s PoC uses XL-Flash and a sizable DRAM prefetch buffer, asserting DRAM-like speeds by combining prefetching with hardware compression [6].
Go Beyond Pooling
Enhanced memory coherence. CXL’s flit-based communication decouples memory resources from processor complexes, enabling efficient memory pooling. However, while CXL.cache provides cache coherence, it imposes considerable overhead on EP devices when managing their internal memory. When a CXL-SSD employs CXL.cache to synchronize host-side cache updates, frequent monitoring and approval for memory accesses targeting internal DRAM or backend SCM are required to maintain coherence. To address this, the back-invalidation (BI) introduced by CXL 3.0 enables CXL.mem to back-snoop host cache lines [28]. This feature allows EPs, such as CXL-SSDs, to autonomously invalidate host cache lines, reducing dependence on CXL.cache while maintaining coherent memory states.
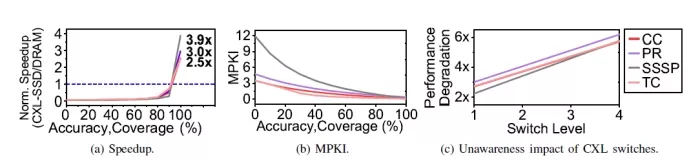
FIGURE 2: CXL-SSD prefetching performance analysis.
Multi-tiered switching. EP expanders within a pool are interconnected via one or more CXL switches. Each CXL switch consists of upstream ports (USPs) and downstream ports (DSPs), allowing connections between CPUs and EP expanders. A fabric manager (FM) configures and manages these ports, enabling each host to access its EP expanders through a dedicated data path known as a virtual hierarchy (VH). Previously, CXL architectures were restricted to a single switch layer, which limited the capacity of each VH. With the introduction of multi-tiered switching in CXL 3.0/3.1, switch ports can now connect to additional switches, significantly increasing the capacity of each VH. This enhancement supports up to 4K devices per VH and accommodates various CXL sub-protocols, greatly improving scalability for resource disaggregation [29].
MOTIVATION AND CHALLENGES
Prefetching Impact Analysis
Locality impact. Figures 1a and 1b illustrate the latency behavior of locally-attached DRAM (LocalDRAM) and CXL-SSDs under varying levels of locality. A global data access benchmark [30] is used to synthetically adjust locality levels and evaluate their impact. In this study, L represents the vector length, reflecting spatial locality, while α quantifies temporal locality. An α value of 1 corresponds to minimal locality (purely random access), whereas smaller values indicate greater temporal locality. This approach captures the range of potential performance outcomes and highlights the influence of the cache hierarchy. The test environment remains consistent with that described in the “EVALUATION” section, ensuring comparability across all analyses.
In low-locality scenarios (α = 0.1 ∼ 1 and L = 4 ∼ 16), CXL-SSD performance is, on average, 738% slower than that of LocalDRAM, a disparity deemed unacceptable in many computing contexts. However, as locality improves, the average latency of CXL-SSDs approaches that of LocalDRAM. At high levels (α ≤ 0.01 and L ≥ 16), the performance gap narrows significantly, with CXL-SSD being only 35% slower than LocalDRAM on average. This improvement is due to data being predominantly retrieved from the LLC rather than backend SCMs. Note that, unfortunately, existing CXL-SSD studies have largely overlooked this behavior, focusing instead on optimizing internal DRAM cache utilization. While effective use of internal DRAM caches is essential for mitigating longtail latency under low-locality conditions, we argue that improving cache hit rates is equally critical for enhancing user experience with CXL-SSDs.
Prefetching impact. The performance impact and effectiveness of prefetching are influenced by two parameters [16]: prefetch accuracy and prefetch coverage. Prefetch accuracy is the proportion of prefetched data actually utilized by the target application, while prefetch coverage measures the fraction of total memory requests served by prefetched data.
Figure 2a shows the latency speedup achieved by applying prefetching techniques in CXL-SSD systems, normalized to the latency of LocalDRAM. The graph demonstrates the relationship between prefetch effectiveness and latency improvements in graph applications. Both parameters were configured with identical values, varying from 0% to 100%, to evaluate their combined impact on system behavior. This analysis uses four representative large-scale graph workloads sourced from [31], with further details provided in the “EVALUATION” section.
The results indicate that CXL-SSD performance is significantly slower than LocalDRAM, with up to 4.5× slower latency when prefetch effectiveness is below 80%. However, performance improves substantially as prefetch effectiveness increases. Once prefetch effectiveness exceeds 90%, the increased cache hit rate reduces the frequency of actual memory accesses, leading to notable latency This manuscript is an extended version of the original paper accepted by IEEE Micro. 3 reductions. While unrealistic, a perfect prefetch allows the CXL-SSD to outperform LocalDRAM, improving latency from 2.5× to 3.9×.
To better understand the performance improvements by prefetching, we analyze the LLC misses per kilo instructions (MPKI) for each workload, as shown in Figure 2b. MPKI increases in the order of CC, TC, PR, and SSSP, and the degree of performance improvement corresponds to this order. Specifically, prefetching significantly reduces the memory stall times of SSSP, which is associated with 12 MPKI, resulting in a 3.9× improvement in application performance. This improvement occurs because the prefetcher prepares data both accurately and in a timely manner, allowing the CPU to perform tasks without being stalled by memory latency. Consequently, improving prefetcher effectiveness not only delivers nonlinear performance gains but also enables speedups that surpass those achievable with conventional DRAM-based systems. However, realizing such performance improvements requires the design of a prefetcher with high effectiveness, emphasizing both accuracy and coverage.
Latency Variation with CXL Switch Topology
Unawareness impact of CXL switches. Even an prefetcher is designed towards having high effectiveness, it cannot fully mitigate performance degradation caused by latency variation in multi-tiered switching environments. Specifically, conventional prefetchers fail to account for the additional latency introduced by CXL switches, resulting in data being unavailable when needed by the CPU. Consequently, memory requests that should result in cache hits are converted into cache misses.This limitation reduces the effectiveness of the prefetcher in CXL systems, leading to performance degradation.
To evaluate how a multi-tiered CXL switch architecture affects application performance, we incrementally increased the number of CXL switch layers from 1 to 4 and measured the resulting performance degradation relative to a baseline system without any switches between the host and CXLSSD. For consistency in analyzing performance trends, we assumed a prefetch effectiveness of 90%, representing the median value in the rapidly changing effectiveness range in Figure 2a.
Figure 2c shows that the four graph workloads (CC, PR, TC, SSSP) experienced a 2.7× performance degradation per additional CXL topology switch layer in average. The slope of each workload graph reflects the performance degradation, where CC, PR, and TC shows 1.3× degradation per switch layer, whereas SSSP shows 1.4× per layer. The observed performance trends align with the prefetch-induced improvements shown in Figure 2a and the relationship between performance and MPKI depicted in Figure 2b. Workloads that benefit significantly from prefetching typically exhibit reduced execution times, making them more sensitive to switch-induced latency caused by cache misses. This suggests that workloads highly reliant on prefetching are disproportionately affected by the latency introduced by multi-tiered switches in the CXL topology.
To mitigate the performance losses associated with increasing switch layers, it is essential to design prefetchers that can adapt to latency variations introduced by the CXL switch hierarchy. Such designs would help preserve the benefits of prefetching even in multi-tiered CXL architectures.
Expander-Driven Prefetching
CPU-side rule-based spatial [16–18] and temporal [19– 21] prefetchers have been adopted in various industrial processors. However, their accuracy is limited (9% to 76%) for workloads with large-scale, irregular, or random memory access patterns, insufficient to accelerate CXL-SSD performance to match Local DRAM levels (e.g., 90% accuracy). To address these limitations, more advanced prefetching techniques incorporating machine learning (ML) approaches have been proposed [32–41]. Prefetching involves prediction, making ML-based approaches promising for higher accuracy. While these techniques could achieve the required accuracy threshold, they remain impractical for onchip CPU implementation due to substantial storage requirements for model computation and metadata management overhead [39–41].
On the other hand, techniques to minimize the memory overhead of ML-based prefetching algorithms have also been proposed [40, 41]. Unfortunately, these methods either require profiling-based offline training using workload memory traces, thus limiting their effectiveness for accelerating unseen workloads [40], or utilize knowledge distillation and product quantization techniques to reduce memory requirements, resulting in low accuracy and high training complexity [41]. In addition, existing prefetching algorithms are unaware of multi-level switch architectures, thus unable to account for latency variations inherent in CXL topology.
Prefetching Delegation and Collaboration
This paper introduces an expander-driven prefetcher (Ex- PAND) that delegates cache prefetching decisions to CXLSSDs, enabling autonomous CPU cache line updates. By shifting decision-making to the EP side, ExPAND leverages the larger form factor and computational capabilities of SSD EPs versus on-chip CPUs. Figure 3a presents ExPAND’s architecture, which comprises two key components: the reflector and the decider.
The reflector is implemented on the host-side CXL root complex (RC) and LLC controller. Its main role is to provide the decider with essential decision-making inputs like program counter (PC) and switch depth of connected CXLSSD. It also communicates the cache prefetching results determined by the decider. To support this, the reflector uses a small buffer (16 KB) to log cache line updates prefetched by the decider. The reflector ensures efficient data delivery by enabling each host’s LLC controller in the CXL network to first check the buffer. If the required data is present in the CXL RC, the LLC controller directly serves the data from the buffer, avoiding unnecessary traversal through the CXL-SSD pool.
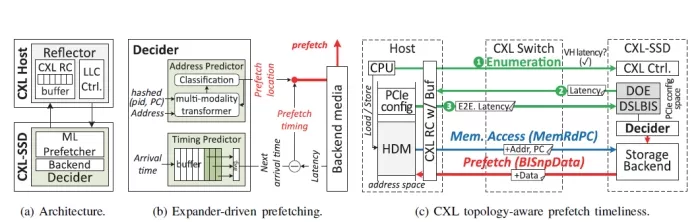
FIGURE 3: Overview of ExPAND.
On the other hand, the decider resides in the EPside CXL-SSD controller, implements a heterogeneous ML prefetcher optimized for irregular memory access patterns [33]. Using the provided inputs (PC and memory address), the decider identifies and transfers data to the reflector buffer. In addition, the decider records the input data for online refinement of prefetching patterns. Detailed explanations of the prefetcher’s operation and the interaction mechanisms between the reflector and decider are provided shortly.
Prefetch Address and Timing Speculation
As shown in Figure 3b, ExPAND’s decider incorporates two specialized predictors: an address predictor and a timing predictor, responsible for determining the location and timing of cache prefetch operations, respectively. The address predictor is inspired by a multi-modality transformer model [33], while the timing predictor employs a simpler rule-based approach. The address predictor generates a sequence of memory addresses for prefetching by utilizing a transformer as its sequence model. It integrates a multimodality attention network [42] to enhance the analysis of relationships between memory access patterns and PC. In addition, it monitors changes in application execution behavior using a decision tree classifier [43] to dynamically refine prefetching accuracy.
ExPAND’s decision tree classifier is pretrained to categorize memory traces of various applications into 64 categories. For online inference, ExPAND maintains a sliding window containing recent memory addresses and their corresponding PCs, feeding this information to the classifier model. The classifier infers the current window’s requests into one of the pretrained 64 categories. If the classifier’s inference changes from the previously inferred category, ExPAND records this as a behavior-change event. Such events are then provided as hints, along with memory addresses, to the multi-modality transformer model. By recognizing these behavior-change events, the transformer model achieves more accurate predictions of subsequent addresses. This detection-based feedback allows the transformer model to respond promptly to changes in memory access patterns.
The timing predictor, in contrast, maintains request arrival time information in a small-sized buffer (80B) and estimates future memory request times by averaging historical arrival times within its history window. Accurate prediction requires retaining all past arrival times in the history window. However, when memory requests are served directly by the LLC, relevant information may not reach the timing predictor. To address this, the reflector notifies the decider of cache hit events via CXL.io, enabling the timing predictor to account for future request times even when no direct requests are observed.
The actual prefetch timeliness is determined by combining the timing predictor’s results with each device’s latency variation. A detailed discussion of the prefetch timeliness estimation process is provided in the “CXL Topology-Aware Prefetch Timeliness” section.
CXL CROSS-LAYER INTERSECTION
CXL Topology-Aware Prefetch Timeliness
CXL switch hierarchy discovery. The reflector effectively identifies the switch level of CXL-SSDs during PCIe enumeration. The host accesses the configuration space of connected devices (using CXL.io) and organizes system buses within their CXL network. During enumeration, buses are segregated upon identifying new devices, with unique number is assigned to each bus. As CXL switch operates as PCIe bridge device with distinct bus number, it allows determining the number of switches between a host CPU and target CXL-SSD. The reflector stores this information on its RC side, which aids in estimating accurate prefetch timeliness, detailed below.
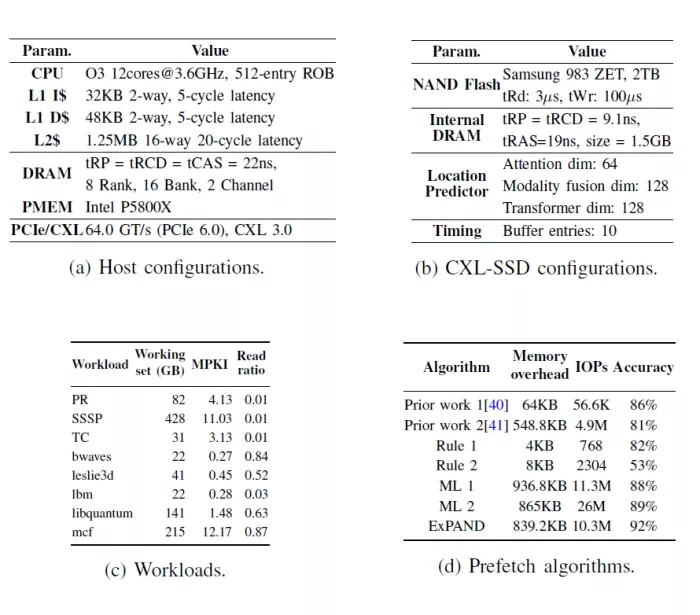
TABLE 1: Evaluation setup.
Timeliness speculation. Prefetching data too early could contaminate the LLC, reducing its hit ratio, while prefetching too late may delay execution. Therefore, pinpointing exact prefetch timeliness is essential. Figure 3c shows this process. Since CXL EPs must manage data object exchange (DOE) capability in PCIe configuration space, each CXLSSD can determine its device latency through DOE. However, this latency cannot directly estimate prefetch timeliness due to variations from multi-tiered switching. During enumeration, the reflector retrieves each CXL-SSD’s latency by extracting device scoped latency and bandwidth information structure (DSLBIS) from DOE. It then calculates the latency overhead incurred in VH between RC and target CXL-SSD. The reflector combines this VH latency with the DSLBIS latency and stores the end-to-end latency in the corresponding device’s configuration space. Consequently, the decider estimates prefetch timeliness by subtracting the end-to-end latency from the time predicted by its timing predictor.
Bidirectional Communication on CXL
Downward: piggybacking on CXL.mem. To accurately predict addresses, timely transmission of PCs and corresponding memory requests is vital. CXL.mem’s masterto- subordinate (M2S) transactions include request without data (Req), request with data (RwD), and back-invalidation response (BIRsp). Req is primarily for memory read opcode (MemRd) without payload, while RwD carries payload for memory write opcode (MemWr). RwD allows 13 custom opcodes, enabling an opcode for memory reads with PCs (MemRdPC). When a read misses the LLC, the reflector sends an M2S transaction using MemRdPC, including the current PC. Consequently, the target decider can access the memory address and PC in the host’s execution environment. Note that BIRsp responds to the CXL-SSD’s BI snoop command, discussed shortly.
Upward: leveraging BI. When it reaches the time to prefetch (estimated in the “CXL Topology-Aware Prefetch Timeliness” section), the decider must update the reflector buffer with data obtained from its address predictor results. However, the existing CXL.mem lacks the capability to update host-side on-chip storage. To address this limitation, we use the CXL.mem subordinate-to-master (S2M) transaction’s BISnp. BISnp, similar to CXL.mem’s Req, is a nonpayload message. We introduce a new BI opcode, termed BISnpData, to the S2M transaction message, allowing up to 10 custom opcodes. Using BISnpData, the decider generates a payload accompanying its message, containing data for updating the host. When the reflector detects BISnpData, it awaits the corresponding payload and inserts the prefetched data into its buffer, enabling the LLC controller to fetch it for execution.
EVALUATION
Methodologies. Since no CXL-SSDs are currently available, we use CXL hardware RTL modules in a full system simulation model. We conduct this simulation using gem5 [44] and SimpleSSD [45]. These CXL RTL modules have been validated using a real CXL end-to-end system at the cycle-level [46]. Table 1 provides the main parameters of our simulation. We compare ExPAND, our proposed expander-driven prefetcher, with several modern rule-based and ML-based prefetchers. These include a spatial prefetcher [16] (Rule1), a temporal prefetcher [19] (Rule2), an LSTM-based prefetcher [39] (ML1), and a transformer-based prefetcher [32] (ML2). We summerize the important characteristics of each prefetching algorithm in Table 1d.
Workload and benchmarks To evaluate the effectiveness of ExPAND in diverse graph application scenarios, we employ four widely used algorithms across five datasets. The algorithms, sourced from established graph processing frameworks, include Connected Components (CC), PageRank (PR), Single Source Shortest Path (SSSP), and Triangle Counting (TC). These are applied to five datasets: Amazon’s product co-purchasing network, Google’s web graph, the California road network, the Wikipedia talk network, and the YouTube online social network. We also summarize key characteristics of each workload in Table 1c.
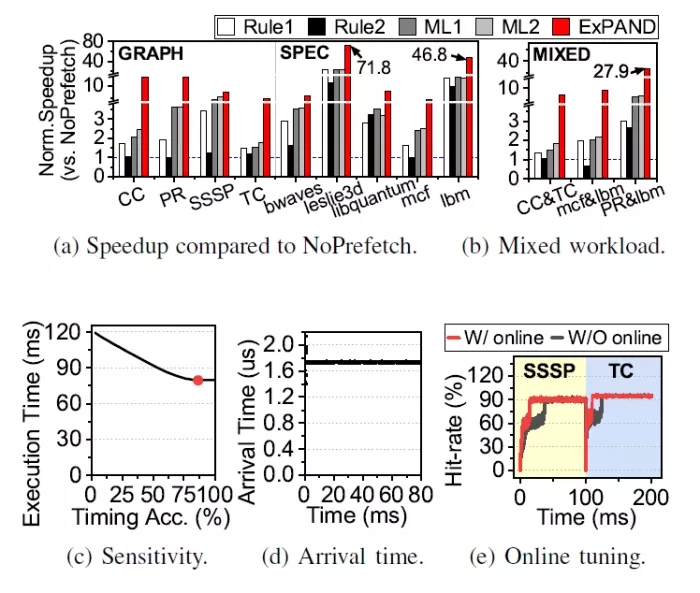
FIGURE 4: Overall performance.
Overall Analysis of Prefetching
We evaluate all five prefetching techniques (Rule1, Rule2, ML1, ML2, and ExPAND) across the graph workloads and SPEC CPU benchmarks. For clarity, we normalize their performance relative to NoPrefetch, representing a CXL-SSD without prefetching. Figure 4a analyzes the speedup of the five prefetching techniques normalized to NoPrefetch.
Rule-based prefetcher. In graph applications, Rule1 achieves a performance improvement over NoPrefetch and Rule2 by 2× and 1.8×, respectively. This enhancement occurs because graph applications typically exhibit significant spatial locality, making data accesses easier for prefetchers to predict compared to temporal patterns. In contrast, performance varies across SPEC CPU benchmarks. Workloads with high MPKI (e.g., mcf) still perform comparably to NoPrefetch. However, workloads exhibiting structured, repetitive memory access patterns achieve an average speedup of 7×.
ML-based prefetcher. ML-based prefetchers achieve performance improvements of 1.6× over rule-based prefetchers and 4.4× over NoPrefetch. This gain is attributed to their ability to effectively learn complex spatial and temporal locality patterns. ExPAND, our proposed multi-modality transformer-based prefetcher, further outperforms existing ML-based prefetchers by 2.4×, achieving speedups ranging from 4.3× up to 71.8× over NoPrefetch. ExPAND particularly excels in workloads dominated by stencil computations, such as bwaves, leslie3d, and lbm. Stencil computations typically involve referencing neighboring data points across multiple dimensions.
Performance with mixed workloads. Figure 4b illustrates the execution time results under mixed workload scenarios, where each core simultaneously runs distinct workloads. The performance of existing prefetching algorithms (Rule1, ML1, and ML2) significantly degrades under mixed workloads due to reduced accuracy in predicting subsequent memory addresses resulting from intertwined memory access patterns. An exception is Rule2, which preprocesses memory accesses by grouping addresses with similar values. Consequently, Rule2 maintains relatively high performance when workloads with strong spatial locality (e.g., CC & TC) are combined.
In contrast, ExPAND employs a multi-modality transformer model considering both PC and memory addresses, enabling it to effectively distinguish between memory access patterns even under mixed workloads. Therefore, under mixed workloads, ExPAND outperforms Rule1, Rule2, ML1, and ML2 by averages of 7.0×, 10.2×, 3.7×, and 3.5×, respectively.
Model optimizations. We further evaluate ExPAND’s prefetching optimizations, particularly its timeliness model and online tuning mechanisms. ExPAND’s timeliness model considers backend media latency of CXL expansion devices and multi-layer switch latency, enabling efficient utilization of limited LLC resources.
Figure 4c shows workload performance relative to the accuracy of the timeliness model, evaluated using the TC workload. As shown, improved timeliness accuracy directly correlates with reduced execution time. Low accuracy leads either to early prefetching – causing prefetched data to be evicted before usage – or delayed prefetching, resulting in data being unavailable when required. Performance gains begin saturating at around 68% timeliness accuracy, with marginal improvements beyond 84%. This saturation occurs because LLC associativity typically mitigates eviction issues arising from minor timing inaccuracies.
ExPAND’s timeliness model achieves 90% accuracy, significantly improving workload performance. Despite being heuristic-based, this high accuracy is achievable since LLC access frequencies remain relatively constant during workload execution. Figure 4d illustrates the intervals between LLC accesses during execution of the TC workload. As seen, LLC access frequency remains stable at runtime, influenced primarily by the workload’s inherent memory access frequency and randomness, both of which typically remain constant throughout execution.
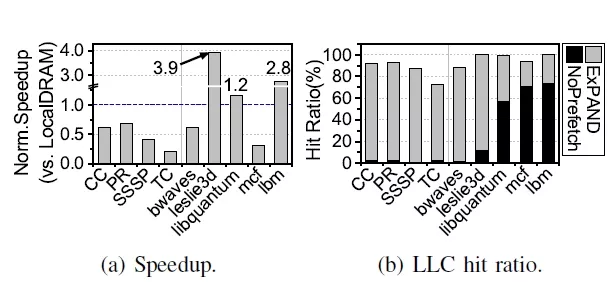
FIGURE 5: Performance comparison with local DRAM.
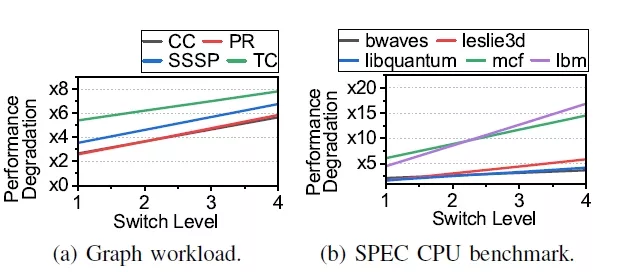
FIGURE 6: Impacts of timeliness.
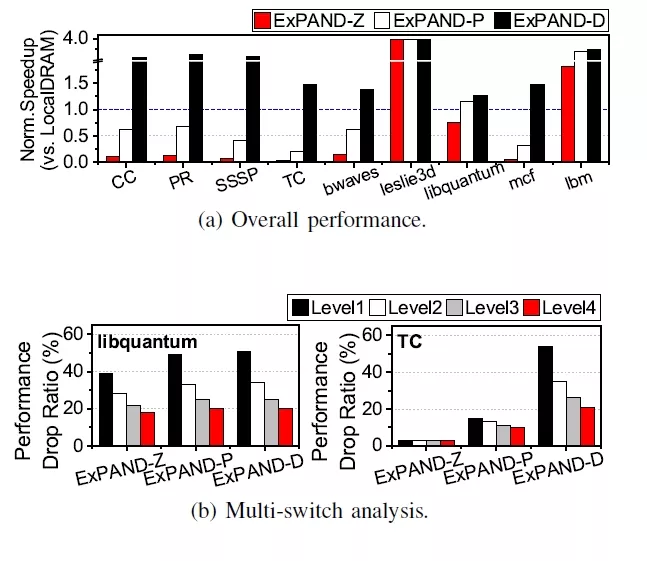
FIGURE 7: Impacts of backend media.
Performance gain. Figure 4e analyzes the performance gains from ExPAND’s online tuning. The evaluation measures LLC hit rates in scenarios with and without online tuning, focusing on dynamic workload transitions. Two workloads, SSSP and TC, were chosen due to their contrasting memory access patterns – SSSP has sequential accesses, whereas TC involves large-stride patterns.
The results show that online tuning enables significantly faster recovery of LLC hit rates following behavioral changes in workloads. Without tuning, the transformer model struggles to quickly adapt due to reliance on patterns from a large historical window, making it difficult to detect sudden changes. In contrast, ExPAND’s decision tree classifier rapidly identifies changes in workload behavior, immediately notifying the transformer model. Consequently, the transformer adjusts swiftly by prioritizing recent memory accesses.
Performance Comparison with Local DRAM.
In the previous subsection, we analyze the performance improvements from expander-driven prefetching on CXLSSD. Here, we evaluate its practical effectiveness during application execution. For this analysis, we compare Ex- PAND, the most effective prefetching technique, against a baseline using only local DRAM (LocalDRAM).
Impacts of prefetching. Figure 5a shows the normalized performance of ExPAND against LocalDRAM in terms of application execution time. To better understand the performance gap, we also measure the LLC hit ratio, illustrated in Figure 5b. The NoPrefetch percentage reflects the baseline LLC hit ratio without prefetching, while ExPAND highlights the additional improvements achieved through prefetching. ExPAND delivers a 9.0× performance improvement over NoPrefetch across four graph workloads.
However, compared to the LocalDRAM baseline, it shows a 48% performance degradation due to the 14% cache miss rate, which required accessing CXL-SSD. Consequently, application execution is delayed despite ExPAND achieving an 86% LLC hit rate. In contrast, SPEC benchmarks such as leslie3d, libquantum, and lbm demonstrate 3.9×, 1.2×, and 2.8× performance improvements over LocalDRAM, respectively. This improvement is driven by ExPAND’s ability to increase the LLC hit ratio by 46% on average, achieving hit rates as high as 96% for theses workloads.
Impacts of timeliness. We conduct a sensitivity evaluation by incrementally increasing the VH level of the CXL switch from 1 to 4 to understand the impact of latency variation with topology. Figure 6a and Figure 6b show the impact of increasing switch levels on performance for each workloads. The performance trends align with the LLC hit ratio in 5b. Applications with high ExPAND-driven cache hit rates experience significant performance degradation at switch level 1 due to prefetchers that are unaware of the CXL topology, leading to reduced prefetch effectiveness. Conversely, workloads with higher NoPrefetch LLC hit ratios experience steeper degradation as levels increase, as added switch latency affects applications that had benefit from high LLC hit rates. Graph workloads (Figure 6a) show consistent degradation, averaging a 1.2× slowdown. SPEC CPU benchmarks (Figure 6b) exhibit varied slowdowns reflecting different sensitivities to switch latency.
Diversity of Backend Media
To evaluate the impact of backend media on expanderdriven prefetching and application execution time, we conducted experiments with Z-NAND, PMEM, and DRAM as backend media options. These configurations are referred to as ExPAND-Z, ExPAND-P, and ExPAND-D, respectively. ExPAND-Z and ExPAND-P were tested to examine the feasibility of using Z-NAND and PMEM as main memory, while ExPAND-D was analyzed to explore the maximum potential benefits of expander-driven prefeching.
Impacts of prefetching. Figure 7a presents the execution times of graph workloads and SPEC benchmarks using memory expanders with different backend media. ExPAND-Z, which utilizes Z-NAND as its backend (6× slower than PMEM), exhibits an average of 3× higher performance degradation compared to ExPAND-P. However, for workloads such as leslie3d and lbm, ExPANDZ achieves 3.9× and 1.8× better performance, respectively, than LocalDRAM. This indicates that, for specific workloads, a PMEM-based memory expansion system can outperform LocalDRAM configurations.
ExPAND-D, leveraging DRAM as its backend, outperforms LocalDRAM across all graph workloads and SPEC benchmarks, with performance improvements ranging from 1.3× to 3.9× and an average gain is 1.9×. This shows that as the performance of the backend media in memory expander improves, the benefits of using memory expander become much greater compared to building a computing system with only local DRAM.
Impacts of timeliness. To evaluate the impact of backend media on prefetching timeliness, we perform a switchlevel sensitivity analysis using libquantum (highest LLC hit ratio) and TC (lowest LLC hit ratio) as representative workloads (cf. Figure 5b). For libquantum, the high LLC hit ratio minimizes the impact of backend media latency, making switch latency the dominant factor as shown in Figure 7b. In contrast, TC’s low LLC hit ratio amplifies backend media latency, reducing the impact of switch latency. ExPAND-Z and ExPAND-P show 15% and 3% degradation at switch level 1, with average reductions of 12% and 3% for further levels. ExPAND-D, with its low backend latency, experiences a 54% drop at switch level 1 and an average of 32% for additional levels, highlighting its sensitivity to switch latency. These results emphasize the need for prefetchers to achieve high LLC hit rates and account for CXL topology to mitigate switch latency effects, especially with high-performance backend media.
CONCLUSION
We propose an expander-driven CXL prefetcher that offloads LLC prefetching to CXL-SSDs, employing a heterogeneous prediction algorithm. ExPAND ensures data consistency and provides precise prefetch timeliness estimates, reducing CXL-SSD reliance and enhancing graph application performance and SPEC CPU’s performance by 9.0× and 14.7×, respectively, compared to other prefetching strategies. This work is protected by one or more patents.
REFERENCES
1. Donghyun Gouk, Miryeong Kwon, Hanyeoreum Bae, Sangwon Lee, and Myoungsoo Jung. Memory pooling with cxl. IEEE Micro, 2023.
2. Minseon Ahn, Andrew Chang, Donghun Lee, Jongmin Gim, Jungmin Kim, Jaemin Jung, Oliver Rebholz, Vincent Pham, Krishna Malladi, and Yang Seok Ki. Enabling cxl memory expansion for in-memory database management systems. In Proceedings of the 18th International Workshop on Data Management on New Hardware, 2022.
3. Yan Sun, Yifan Yuan, Zeduo Yu, Reese Kuper, Chihun Song, Jinghan Huang, Houxiang Ji, Siddharth Agarwal, Jiaqi Lou, Ipoom Jeong, et al. Demystifying cxl memory with genuine cxl-ready systems and devices. In Proceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, 2023.
4. JH Oh, Jae Hyo Park, YS Lim, HS Lim, YT Oh, Jong Soo Kim, JM Shin, Young Jun Song, KC Ryoo, DW Lim, et al. (full integration of highly manufacturable 512mb pram based on 90nm technology). In IEEE IEDM, 2006.
5. Wooseong Cheong, Chanho Yoon, Seonghoon Woo, Kyuwook Han, Daehyun Kim, Chulseung Lee, Youra Choi, Shine Kim, Dongku Kang, Geunyeong Yu, et al. A flash memory controller for 15μs ultra-low-latency SSD using high-speed 3D NAND flash with 3μs read time. In IEEE ISSCC, 2018.
6. Kioxia Corporation. Kioxia Launches Second Generation of High-Performance, Cost-Effective XLFLASH ™ Storage Class Memory Solution, 2022.
7. Myoungsoo Jung. Hello bytes, bye blocks: Pcie storage meets compute express link for memory expansion (cxlssd). In ACM Hotstorage, 2022.
8. Shao-Peng Yang, Minjae Kim, Sanghyun Nam, Juhyung Park, Jin-yong Choi, Eyee Hyun Nam, Eunji Lee, Sungjin Lee, and Bryan S Kim. Overcoming the memory wall with CXL-Enabled SSDs. In USENIX ATC, 2023.
9. Miryeong Kwon, Sangwon Lee, and Myoungsoo Jung. Cache in hand: Expander-driven cxl prefetcher for next generation cxl-ssd. In ACM Hotstorage, 2023.
10. Yiying Zhang and Steven Swanson. A study of application performance with non-volatile main memory. In IEEE MSST, 2015.
11. Sang-Won Lee, Bongki Moon, and Chanik Park. Advances in flash memory ssd technology for enterprise database applications. In Proceedings of the 2009 ACM This manuscript is an extended version of the original paper accepted by IEEE Micro. 9 SIGMOD International Conference on Management of data, 2009.
12. Bryan S Kim, Hyun Suk Yang, and Sang Lyul Min. Autossd: an autonomic ssd architecture. In 2018 USENIX Annual Technical Conference (USENIX ATC 18), 2018.
13. Arash Tavakkol, Juan Gómez-Luna, Mohammad Sadrosadati, Saugata Ghose, and Onur Mutlu. Mqsim: A framework for enabling realistic studies of modern multi-queuessd devices. In 16th USENIX Conference on File and Storage Technologies (FAST 18), 2018.
14. Abhishek Rajimwale, Vijayan Prabhakaran, and John D Davis. Block management in solid-state devices. In USENIX Annual Technical Conference, 2009. 15. Jean Luca Bez, Suren Byna, and Shadi Ibrahim. I/o access patterns in hpc applications: A 360-degree survey. ACM Computing Surveys, 2023.
16. Pierre Michaud. Best-offset hardware prefetching. In 2016 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2016.
17. Rahul Bera, Anant V Nori, Onur Mutlu, and Sreenivas Subramoney. Dspatch: Dual spatial pattern prefetcher. In IEEE/ACM MICRO, 2019.
18. Mohammad Bakhshalipour, Mehran Shakerinava, Pejman Lotfi-Kamran, and Hamid Sarbazi-Azad. Bingo spatial data prefetcher. In IEEE HPCA, 2019.
19. Akanksha Jain and Calvin Lin. Linearizing irregular memory accesses for improved correlated prefetching. In Proceedings of the 46th Annual IEEE/ACM International Symposium on Microarchitecture, 2013.
20. Mohammad Bakhshalipour, Pejman Lotfi-Kamran, and Hamid Sarbazi-Azad. Domino temporal data prefetcher. In IEEE HPCA, 2018.
21. Stephen Somogyi, Thomas F Wenisch, Anastasia Ailamaki, and Babak Falsafi. Spatio-temporal memory streaming. ACM SIGARCH Computer Architecture News, 2009.
22. Intel Corporation. Intel® 64 and IA-32 Architectures Software Developer’s Manual. Volume 3B: System Programming Guide, Part 2(11), 2011. Part Guide.
23. Debendra Das Sharma. Compute express link (cxl): Enabling heterogeneous data-centric computing with heterogeneous memory hierarchy. IEEE Micro, 2022.
24. Huaicheng Li, Daniel S Berger, Lisa Hsu, Daniel Ernst, Pantea Zardoshti, Stanko Novakovic, Monish Shah, Samir Rajadnya, Scott Lee, Ishwar Agarwal, et al. Pond: Cxl-based memory pooling systems for cloud platforms. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2023.
25. Jacob Wahlgren, Maya Gokhale, and Ivy B Peng. Evaluating emerging cxl-enabled memory pooling for hpc systems. In IEEE/ACM Workshop on Memory Centric High Performance Computing (MCHPC), 2022.
26. Daniel S Berger, Daniel Ernst, Huaicheng Li, Pantea Zardoshti, Monish Shah, Samir Rajadnya, Scott Lee, Lisa Hsu, Ishwar Agarwal, Mark D Hill, et al. Design tradeoffs in cxl-based memory pools for public cloud platforms. IEEE Micro, 2023.
27. Samsung Electronics. Samsung electronics unveils far-reaching, next-generation memory solutions at flash memory summit, 2022. URL https://news.samsung. com/global/samsung-electronics-unveils-far-reachingnext- generation-memory-solutions-at-flash-memorysummit- 2022.
28. CXL Consortium. Compute Express Link 3.0 Specification, 2022.
29. Yunyan Guo and Guoliang Li. A cxl-powered database system: Opportunities and challenges. In 2024 IEEE 40th International Conference on Data Engineering (ICDE), 2024.
30. Erich Strohmaier and Hongzhang Shan. Apex-map: A global data access benchmark to analyze hpc systems and parallel programming paradigms. In SC’05: Proceedings of the 2005 ACM/IEEE Conference on Supercomputing, 2005.
31. Jure Leskovec and Rok Sosiˇc. Snap: A general-purpose network analysis and graph-mining library. ACM Transactions on Intelligent Systems and Technology (TIST), 2016.
32. Pengmiao Zhang, Ajitesh Srivastava, Anant V Nori, Rajgopal Kannan, and Viktor K Prasanna. Fine-grained address segmentation for attention-based variabledegree prefetching. In Proceedings of the 19th ACM International Conference on Computing Frontiers, 2022.
33. Pengmiao Zhang, Rajgopal Kannan, and Viktor K Prasanna. Phases, modalities, spatial and temporal locality: Domain specific ml prefetcher for accelerating graph analytics. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2023. 34. Milad Hashemi, Kevin Swersky, Jamie Smith, Grant Ayers, Heiner Litz, Jichuan Chang, Christos Kozyrakis, and Parthasarathy Ranganathan. Learning memory access patterns. In PMLR, 2018.
35. Peter Braun and Heiner Litz. Understanding memory access patterns for prefetching. In International Workshop on AI-assisted Design for Architecture (AIDArc), held in conjunction with ISCA, 2019.
36. Ajitesh Srivastava, Ta-Yang Wang, Pengmiao Zhang, Cesar Augusto F De Rose, Rajgopal Kannan, and Viktor K Prasanna. Memmap: Compact and generalizable meta-lstm models for memory access prediction. In Advances in Knowledge Discovery and Data Mining: 10 This manuscript is an extended version of the original paper accepted by IEEE Micro. 24th Pacific-Asia Conference, PAKDD 2020, Singapore, May 11–14, 2020, Proceedings, Part II 24, 2020.
37. Arvind Narayanan, Saurabh Verma, Eman Ramadan, Pariya Babaie, and Zhi-Li Zhang. Deepcache: A deep learning based framework for content caching. In Proceedings of the 2018 Workshop on Network Meets AI & ML, 2018.
38. Pengmiao Zhang, Ajitesh Srivastava, Anant V Nori, Rajgopal Kannan, and Viktor K Prasanna. Transformap: Transformer for memory access prediction. arXiv preprint arXiv:2205.14778, 2022.
39. Zhan Shi, Akanksha Jain, Kevin Swersky, Milad Hashemi, Parthasarathy Ranganathan, and Calvin Lin. A hierarchical neural model of data prefetching. In Proceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, 2021.
40. Quang Duong, Akanksha Jain, and Calvin Lin. A New Formulation of Neural Data Prefetching. In ACM/IEEE ISCA, 2024.
41. Pengmiao Zhang, Neelesh Gupta, Rajgopal Kannan, and Viktor K Prasanna. Attention, Distillation, and Tabularization: Towards Practical Neural Network-Based Prefetching. In IEEE IPDPS, 2024.
42. Carey Jewitt, Jeff Bezemer, and Kay O’Halloran. Introducing multimodality. Routledge, 2016.
43. Anthony J Myles, Robert N Feudale, Yang Liu, Nathaniel A Woody, and Steven D Brown. An introduction to decision tree modeling. Journal of Chemometrics: A Journal of the Chemometrics Society, 18, 2004.
44. Nathan Binkert, Bradford Beckmann, Gabriel Black, Steven K Reinhardt, Ali Saidi, Arkaprava Basu, Joel Hestness, Derek R Hower, Tushar Krishna, Somayeh Sardashti, et al. The gem5 simulator. ACM SIGARCH computer architecture news, 39, 2011.
45. Donghyun Gouk, Miryeong Kwon, Jie Zhang, Sungjoon Koh, Wonil Choi, Nam Sung Kim, Mahmut Kandemir, and Myoungsoo Jung. Amber: Enabling precise full-system simulation with detailed modeling of all ssd resources. In 2018 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2018.
46. Donghyun Gouk, Sangwon Lee, Miryeong Kwon, and Myoungsoo Jung. Direct access, high-performance memory disaggregation with DirectCXL. In USENIX Annual Technical Conference (USENIX ATC 22), 2022.
This manuscript is an extended version of the original paper accepted by IEEE Micro.
Related Semiconductor IP
- CXL (Compute eXpress Link) 3.1 IP
- CXL Controller IP
- CXL memory expansion
- CXL 3 Controller IP
- Verification IP for CXL
Related White Papers
- Optimizing PCIe SSD performance
- What's the Difference Between CXL 1.1 and CXL 2.0?
- High-Speed PCIe and SSD Development and Challenges
- Achieving Lower Power, Better Performance, And Optimized Wire Length In Advanced SoC Designs
Latest White Papers
- Transition Fixes in 3nm Multi-Voltage SoC Design
- CXL Topology-Aware and Expander-Driven Prefetching: Unlocking SSD Performance
- Breaking the Memory Bandwidth Boundary. GDDR7 IP Design Challenges & Solutions
- Automating NoC Design to Tackle Rising SoC Complexity
- Memory Prefetching Evaluation of Scientific Applications on a Modern HPC Arm-Based Processor