A 16 nm 1.60TOPS/W High Utilization DNN Accelerator with 3D Spatial Data Reuse and Efficient Shared Memory Access
By Xiaoling Yi, Ryan Antonio, Yunhao Deng, Fanchen Kong, Joren Dumoulin, Jun Yin, Marian Verhelst
MICAS-ESAT, KU Leuven, Leuven, Belgium
Abstract
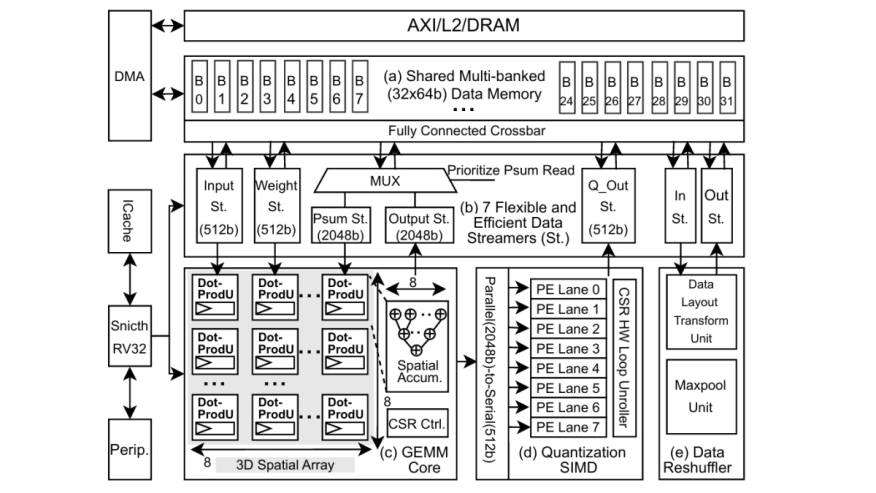
Achieving high compute utilization across a wide range of AI workloads is crucial for the efficiency of versatile DNN accelerators. This paper presents the Voltra chip and its utilization-optimised DNN accelerator architecture, which leverages 3-Dimensional (3D) spatial data reuse along with efficient and flexible shared memory access. The 3D spatial dataflow enables balanced spatial data reuse across three dimensions, improving spatial utilization by up to 2.0x compared to a conventional 2D design. Inside the shared memory access architecture, Voltra incorporates flexible data streamers that enable mixed-grained hardware data pre-fetching and dynamic memory allocation, further improving the temporal utilization by 2.12-2.94x and achieving 1.15-2.36x total latency speedup compared with the non-prefetching and separated memory architecture, respectively. Fabricated in 16nm technology, our chip achieves 1.60 TOPS/W peak system energy efficiency and 1.25 TOPS/mm2 system area efficiency, which is competitive with state-of-the-art solutions while achieving high utilization across diverse workloads.
Index Terms — DNN Accelerator, 3D Spatial Data Reuse, Flexible and Efficient Data Access, Shared Memory, High Utilization
To read the full article, click here
Related Semiconductor IP
- UCIe D2D Adapter & PHY Integrated IP
- Low Dropout (LDO) Regulator
- 16-Bit xSPI PSRAM PHY
- MIPI CSI-2 CSE2 Security Module
- ASIL B Compliant MIPI CSI-2 CSE2 Security Module
Related Articles
- 3+ ways to design reconfigurable algorithm accelerator in IP block
- RAID6 accelerator in a PowerPC IOP SOC
- Emulator, accelerator, prototype - what’s the difference?
- NVMe host IP for computing accelerator
Latest Articles
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks