A Low Complexity Parallel Architecture of Turbo Decoder Based on QPP Interleaver for 3GPP-LTE/LTE-A
Suchang Chae, ETRI
Daejeon Korea
Abstract :
This paper propose an improved method called the modified warm-up-free parallel window(PW) MAP decoding schemes to implement highly-parallel Turbo decoder architecture based on the QPP(Quadratic Polynomial Permutation) interleaver of 3GPP LTE/LTE-A standards. In general, Turbo decoder needs long decoding time because of iterative decoding. To communicate with high speed, we have to shorten decoding time and it is possible by using QPP interleaver-based Turbo code of 3GPP LTE/LTE-A standards. Basically, the QPP interleaver has been giving attention since it provides contention-free interleaving functionality for highly-parallel Turbo decoders. So we have to have relatively short decoding time and reduced complexity of MAP decoder of Turbo codes. As a result, we have got the modified warm-up-free PW of 64 according to the maximum code block length, 6144 and we propose the improved Turbo decoder architecture with modified warm-up-free PW MAP decoding occupying one of the FSMC, BSMC, LLRC, (de-)interlever logic and its memory size of only PF•PW/4 respectively(where, PF means parallel factor).
And we would like to improve the BER performances of modified warm-up-free PW MAP decoder compared with warm-up or slide window MAP decoding schemes. In order to improve BER performances of warm-up-free PW MAP Decoder, we initialize FSM, BSM and LLR computed in the previous iteration of the adjacent PW block. Therefore, we have got such the BER performance as that of warm-up or slide window MAP decoding schemes. And also, we have achieved the goal of PW MAP decoding for turbo decoder which has low complexity highly-parallel and high-speed architecture, and no degradation of BER performances.
Introductions
The turbo code can achieve near Shannon limit performance through iterative decoding process, so it is very impressive forward error correction technique [1]. It is typically constructed with two constituent convolutional codes and one interleaver. The interleaver is crucial to the error-correcting capability, but its pseudo random property complicates parallel execution and restricts throughput enhancement [2]. To make a resolution of above problem, many contention-free interleaver that allow parallel window MAP decoders to process every code word under trial memory mapping are proposed [3-5]. QPP-interleaver is such an interleaver and is adopted by 3GPP LTE standard [6]. A Parallel architecture with multiple window of MAP will divide every received size-L block into W-size subblocks. However, the whole speedup will be less than the expected W because a shortened subblock size leads to lower operating efficiency. The modified schedule in [7] has shorter latency and higher efficiency at the expense of extra storage elements. And also, [8] introduces the relation between processing schedule and operating efficiency to achieve high operating efficiency by imposing constraints on the QPP interleaver.
This paper discusses several key problems in the implementation of highly parallel decoders. One of the problems is memory contention conflict during decoding, where overall subblock of MAP decoders simultaneously get access to the same memory bank on reading or writing the extrinsic information from or into memory bank. To solve this problem, this paper presents an efficient approach for designing collision-free parallel interleavers in which data is written or read on the intra-sublock as well as iter-subblock of MAP decoder to achieve low complexity architecture having no additional hardware resources.
The second problem in the implementation of highly parallel decoders is concerned with no degradation of BER performances when parallel window (PW) MAP decoding simultaneously is performed subblock by subblock according to performing the MAP calculation. This paper proposes the parallel window MAP decoding scheme with no training path of state metric to make MAP decoder have low latency. Therefore, to keep such the BER performances with no degradation as with having training path of state metric calculation, the proposed PW MAP decoder in this paper feeds back FSM and BSM in addition to extrinsic information of LLR every iterative decoding.
Basic of turbo codes
It is constructed with two parallel constituent convolutional codes (PCCC) and one interleaver. Internal interleaver of turbo codes called turbo interleaver has been used to QPP based interleaver since 3GPP LTE standards. So it is possible to parallel calculate window MAP to implement high speed turbo decoder. An example of such a code is shown in fig.1. Input sequence for encoder 1 is encoded to first parity bits sequence, and its interleaved sequence for encoder 2 is encoded to second parity bits sequence.
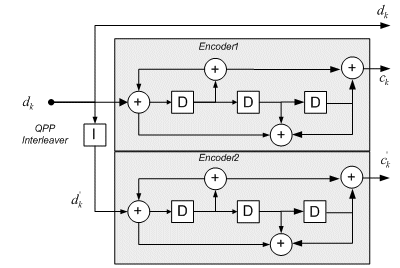
Fig.1 Example of 3GPP LTE turbo encoder
The reason of constructing PCCC structure and turbo interleaver is in order to perform turbo algorithm in the decoder side. The decoding of turbo codes is based on an iterative structure constructed from two MAP decoders, one for each constituent encoder. A general block diagram of a turbo decoder is shown in fig.2. Each MAP decoder has three inputs : a prior LLR for systematic bits, channel LLR for systematic bits and channel LLR for parity bits. The output of each MAP decoder is called ‘extrinsic information or LLR denoted Zk. First LLR for parity bits is to be decoded by MAP1 decoder and second one by MAP2 decoder. Also, first the LLR as extrinsic information decoded from MAP1 is fed back to input of MAP2. MAP2 then performs second decoding by extrinsic information and second LLR for parity bits. As well as MAP1, the second LLR resulted from MAP2 is fed back to MAP1 as extrinsic information.
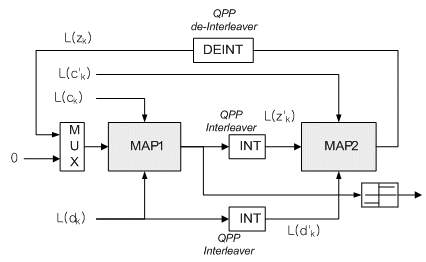
Fig.2 General structure of turbo decoder
The desired effect is that the extrinsic LLRs increase in absolute value after each iteration. This effectively improves reliability of the decoding, and decrease bit error rate (BER). In general, since turbo code is a kind of convolution codes, BER performances is decided by constraint length of encoder. By the way, input sequences of MAP1 shall be also uncorrelated with input sequences of MAP2 by turbo interleaver to improve the value of extrinsic information.
QPP interleaver has been gaining since it provides contention-free interleaving functionality for high speed parallel turbo decoders. By using QPP interleaver, parallel window of MAP can be parallel operated in each window MAPs. We would like to implement high speed parallel turbo decoder which have 64-parallel window MAP.
QPP interleaver of 3GPP LTE
In the turbo codes, an interleaver is a critical component for the BER forformance of turbo codes. And also, the parallel processing of iterative decoding of turbo codes is of inerest for high-speed decoders. Interleaving of extrinsic information is one important aspect to be adressed in parallel decoders because a memory access contention may appear during the exchange of extrinsic information between the sublocks of the iterative decoder. The QPP(Quadratic Permutation Polynormial)interleaver defined in the new 3GPP LTE standrd differs from previous 3G interleavers in that it is based on algebraic construction via permutation polynormials over integer rings. It is known that permutation polynormials generate contention-free interleavers. Interleaving of extrinsic information is a important issue that needs to be addressed to enable parallel decoding becaue memory access contention may occur when MAP decoders fetch and write extrinsic information from or to memory. QPP interleaveris contention-free for every parallel window size, W which is a factor of the interleaver length, L. For the size-L block, the QPP interleaving formula is
π(i) = (f1 ∙ i+ f2 ∙ i2 ) mod L (1)
Where i is the original address, and π(i) stands for the interleaved address. The interleaing parameters, f_1 and f_2, are determined by the block size. In general, there will be many valid pairs of f_1 and f_2. After a caful search of these parameters, we can get the contention-free interleavers with suprior error correcting capability[9].
In the proposed parallel window MAP, in order to save the hardware resource interleaver on calculating LLR, We make them calculated with the same direction. LLR calculator will be required to occupy double resource of LLRC, if LLR calculation has different direction all the sub-window(W/4 period) in the window(W period) like [10].
Map decoding method of turbo codesWe simply need to summarize several MAP(Maximum A Posteriori) calculation scheme used in general. First of all, Conventional MAP decoding scheme is the method performing FSM(forward state metric) calculation, BSM(backward state metric) calculation, and then LLR(log likelihood ratio) calculation as shown in fig.3.
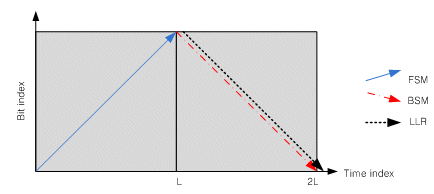
Fig.3: conventional scheme
Second, there is double flow MAP calculation scheme. This scheme is the method simultaneously calculating FSMC and BSMC, therefore LLRC can be calculated at the middle of code block length, L as shown in fig.4.
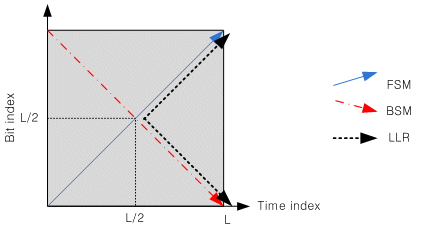
Fig.4: Double flow scheme
LLRC of double flow scheme will increase hardware complexity due to using the duplicated resource of interleaver. To resolve this issue, we make all of the LLRC calculate just forward from initial stage to last stage.
Third scheme is the improved double flow method. It occupies one interleaver address generator and one LLRC because LLRC operates forward instead of backward as shown in fig.5.
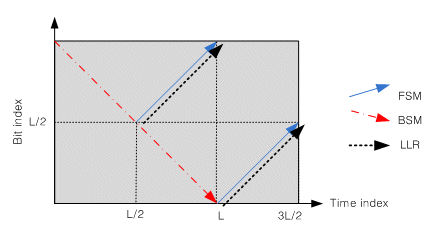
Fig.5: improved double flow scheme
We think that MAP calculator have low complexity and high speed because we implement Mobile Hot-spot Network system (call MHN system) which requires 1.2Gbps data rate in the high speed vehicle on the road or rail. MHN will utilize mmWAVE of 27GHz, 500M bandwidth as frequency resource. So we need to implement high speed turbo decoder as well as turbo encoder. So we have to make MAP decoder having parallel window MAP architecture.
Finally, we make the improved parallel window MAP architecture (called as improved PW MAP) as shown in fig.6. Improved PW MAP architecture is no training path of calculating forward/backward state metrics, no degradation of BER performances, no memory contention using QPP interleaver on inter- and intra-PW and no additional hardware resource just using 1-FSMC, 1-BSMC, 1-LLRC, 1-Interleaver hard ware resource.
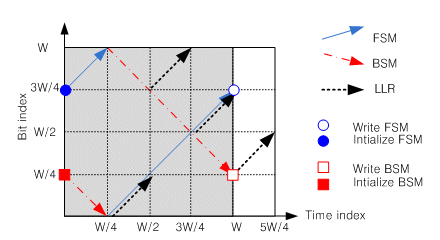
Fig.6 proposed parallel window MAP scheme
To keep the same BER performances as having training path, Improved PW MAP architecture initialize FSM or BSM in the previous iteration of the adjacent sub block. However, we can’t initialize state metrics in the first iteration of PW because of no previous iteration of sub block. In general, the length for training path to have reliable state metric is normally six times the constraint length of the code. We select 96bit of PW size and the number of PW have the maximum 64. It is enough to make state metric reliable. And QPP interleaver already provides address generator up to 64 memory bank.
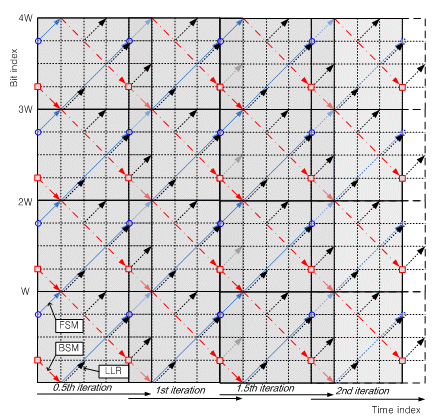
Fig.7 the example of proposed PW MAP decoding with PW=4, 2 iteration decoding.
Fig.7 shows the example of CB=6144, PW=64, 2 iteration decoding. The LLR in the fig.7 is used to make a decision, while the extrinsic information is treated as the a posteriori probility estimation for the other constituent code. Such soft value computation of each constituent code is called one half-iteration, and two successive half-iteration make a complete iteration.
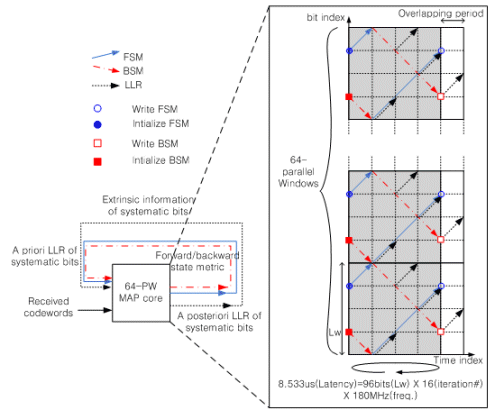
Fig.8 the example of turbo decoder with 64-parallel window MAP architecture
Fig.9 simply shows the BER performances curve of improved PW MAP decoder to meet the MHN system requirements by simulating results of C++ floating point program. We consider code rate of 0.7 /0.8 and modulation order of 16QAM, 64QAM and 256QAM as simulation parameters.
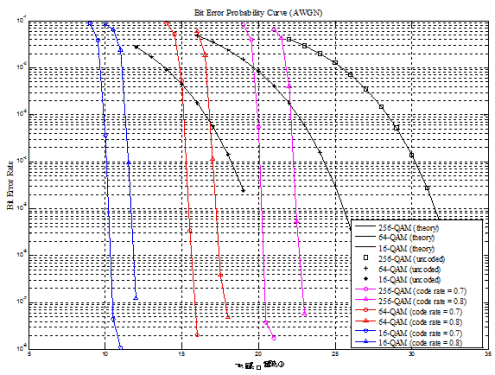
Fig.9 BER performances curve of turbo decoder using 64-PW architecture for MHN system.
[1] C. Berrow, A. Glavieux, and P. Thitimajshima, “Near Shannon limit error-correcting coding and decoding: Turbo codes,” in Proc. IEEE Int. Conf. Comm., May 1993, pp. 1064-1070.
[2] A. Giuletti, L. van der Perre, and M. Strum, “Parallel turbo coding interleavers: Avoding collisions in accesss to storage elements,” Elec. Lett., Vol. 38, no. 5, pp. 232-234, Feb. 2002.
[3] J. Sun and O. Y. Takeshita, “Interleavers for turbo codes using permutation polynomials over integer rings,” IEEE Trans. Inform. Theory, Vol. 51, no. 1, pp. 101-119, Jan. 2005.
[4] O. Y. Takeshta, “On maximum contention-free interleavers and permutation polynomials over integer rings,” IEEE Trans. Inform. Theory, vol. 52, no. 3, pp. 1249-1253, Mar. 2006.
[5] J. Ryu and O. Y. Takeshita, “On Qudratic inverses for quadratic permutation polynomials over integer rings,” IEEE Trans. Inform. Theory, vol. 52 no. 3, pp. 1254-1260, Mar. 2006.
[6] 3GPP TSG RAN WG1-47, “Performance comparision of LTE turbo internal interleaver proposals,” Sorrento, Italy, Jan. 2006.
[7] A. Dingninou, F. Rafaoui, and C. Berrou, “Organisation de le memorie dans un turbo decodeur untilisant l’algorithm sub-MAP,” in Proc. GRETSI, Sep. 1999, pp. 71-74.
[8] C. C. Wong and H. C. Chang, “High-Efficiency Processing Schedule for Parallel Turbo Decoders Using QPP Interleaver,” IEEE Trans. Circuits and Systems, vol. 58, no. 6, Jun. 2011.
[9] O. Y.Takeshima, “On maximaum contention-free interleavers and permutation polynormials over integer rings,” IEEE Tranx. Inf. Theory, vol. 52, no. 3, pp. 1249-1253, Mar. 2006.
[10] Z. H. Paul Foutier and S. Roy, “Highly-Parallel Decoding Architectures for Convolutional Turbo Codes,” IEEE Trans. VLSI system, vol. 14, no. 10, Oct. 2006.
Related Semiconductor IP
- Turbo Decoder
- Turbo decoder
- LTE Turbo Decoder
- Industry reference DVB-RCS turbo decoder
- DVB-RCS2 turbo decoder
Related Articles
- Unified C-programmable ASIP architecture for multi-standard Viterbi, Turbo and LDPC decoding
- Reconfiguring Design -> C-based architecture assembly supports custom design
- High-Performance DSPs -> Processor boards: Architecture drives performance
- Opto-electronics -> High-density fiber-optic modules eye next-gen switching architecture
Latest Articles
- VolTune: A Fine-Grained Runtime Voltage Control Architecture for FPGA Systems
- A Lightweight High-Throughput Collective-Capable NoC for Large-Scale ML Accelerators
- Quantifying Uncertainty in FMEDA Safety Metrics: An Error Propagation Approach for Enhanced ASIC Verification
- SoK: From Silicon to Netlist and Beyond Two Decades of Hardware Reverse Engineering Research
- An FPGA-Based SoC Architecture with a RISC-V Controller for Energy-Efficient Temporal-Coding Spiking Neural Networks