A 14ns-Latency 9Gb/s 0.44mm² 62pJ/b Short-Blocklength LDPC Decoder ASIC in 22FDX
By Darja Nonaca 1, Jérémy Guichemerre 1, Reinhard Wiesmayr 1, Nihat Engin Tunali 2, and Christoph Studer 1
1 Department of Information Technology and Electrical Engineering, ETH Zurich, Switzerland;
2 Independent Researcher
Abstract
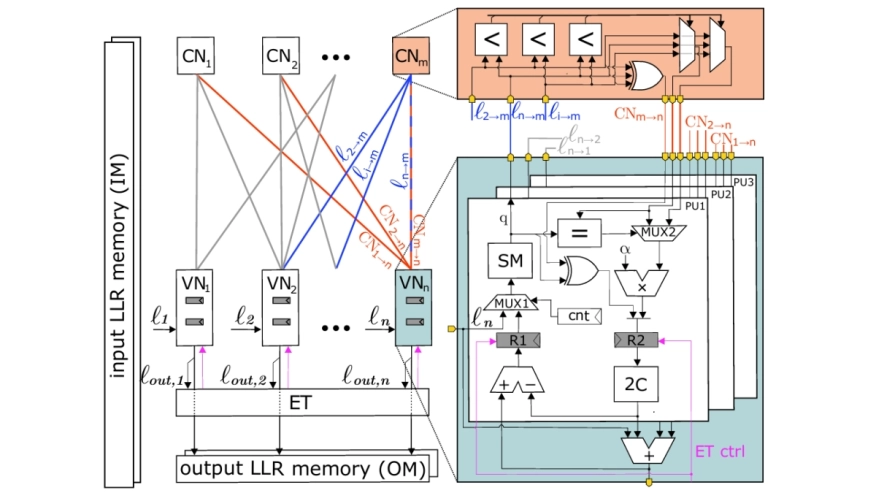
Ultra-reliable low latency communication (URLLC) is a key part of 5G wireless systems. Achieving low latency necessitates codes with short blocklengths for which polar codes with successive cancellation list (SCL) decoding typically outperform message-passing (MP)-based decoding of low-density parity-check (LDPC) codes. However, SCL decoders are known to exhibit high latency and poor area efficiency. In this paper, we propose a new short-blocklength multi-rate binary LDPC code that outperforms the 5G-LDPC code for the same blocklength and is suitable for URLLC applications using fully parallel MP. To demonstrate our code’s efficacy, we present a 0.44mm2 GlobalFoundries 22FDX LDPC decoder ASIC which supports three rates and achieves the lowest-in-class decoding latency of 14ns while reaching an information throughput of 9Gb/s at 62pJ/b energy efficiency for a rate-1/2 code with 128-bit blocklength.
To read the full article, click here
Related Semiconductor IP
- LunaNet AFS LDPC Encoder and Decoder IP Core
- 5G LDPC Decoder
- NavIC LDPC Decoder
- Flash Memory LDPC Decoder IP Core
- LDPC Intel® FPGA IP
Related Articles
- A 0.32 mm² 100 Mb/s 223 mW ASIC in 22FDX for Joint Jammer Mitigation, Channel Estimation, and SIMO Data Detection
- Practical Considerations of LDPC Decoder Design in Communications Systems
- Low power LDPC decoder created using high level synthesis
- Paving the way for the next generation of audio codec for True Wireless Stereo (TWS) applications - PART 5 : Cutting time to market in a safe and timely manner
Latest Articles
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks