How Alternate Geometry Processing Enables Better Multi-Core GPU Scaling
Scaling GPU performance across multiple cores sounds simple in theory: add more cores, get more performance. In practice, it’s one of the toughest challenges in graphics architecture. While some workloads scale well thanks to their independent nature, some workloads, especially geometry processing, introduce order dependencies that make linear performance scaling a tricky problem to solve for every GPU architecture in the industry.
Why Multi-Core GPU Scaling Is Hard
Modern GPUs thrive on parallelism, but not all tasks are created equal. Geometry processing, for example, is inherently sequential. Graphics APIs expect objects to be processed in submission order because visibility and rendering often depend on that sequence. This means geometry workloads typically run on a single core, generating an in-order tile list for the rest of the pipeline. When geometry becomes a bottleneck, other cores sit idle, and scaling efficiency collapses.
This isn’t unique to us at Imagination. Other GPU architectures face similar challenges: their architectures also struggle when workloads can’t be evenly distributed. Techniques like dynamic parallelism and hardware queues help, but geometry-heavy scenes remain problematic. This results in adding cores doesn’t always deliver proportional gains – no matter what GPU you use.
What then is our solution to this challenge?
Inside Imagination’s Multi-Core GPU Architecture
Before we dive into our approach to geometry scaling, let’s first revisit some multi-core fundamentals from Imagination.
Our Imagination GPUs come with a highly scalable multi-core technology to help system designers achieve greater peak performance or maximum workload flexibility. The Imagination approach is decentralised and loosely-coupled, addressing the congestion and layout flexibility challenges of traditional centralised multi-core approaches.
The cores are loosely coupled, only sharing command and tile buffer lists in memory and sharing the workload between them. As each core is designed as a full independent GPU it contains all the functionality required to self-manage and execute workloads based on priority.
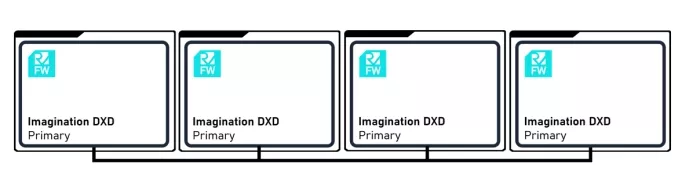
Imagination GPU multi-core grid in primary-primary mode
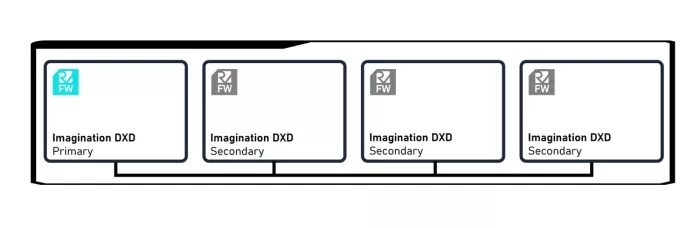
Imagination GPU multi-core grid in primary-secondary mode
Each core in a multi-core grid is designed to operate independently (in a primary-primary set up) or in concert (primary-secondary). In primary-secondary mode, one Firmware processor is active within the Primary GPU Core and driving the workloads active in all other Secondary GPU Cores which are part of the multi-core grid. Multiple GPU instances share command streams and jointly finish the work as quickly as possible. By working on distinct regions of the work (the render target) in each GPU core our bandwidth efficiency is maintained, as each core continues to work on a coherent region of the screen, thus ensuring maximal cache hit efficiency (data is cached specific to the work processed by each GPU core, thus avoiding unnecessary data movement and duplication between cores, increasing efficiency).
Register settings and syncs across the multi-core grid are handled via a dedicated XPU bus which connects the Primary GPU Core with all Secondary GPU Cores allowing point to point as well as broadcast concepts. The inter-core communication fabric and memory hierarchy are optimised to reduce latency as core counts increase. The fabric can also be used to distribute the GPU cores across multiple chiplets, chips or even boards. This provides our customers with more flexibility in their design choices and allows for significant cost savings, as a customer can design a single chiplet (or chip) which can then be used to build up multiple performance points, simply by packaging one or more chiplets to scale GPU performance.
Enter Alternate Geometry Processing (AGP)
Now, back to the challenge of achieving close to linear performance scaling across these cores. An important feature of our multi-core technology, introduce with the B-Series and refined in subsequent generations, is Alternate Geometry Processing (AGP). Instead of forcing all geometry through a single core, AGP distributes geometry workloads across multiple cores, but with a twist. Rather than breaking the strict in-order requirement within a single render target, AGP assigns different render targets or frames to different cores.
For example:
- Core #1 handles geometry for Render Target A.
- Core #2 processes geometry for Render Target B.
Meanwhile, pixel processing and compute tasks are sliced and spread across all cores.
This approach respects API ordering rules while unlocking parallelism where it’s safe across independent renders. In multi-frame or multi-render scenarios, AGP dramatically reduces idle time and balances workloads more effectively.
Real-World Benefits of Alternate Geometry Processing
Improved Scaling Efficiency
By sharing geometry work across cores, AGP prevents one core from becoming a bottleneck. This is especially valuable in multi-core grids used for cloud gaming or automotive systems, where multiple scenes or displays are processed simultaneously.
Better Resource Utilisation
Without AGP, the core doing geometry also handles its share of pixel processing, slowing down the entire grid. AGP evens out the load, reducing skew and keeping all cores busy.
How Imagination’s AGP Compares to Other GPU Vendors
Other GPU vendors tackle this problem differently. NVIDIA’s multi-GPU setups often rely on frame-level parallelism (alternate frame rendering), while AMD uses command processors and hardware queues to distribute work. Both approaches face similar limitations: geometry-heavy scenes can still choke scaling because they’re hard to split without breaking rendering correctness.
Imagination’s AGP stands out because it’s software-driven and integrated into our tile-based architecture, making it efficient and flexible. Combined with our decentralised, loosely-coupled multi-core design, AGP helps deliver near-linear scaling for workloads that would otherwise stall.
What This Means for System Designers
For system designers, the takeaway is clear: multi-core scaling isn’t just about adding cores, it’s about smart workload management.
If you’re interested in finding out more about how to build a high performance, multi-core solution based on Imagination GPU IP, and how to allocate workloads effectively, reach out to our team.
Related Semiconductor IP
- E-Series GPU IP
- Arm's most performance and efficient GPU till date, offering unparalled mobile gaming and ML performance
- Highest performance automotive GPU IP, with revolutionary functional safety technology
- High performance GPU for cloud gaming with DirectX support
- Arm’s latest flagship GPU is based on the new 5th Gen GPU architecture, bringing the next generation of visual computing to mobile
Related Blogs
- Vivante Vega GPU Geometry and Tessellation Shader Overview
- Vivante Vega GPU Geometry and Tessellation Shader Overview
- How Is the Semiconductor Industry Handling Scaling: Is Moore's Law Still Alive?
- How audio development platforms can take advantage of accelerated ML processing
Latest Blogs
- IDS-Verify™: From Specification to Sign-Off – Automated CSR, Hardware Software Interface and CPU-Peripheral Interface Verification
- RISC-V and GPU Synergy in Practice: A Path Towards High-Performance SoCs from SpacemiT K3
- EDA AI Agents: Intelligent Automation in Semiconductor & PCB Design
- Why Security Can't Exist Without Trust
- Universal Browser Support for JPEG XL: Is Your Hardware Ready for the New Standard?