Neuromorphic Computing: A Practical Path to Ultra-Efficient Edge Artificial Intelligence

AI processing is moving to the edge for simple reasons: latency, power, bandwidth, and privacy. When the model sits in the cloud, you pay a round-trip tax for sending the data to the cloud and back. When it sits next to the sensor, you don’t.
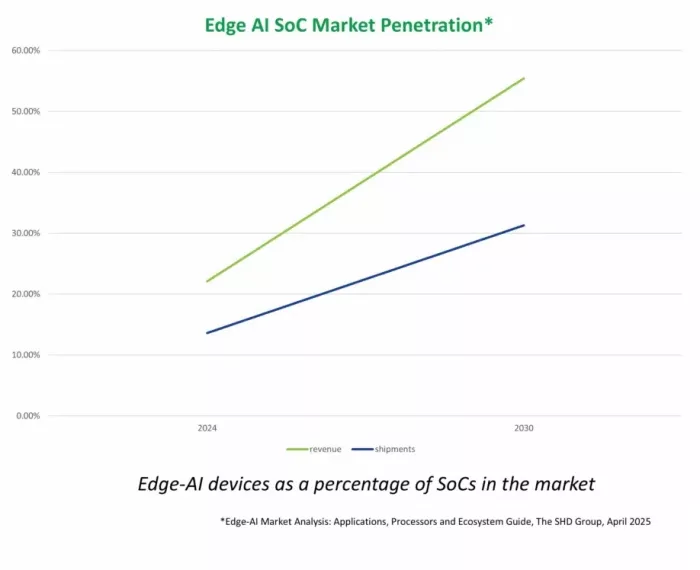
Edge-AI devices as a percentage of SoCs in the market
System-on-Chip (SoC) design plans reflect that shift, with edge-AI SoCs now becoming a significant portion of SoCs shipped (see SHD Group’s April 2025 analysis).
The real AI bottleneck isn’t arithmetic, it’s data motion. Most inference is matrix–vector operations over large, mostly static, weight matrices, often up to tens of megabytes. Traditional von Neumann (stored program and data) machines burn energy shuttling those weights between memory and the AI processing unit.
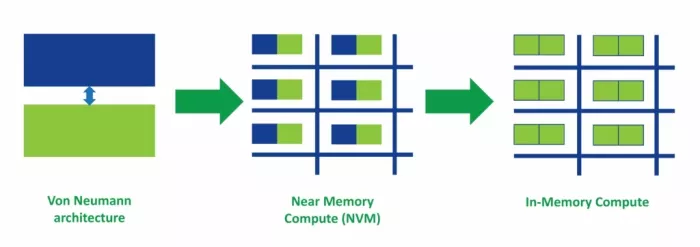
From Von Neumann architectures to IMC
Bandwidth caps throughput but it is power that caps the product. Even if you squeeze more throughput technically, you can’t ship it if it blows the power budget, especially since many of these edge devices run on batteries.
The smart remedy is to move the math processing to where the weights live. In-Memory Compute (IMC) performs multiply–accumulate operations inside memory arrays, practically eliminating the power-hungry memory-to-processor traffic.
In analog IMC, cells directly store synaptic weights and the array itself executes the matrix–vector multiply. You get more useful work per joule for the same silicon area. For edge devices, that can be the difference between “demo on the bench” and “feature that ships.”
That approach fits naturally with neuromorphic computing, which are architectures inspired by neurons and synapses. Neuromorphic systems are massively parallel, asynchronous and event-driven, so the hardware draws (almost) no dynamic power unless something happens that requires work. Pair that with IMC and you minimize movement between “neurons” and weight storage, saving power.
The near-term use cases are pragmatic: industrial Internet of Things (IoT) for predictive maintenance, wearables that respond locally in real time, and self-learning robots where a cloud call is a non-starter for real-time responsiveness and autonomy.
Among non-volatile memories (NVMs), Resistive Random-Access Memory (ReRAM or RRAM) is an ideal solution for analog IMC.
In ReRAM, programming pulses partially form or dissolve a conductive filament in the resistive layer, tuning the cell’s conductance. Pulses can be stronger or weaker, creating different levels of resistance which translate to multi-level storage, where a single cell can represent many values and not just a single bit of 1 or 0. In ReRAM, reads and writes are low-voltage, currents are low, and standby power (when no operation is performed) is effectively zero. On the manufacturing side, it’s a two-mask Back End Of Line (BEOL) add-on using fab-friendly materials, stackable between metal layers, with no interference to Front End Of Line (FEOL) transistors that could impact analog and RF circuits. In other words, it is practical to embed next to logic without blowing up cost or risk.
There are other ways to do analog IMC, but each one has a different limitation. Fixed resistors are stable and precise until you need an update, at which point you need a new mask set, which doesn’t work for multi-function edge products. Embedded flash memory can offer high dynamic range, but embedded flash typically tops out around the 28nm node, which limits network size and efficiency for modern workloads. Magnetoresistive RAM (MRAM) integrates cleanly with logic, but its dynamic range and multi-level stability are weak for analog precision, not to mention the fact that it is sensitive to magnetic fields which are present all around us. All of this explains why ReRAM is fast becoming the most popular solution for IMC at the edge.
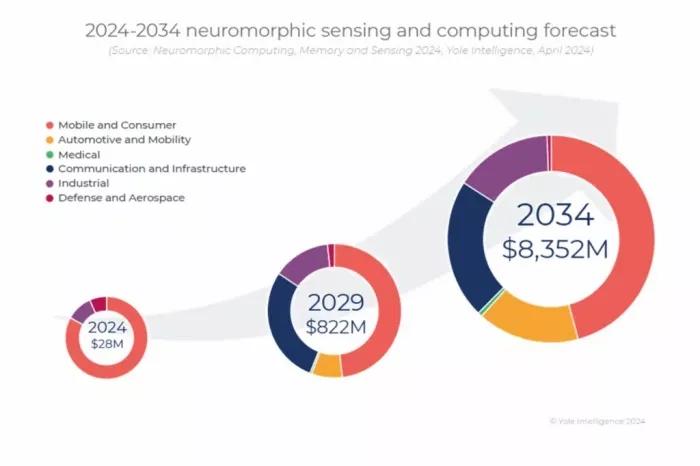
Yole 2024-2034 neuromorphic sensing and computing forecast
Yole Group projects that analog IMC and other IMC approaches leveraging ReRAM and emerging memories begin ramping after 2027, and flags neuromorphic methods as promising for sustainable, efficient edge AI. That squares with the broader market. Digital accelerators will keep winning wherever thermals and budgets allow. However, the efficiency frontier on battery and constrained size is nudging compute toward memory-centric and event-driven designs. If you build edge products, the practical move now is capability building: characterize arrays, calibrate for drift and precision, develop accurate device models, optimize AI algorithms for operation in analog IMC, and create robust toolchains. Those are the levers that shorten time-to-adoption.
There are some tough challenges. Precision limits and conductance drift over time/temperature require robust calibration and compensation while density scaling and interconnect complexity raise architecture and routing questions. For fabs, materials and manufacturing must stay inside normal guardrails.
And, of course, the software development stack is pivotal as engineers need compilers/mappers that target analog arrays, automate calibration, and make behavior predictable in standard toolchains.
The good news is that there is a great deal of work going on in these areas. At Weebit we are participating in active collaborations with organizations including the NeMo Consortium, Edge AI Foundation, NeAIxt, university groups, and partners like CEA-Leti and other research institutes. With Leti, we first demonstrated spiking neural networks on ReRAM in 2019. You can read about some of these partnerships in my colleague Eran Briman’s recent blog article, ‘Pushing the Boundaries of Memory: What’s New with Weebit and AI.”
The ecosystem is now converging across device physics, circuits, architecture, algorithms, and tools.
Edge AI isn’t a peak-TOPS contest anymore, it’s an efficiency race. Neuromorphic blocks with ReRAM-based in-memory compute shift the matrix–vector workloads into the memory fabric and reduce the data-motion cost. In this hybrid design, analog IMC arrays built on ReRAM handle the compute-heavy matrix-vector operations with a very efficient power profile. The digital side handles everything else. This hybrid approach offers the best of both worlds: running the very structured, compute-heavy matrix-vector operations in analog while running the parts of the algorithms that can’t be easily mapped into analog circuits in a digital fashion.
We believe that Neuromorphic IMC will become dominant in edge inference in the future. You can expect to see hybrids of conventional digital logic plus IMC tiles in the near future. Analog IMC will handle the front-end of the algorithm where most of the computation is done. Digital processing will take care of the less structured decision making parts of the algorithms.
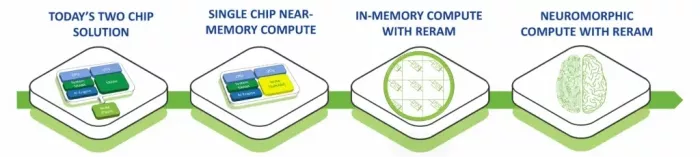
The journey to new AI architectures with ReRAM
Interested in more on this topic? Check out the full presentation “Neuromorphic Computing: A Primer on the Path to Ultra-Efficient AI” that I presented earlier this month at Embedded World North America.
Related Semiconductor IP
Related Blogs
- A Complete No-Brainer: ReRAM for Neuromorphic Computing
- A Hybrid Subsystem Architecture to Elevate Edge AI
- Physical AI at the Edge: A New Chapter in Device Intelligence
- Advancing In-Memory Computing: A Global Effort to Build More Efficient AI Hardware
Latest Blogs
- Synopsys Advances Die‑to‑Die Connectivity with 64G UCIe IP Tape‑Out
- The 5 Biggest Challenges in Modern SoC Design (And How to Solve Them)
- Can Your NPU Run DOOM? Chimera Can.
- Importance Of Hardware Security Verification In Pre-Silicon Design
- Arteris × XuanTie: The “Data Highway” for High-Performance RISC-V SoCs