Enabling ‘Few-Shot Learning’ AI with ReRAM

AI training happens in the cloud because it’s compute-intensive and highly parallel. It requires massive datasets, specialized hardware, and weeks of runtime. Inference, by contrast, is the deployment phase — smaller, faster, and often done at the edge, in real time. The cloud handles the heavy lifting; the edge delivers the result. Now, recent advances in resistive memory technology are making edge AI inferencing more energy-efficient, secure, and responsive.
At the 2025 IEEE Symposium on VLSI Technology and Circuits, researchers from CEA-Leti, Weebit Nano, and the Université Paris-Saclay presented a breakthrough in “on-chip customized learning” — demonstrating how a ReRAM-based platform can support few-shot learning using just five training updates.
Few-shot learning (FSL) is an approach where AI models learn new tasks with only a handful of examples. It is very useful for edge applications, where devices must adapt to specific users or environments and can’t rely on large, labeled datasets.
The team didn’t just train a model — they showed that a memory-embedded chip could adapt in real-time, at the edge, without requiring cloud access, long training cycles, or power-hungry hardware. The core enabler is a combination of Model-Agnostic Meta-Learning (MAML) and multi-level Resistive RAM (ReRAM or RRAM).
MAML provides a clever workaround that can enable learning in power-constrained edge devices. Instead of training from scratch, it trains a model to learn. During an off-chip phase, the system builds a general-purpose model by exposing it to many tasks. This “learned initialization” is then deployed to edge devices, where it can quickly adapt to new tasks with minimal effort.
This means:
- No need for the cloud – minimizing bandwidth and latency
- Minimal data required – minimizing compute requirements at the edge
- Massive time and energy savings
Executing this on edge hardware requires memory technology that can keep up — and that’s where ReRAM comes in.
Because ReRAM is a non-volatile memory that supports analog programming, it is ideal for low-power and in-memory compute architectures. ReRAM can store information as varying conductance states, which can then represent the weights (numerical values that represent the strength or importance of connections between neurons or nodes in a model) in neural networks.
However, ReRAM also comes with challenges — notably variability and some limits on write endurance. Few-shot learning helps overcome both.
Reducing Write Cycles with MAML
In terms of endurance, the key is in leveraging MAML, which enabled the research team to reduce the number of required write operations by orders of magnitude. Instead of millions of updates, they showed that just five updates — each consisting of a handful of conductance tweaks — were enough to adapt to a new task.
For the experiments, a chip fabricated on 130nm CMOS was used which has multi-level Weebit ReRAM integrated in the back end of line (BEOL). The network architecture had four fixed convolutional layers and two trainable fully-connected (FC) layers. Weights in the FC layers were encoded using pairs of ReRAM cells, storing the difference in conductance between them.
Training was carried out using a “computer-in-the-loop” setup, where the system calculated gradients and issued write commands directly to the ReRAM crossbars. In a full deployment, this would be managed by a co-integrated ASIC.
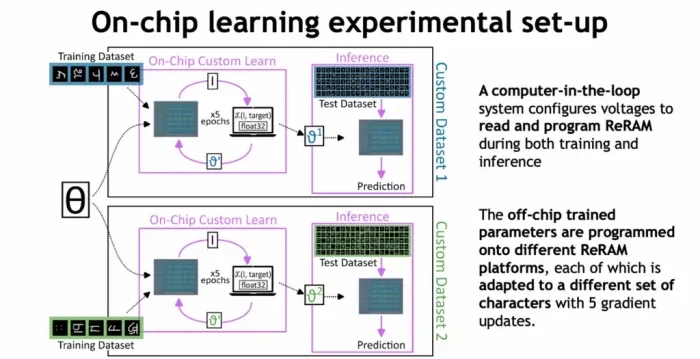
The learning task? Character recognition from the Omniglot dataset, a popular benchmark in FSL. The chip was pre-loaded with the MAML-trained parameters and fine-tuned on-device to recognize new characters using only five gradient updates.
The result:
- Starting at 20% accuracy (random guess)
- Reaching over 97% accuracy after five updates
- Energy use of less than 10 μJ for a 2kbit array
For an optical character recognition (OCR) application using AI with a 2Kbit array, energy consumption of less than 10 μJ represents excellent energy efficiency compared to typical industry benchmarks. This level of power consumption places such a system in the ultra-low-power category suitable for edge AI applications and battery-powered devices.
Programming Strategies to Mitigate Against Drift
In ReRAM conductance levels can drift over time, and adjacent states may overlap, introducing noise. To tackle this, the team tested multiple programming strategies:
- Single-shot Set: Simple, fast, but inaccurate
- Iterative Set: More precise, but slower
- Iterative Reset: Useful for low conductance states
- Hybrid strategy: A blend of both, offering the best balance
The hybrid strategy proved most effective, reducing variability and improving long-term retention. After a 12-hour bake at 150°C (equivalent to 10 years at 75°C) the system still maintained over 90% of its accuracy.
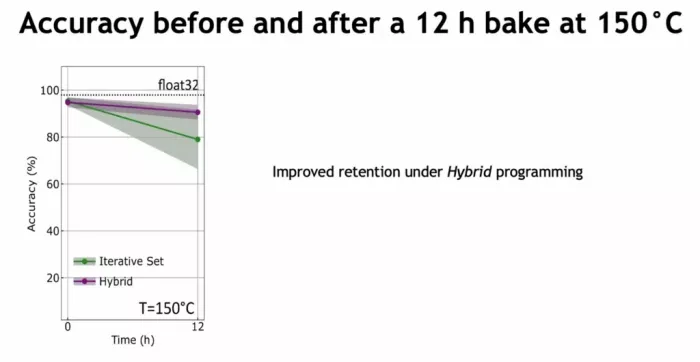
This is critical for commercial deployment, where temperature fluctuations and data longevity are real-world concerns.
Looking Ahead
This research points to a compelling future for AI at the edge:
- Learn locally: Devices can customize their behavior to individual users
- Stay secure: No data needs to be sent to the cloud
- Save time and energy: Minimal training and in-memory compute keep power low
- Scale affordably: Meta-training can be centralized and shared across devices
And because the platform uses ReRAM, the entire system benefits from ultra-low standby power and reduced silicon area.
This work is more than a proof of concept, it’s a signpost. As more AI applications move to the edge, we’ll need memory technologies that support not just inference, but real learning. ReRAM is emerging as one of the few candidates that can deliver on that vision, especially when paired with smart algorithms like MAML.
View the presentation, “On Chip Customized Learning on Resistive Memory Technology for Secure Edge AI” from the 2025 IEEE Symposium on VLSI Technology and Circuits here.
Related Semiconductor IP
Related Blogs
- Scaling Out Deep Learning (DL) Inference and Training: Addressing Bottlenecks with Storage, Networking with RISC-V CPUs
- Empowering your Embedded AI with 22FDX+
- Scaling AI Infrastructure with Next-Gen Interconnects
- Enhancing Edge AI with the Newest Class of Processor: Tensilica NeuroEdge 130 AICP
Latest Blogs
- Enabling Memory Choice for Modern AI Systems: Tenstorrent and Rambus Deliver Flexible, Power-Efficient Solutions
- Verification Sanity in Chiplets & Edge AI: Avoid the “Second Design” Trap
- Embedded Security explained: Cryptographic Hash Functions
- Arm and Google Cloud redefine agentic AI infrastructure with Axion processors
- A Bench-to-In-Field Telemetry Platform for Datacenter Power Management