QMC: Efficient SLM Edge Inference via Outlier-Aware Quantization and Emergent Memories Co-Design
By Nilesh Prasad Pandey 1, Jangseon Park 1, Onat Gungor 1, Flavio Ponzina 2, Tajana Rosing 1
1 University of California San Diego
2 San Diego State University
Abstract
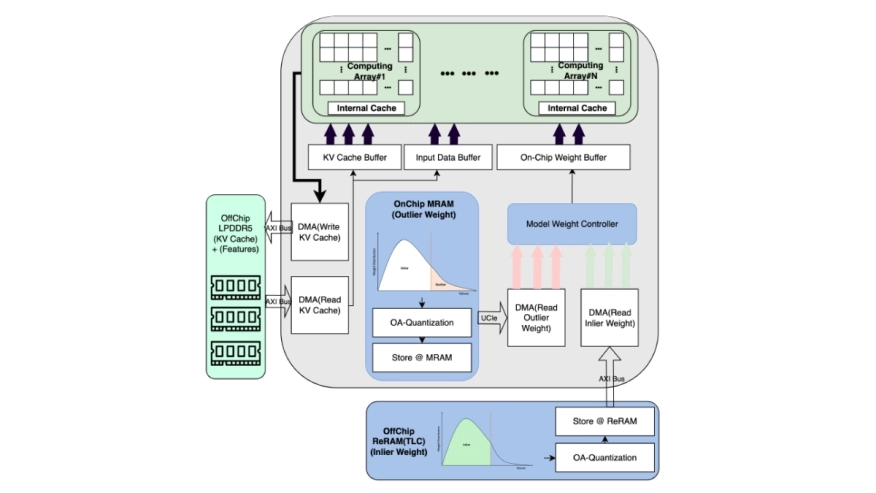
Deploying Small Language Models (SLMs) on edge platforms is critical for real-time, privacy-sensitive generative AI, yet constrained by memory, latency, and energy budgets. Quantization reduces model size and cost but suffers from device noise in emerging non-volatile memories, while conventional memory hierarchies further limit efficiency. SRAM provides fast access but has low density, DRAM must simultaneously accommodate static weights and dynamic KV caches, which creates bandwidth contention, and Flash, although dense, is primarily used for initialization and remains inactive during inference. These limitations highlight the need for hybrid memory organizations tailored to LLM inference. We propose Outlier-aware Quantization with Memory Co-design (QMC), a retraining-free quantization with a novel heterogeneous memory architecture. QMC identifies inlier and outlier weights in SLMs, storing inlier weights in compact multi-level Resistive-RAM (ReRAM) while preserving critical outliers in high-precision on-chip Magnetoresistive-RAM (MRAM), mitigating noise-induced degradation. On language modeling and reasoning benchmarks, QMC outperforms and matches state-of-the-art quantization methods using advanced algorithms and hybrid data formats, while achieving greater compression under both algorithm-only evaluation and realistic deployment settings. Specifically, compared against SoTA quantization methods on the latest edge AI platform, QMC reduces memory usage by 6.3x-7.3x, external data transfers by 7.6x, energy by 11.7x, and latency by 12.5x when compared to FP16, establishing QMC as a scalable, deployment-ready co-design for efficient on-device inference.
To read the full article, click here
Related Semiconductor IP
- ReRAM NVM in DB HiTek 130nm BCD
- UFS 5.0 Host Controller IP
- PDM Receiver/PDM-to-PCM Converter
- Voltage and Temperature Sensor with integrated ADC - GlobalFoundries® 22FDX®
- 8MHz / 40MHz Pierce Oscillator - X-FAB XT018-0.18µm
Related Articles
- Pyramid Vector Quantization and Bit Level Sparsity in Weights for Efficient Neural Networks Inference
- FPGA-Accelerated RISC-V ISA Extensions for Efficient Neural Network Inference on Edge Devices
- An efficient way of loading data packets and checking data integrity of memories in SoC verification environment
- AI Edge Inference is Totally Different to Data Center
Latest Articles
- An FPGA-Based SoC Architecture with a RISC-V Controller for Energy-Efficient Temporal-Coding Spiking Neural Networks
- Enabling RISC-V Vector Code Generation in MLIR through Custom xDSL Lowerings
- A Scalable Open-Source QEC System with Sub-Microsecond Decoding-Feedback Latency
- SNAP-V: A RISC-V SoC with Configurable Neuromorphic Acceleration for Small-Scale Spiking Neural Networks
- An FPGA Implementation of Displacement Vector Search for Intra Pattern Copy in JPEG XS