From Principles to Practice: A Systematic Study of LLM Serving on Multi-core NPUs
By Tianhao Zhu †, Dahu Feng ‡, Erhu Feng †, Yubin Xia †
† Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University
‡ Department of Precision Instrument, Tsinghua University
Abstract
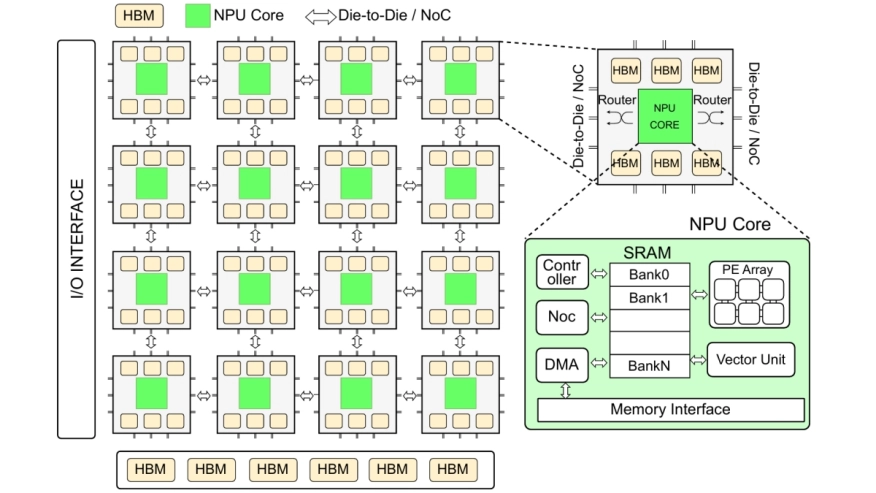
With the widespread adoption of Large Language Models (LLMs), the demand for high-performance LLM inference services continues to grow. To meet this demand, a growing number of AI accelerators have been proposed, such as Google TPU, Huawei NPU, Graphcore IPU, and Cerebras WSE, etc. Most of these accelerators adopt multi-core architectures to achieve enhanced scalability, but lack the flexibility of SIMT architectures. Therefore, without careful configuration of the hardware architecture, as well as deliberate design of tensor parallelism and core placement strategies, computational resources may be underutilized, resulting in suboptimal inference performance.
To address these challenges, we first present a multi-level simulation framework with both transaction-level and performance-model-based simulation for multi-core NPUs. Using this simulator, we conduct a systematic analysis and further propose the optimal solutions for tensor parallelism strategies, core placement policies, memory management methods, as well as the selection between PD-disaggregation and PD-fusion on multi-core NPUs. We conduct comprehensive experiments on representative LLMs and various NPU configurations. The evaluation results demonstrate that, our solution can achieve 1.32x-6.03x speedup compared to SOTA designs for multi-core NPUs across different hardware configurations. As for LLM serving, our work offers guidance on designing optimal hardware architectures and serving strategies for multi-core NPUs across various LLM workloads.
To read the full article, click here
Related Semiconductor IP
- NPU
- NPU IP Core for Edge
- NPU IP Core for Mobile
- NPU IP Core for Data Center
- NPU IP Core for Automotive
Related Articles
- Performance Evaluation of Inter-Processor Communication Mechanisms on the Multi-Core Processors using a Reconfigurable Device
- Performance Measurements of Synchronization Mechanisms on 16PE NOC Based Multi-Core with Dedicated Synchronization and Data NOC
- LLM Inference with Codebook-based Q4X Quantization using the Llama.cpp Framework on RISC-V Vector CPUs
- CD-PIM: A High-Bandwidth and Compute-Efficient LPDDR5-Based PIM for Low-Batch LLM Acceleration on Edge-Device
Latest Articles
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks