SPAD: Specialized Prefill and Decode Hardware for Disaggregated LLM Inference
By Hengrui Zhang 1, Pratyush Patel 2, August Ning 1, David Wentzlaf 1
1 Princeton University
2 University of Washington
Abstract
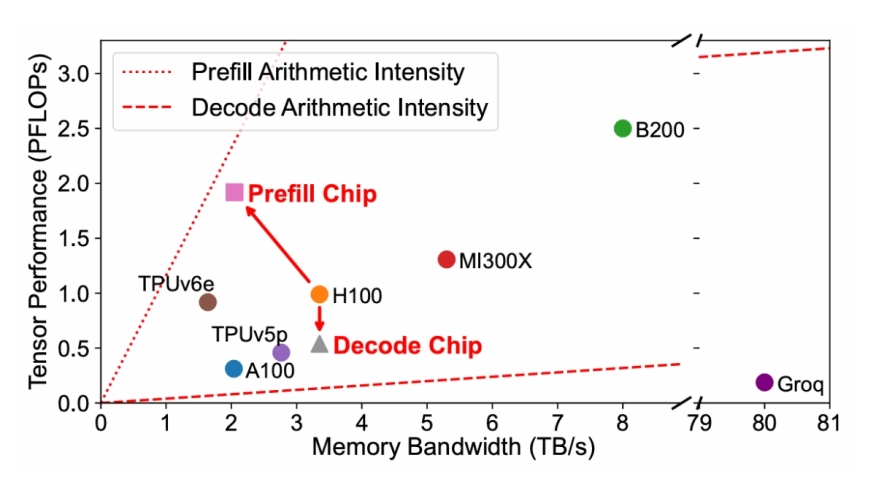
Large Language Models (LLMs) have gained popularity in recent years, driving up the demand for inference. LLM inference is composed of two phases with distinct characteristics: a compute-bound prefill phase followed by a memory-bound decode phase. To efficiently serve LLMs, prior work proposes prefill-decode disaggregation to run each phase on separate hardware. However, existing hardware poorly matches the different requirements of each phase. Current datacenter GPUs and TPUs follow a more-is-better design philosophy that maximizes compute and memory resources, causing memory bandwidth underutilization in the prefill phase and compute underutilization in the decode phase. Such underutilization directly translates into increased serving costs.
This paper proposes SPAD (Specialized Prefill and Decode hardware), adopting a less-is-more methodology to design specialized chips tailored to the distinct characteristics of prefill and decode phases. The proposed Prefill Chips have larger systolic arrays and use cost-effective GDDR memory, whereas the proposed Decode Chips retain high memory bandwidth but reduce compute capacity. Compared to modeled H100s, simulations show that the proposed Prefill Chips deliver 8% higher prefill performance on average at 52% lower hardware cost, while the proposed Decode Chips achieve 97% of the decode performance with 28% lower TDP.
End-to-end simulations on production traces show that SPAD reduces hardware cost by 19%-41% and TDP by 2%-17% compared to modeled baseline clusters while offering the same performance. Even when models and workloads change, SPAD can reallocate either type of chip to run either phase and still achieve 11%-43% lower hardware costs, demonstrating the longevity of the SPAD design.
To read the full article, click here
Related Semiconductor IP
- DC-DC Split-Pi Boost-Buck Converter
- Deep learning accelerator
- MIL-STD-1553 Controller IP
- UFS 5.x Device IP
- UCIe 3.x Controller IP
Related Articles
- VitaLLM: A Versatile and Tiny Accelerator for Mixed-Precision LLM Inference on Edge Devices
- LLMs for Secure Hardware Design and Related Problems: Opportunities and Challenges
- QiMeng: Fully Automated Hardware and Software Design for Processor Chip
- All-in-One Analog AI Hardware: On-Chip Training and Inference with Conductive-Metal-Oxide/HfOx ReRAM Devices
Latest Articles
- CHIA: An open-source framework for principled, agentic AI-driven hardware/software co-design research
- Croc: Training the Next Generation Chip Designers on Domain-Specific End-to-End Open Source Silicon
- Design and Development of a Neuromorphic Silicon Suite: PVT Sensing, Stochastic LIF Inference, On-Chip STDP Learning, and Crossbar Programming
- LLM4RTL: Tool-Assisted LLM for RTL Generation
- Towards Delta Aware Training: Efficient DNN Weight Storage for Resource-Constrained FPGAs