LLM Inference with Codebook-based Q4X Quantization using the Llama.cpp Framework on RISC-V Vector CPUs
By Saqib Akram, Ahmad Tameem, Khurram Mazher and Saad Bin Nasir
10xEngineers, Pakistan
1. Introduction
We utilize QuantX [MN25], our in-house hardware-aware quantization platform, to generate a CPU-friendly codebook-based quantization technique, Q4X, and demonstrate its effectiveness by integrating it into a private fork of the popular Llama.cpp [GtLc25] framework. We take into account the memory bound nature of LLM inference and design a compact 64-element codebook which is stored right on the CPU register file during the dequantization saving costly far-memory accesses. Q4X is integrated into Llama.cpp using hardware-friendly data packing and cache-aware vectorized kernels optimized for the RISC-V vector. The results are validated on a Milk-V Jupiter RISC-V board; achieving a better tradeoff on tokens/sec, model size and perplexity compared to the built-in techniques of similar order in Llama.cpp.
2. Quantization Techniques
In this section, we will take a closer look at the built-in quantization strategies ‘Q40’ and ‘Q4K’ from Llama.cpp, followed by a breakdown of the new ‘Q4X’ quantization strategy that we are proposing.
- Q40: Q40 (shown on the left side of Fig. 1b) is a legacy 4-bit quantization method in Llama.cpp. It works by using a rounding-to-nearest (RTN) operation on a group of 32 weights. For each group, the 4-bit weights and an FP16 scaling factor are packed into 18 bytes achieving 4.5 bits per weight (BPW).
- Q4K: Q4K is a more recent technique introduced in Llama.cpp that uses hierarchical scaling and asymmetric quantization. Here, 256 weight elements are grouped into a 144-byte block. This block contains 256 4-bit quantized values, a 2-byte global scale and minimum, and 6-bit scales and minimums for each chunk of 32 weights. Q4K also achieves a 4.5 BPW as illustrated in the middle of Fig. 1b.
- Q4X: Now, let’s dive into the proposed Q4X quantization strategy. As shown in Fig. 1a, Q4X is a codebook-based quantization technique designed for efficient inference on CPUs. A histogram is computed for each group of 64 weights in the weight matrix followed by learning 4 histograms that best represent all the historgrams of a complete matrix. These learned histograms undergo dimension reduction, resulting in 16 non-uniform samples chosen from each. The final representation is made up of 64 centroids—16 from each of the 4 learned histograms—which are grouped into a codebook for the weight matrix. For each group of 64 weight elements, Q4X stores a 2-byte scale factor, a 2-bit codebook index that represents the best matching learned histogram for that group, and the 4-bit centroid indices for each of the 64 elements. This approach makes Q4X a 4.28 BPW (with the 2-bit codebook indices of multiple groups padded together for byte alignment) method, as illustrated on the right side of Fig. 1b.
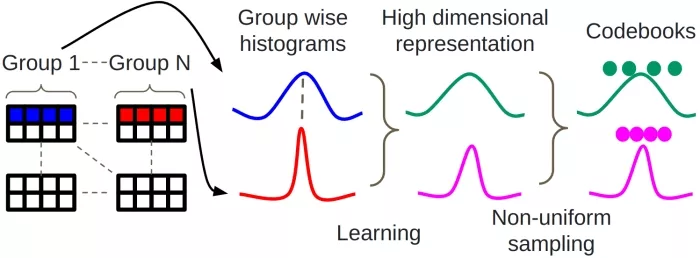
(a) Functional illustration of the Q4X quantization strategy showing the histogram learning process and non-uniform quantization for dimension reduction.
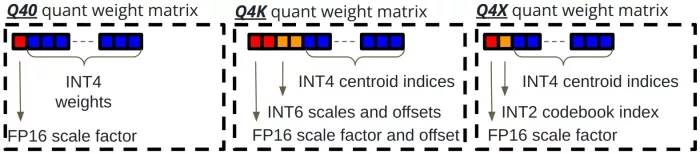
(b) Illustration of the quantized weight matrices for a single group of Q40, Q4K and Q4X.
Figure 1: (a) Description of the proposed Q4X quantization strategy and (b) the resulting quantized matrices for Q40, Q4K and Q4X.
The final file size, run time performance in terms of tokens per second and perplexity computed on Wikitext v2 test subset with nctx = 2048 is shown in Table 1. Q4X outperforms Q40, achieving a higher token throughput for a reduced model size and lower perplexity score. Similarly, Q4X has a better model size and throughput than Q4K. The perplexity score, however, is lower for Q4K given its use of two-level scaling for the weights and a smaller sub-group size of 32 compared to the group size of 64 used in Q4X.
3. Hardware-aware Kernel Design
Achieving a higher runtime performance requires an optimized dequantization kernel. We implemented the dequantization kernel based on quantized vector dot products. Hardware-aware optimizations were implemented on top of the baseline vectorization to achieve state-of-the-art inference performance for Llama 3.2 1B model on RVV using Llama.cpp.
- Data Packing for Maximum Cache Utilization: Quantized weight matrices, codebooks and scale factors are packed to achieve the right balance between vector register utilization and L2 cache hits. Data is prepacked to enhance spatial locality and relevant data structures are cache-line aligned. Cache tiling size is optimized to reduce cache misses.
- Optimized Placement of Intermediates and Codebooks: A large number of vector registers in RVV (32 scalable registers) allows us to increase vector register utilization for intermediate variables used within the dequantization kernel. Codebooks, thanks to their compact size, are also kept in the register file for dequantization of each group. Increased computation within the register files saves the costly data movement transactions to the main memory achieving faster inference.
The baseline scalar kernel peaks at 2.93 and 2.38 compared to 8.64 and 5.29 tokens/second achieved with our hardware-aware vectorized dequantization kernel in the prefill and decode, respectively. Performance trends, compiled through Clang, running with an 8-core RISC-V CPU on Milk-V Jupiter board are shown in Fig. 2a and 2b.
| Quantization configuration | BPW | File size (MiB) |
Prefill/Decode throughput (tokens/sec) |
Perplexity (Wikitext v2) |
|---|---|---|---|---|
| Unquantized FP16 | 16 | ∼2300 | 0.12 / 0.06 | 13.16 |
| Q40 | 4.5 | 727.75 | 6.03 / 4.28 | 15.22 |
| Q4K | 4.5 | 732.25 | 7.77 / 5.06 | 14.45 |
| Q4X | 4.28 | 702.38 | 8.64 / 5.29 | 14.67 |
Table 1: Comparison of the file size, run time and perplexity for Llama 3.2 1B instruction tuned model and its Q40, Q4K and Q4X quantized versions running on a Milk-V Jupiter board. For a fair comparison in perplexity, we used 8-bit RTN per-token quantization for the activation tensors for all quantization techniques emulated in QuantX.
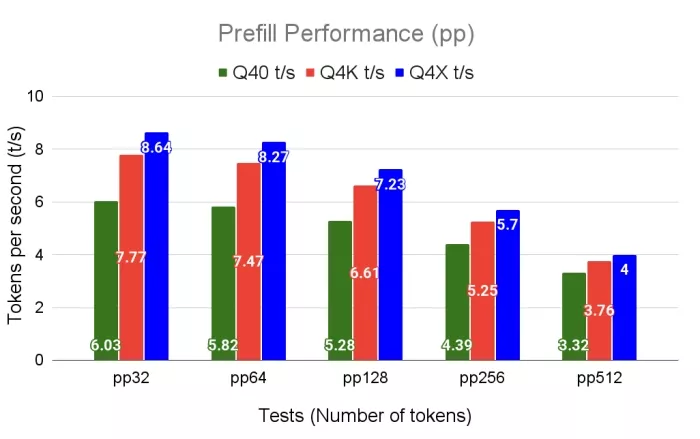
(a) Prefill throughput of Q40, Q4K, and Q4X across varying lengths.
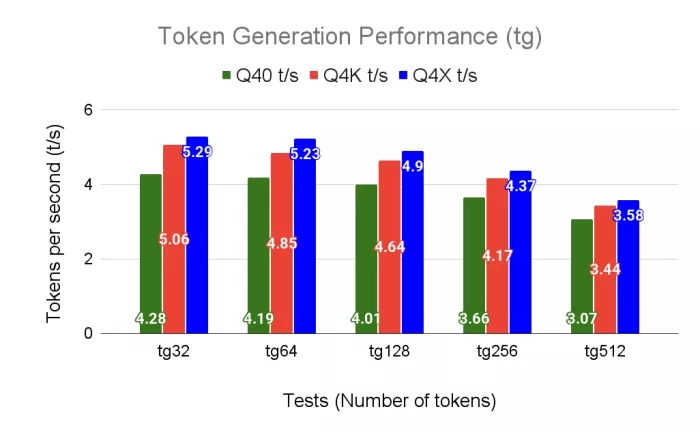
(b) Token generation (decode) throughput of Q40, Q4K, and Q4X across varying lengths.
Figure 2: Throughput performance comparison of Q40, Q4K, and Q4X in tokens per second.
4. Conclusion
In this post, we went over the design and implementation of Q4X, a codebook based quantization technique, on a RISC-V vector (RVV) CPU. We have successfully integrated it into the Llama.cpp framework by designing a hardware-aware dequantization kernel validated on Milk-V Jupiter RISC-V board. Our results show that Q4X outperforms the comparable Llama.cpp quantization techniques and achieves state-of-the-art inference performance on RVV using Llama.cpp framework.
References
[GtLc25] Georgi Gerganov and the Llama.cpp community. Llama.cpp: Efficient LLM inference in C/C++. https://github.com/ggml-org/llama.cpp, 2025.
[MN25] Khurram Mazher and Saad Bin Nasir. QuantX: A framework for hardware-aware quantization of generative AI workloads, 2025.
Related Semiconductor IP
- Highly scalable inference NPU IP for next-gen AI applications
- Multi-core capable 64-bit RISC-V CPU with vector extensions
- Multi-core capable 32-bit RISC-V CPU with vector extensions
- 64-bit CPU with RISC-V Vector Extension
- Higher‑Throughput NPU IP Core
Related Articles
- Pyramid Vector Quantization and Bit Level Sparsity in Weights for Efficient Neural Networks Inference
- Pie: Pooling CPU Memory for LLM Inference
- Top 5 Reasons why CPU is the Best Processor for AI Inference
- Bare-Metal RISC-V + NVDLA SoC for Efficient Deep Learning Inference
Latest Articles
- LIB-TRAP: Standard Cell Library Hardware Trojan Risk Assessment and Prevention
- Exploring Side-Channel Protections in Hardware Implementations of PQC ML-KEM Verification
- CVA6-RT: an Open-Source Time-Predictable RV64 Processor for Mixed-Criticality Systems
- CHIA: An open-source framework for principled, agentic AI-driven hardware/software co-design research
- Croc: Training the Next Generation Chip Designers on Domain-Specific End-to-End Open Source Silicon