A Persistent-State Dataflow Accelerator for Memory-Bound Linear Attention Decode on FPGA
By Neelesh Gupta 1, Peter Wang 1, Rajgopal Kannan 2 and Viktor K. Prasanna 1
1 University of Southern California, USA
2 DEVCOM Army Research Office, USA
Abstract
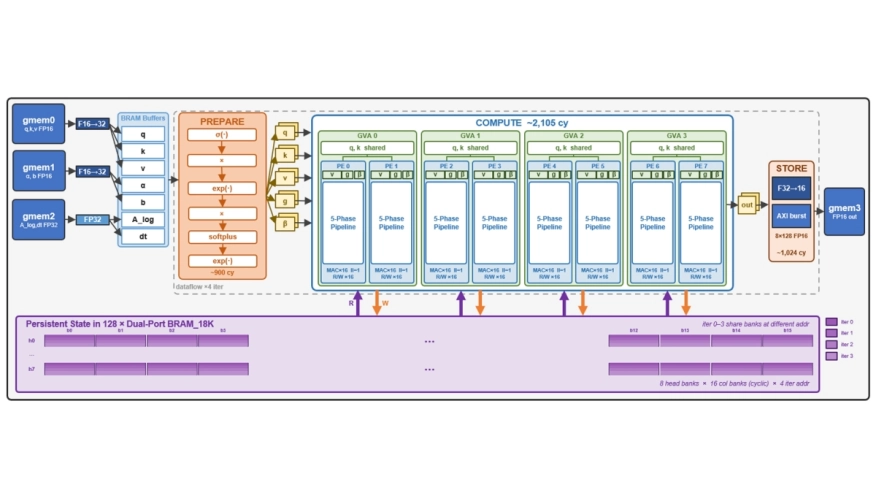
Gated DeltaNet (GDN) is a linear attention mech anism that replaces the growing KV cache with a fixed-size recurrent state. Hybrid LLMs like Qwen3-Next use 75% GDN layers and achieve competitive accuracy to attention-only models. However, at batch-1, GDN decode is memory-bound on GPUs since the full recurrent state must be round-tripped through HBM every token. We show that this bottleneck is architectural, not algorithmic, as all subquadratic sequence models exhibit arithmetic intensities below 1FLOP/B at decode time, making them more memory-bound than standard Transformers. We present an FPGA accelerator that eliminates this bottleneck by holding the full 2MB recurrent state persistently in on chip BRAM, converting the workload from memory-bound to compute-bound. Our design fuses the GDN recurrence into a five-phase pipelined datapath that performs only one read and one write pass over each state matrix per token, exploits Grouped Value Attention for paired-head parallelism, and overlaps preparation, computation, and output storage via dataflow pipelining. Weexplore four design points on an AMD Alveo U55C using Vitis HLS, varying head-level parallelism from 2 to 16 value-heads per iteration. Our fastest configuration achieves 63µs per token, 4.5× faster than the GPU reference on NVIDIA H100 PCIe. Post implementation power analysis reports 9.96W on-chip, yielding up to 60× greater energy efficiency per token decoded.
Index Terms — FPGA Accelerator, Linear Attention, Gated DeltaNet, LLM Decode, Dataflow Architecture
To read the full article, click here
Related Semiconductor IP
- UCIe D2D Adapter & PHY Integrated IP
- Low Dropout (LDO) Regulator
- 16-Bit xSPI PSRAM PHY
- MIPI CSI-2 CSE2 Security Module
- ASIL B Compliant MIPI CSI-2 CSE2 Security Module
Related Articles
- Interstellar: Fully Partitioned and Efficient Security Monitoring Hardware Near a Processor Core for Protecting Systems against Attacks on Privileged Software
- CANDoSA: A Hardware Performance Counter-Based Intrusion Detection System for DoS Attacks on Automotive CAN bus
- A Resource-Driven Approach for Implementing CNNs on FPGAs Using Adaptive IPs
- A Direct Memory Access Controller (DMAC) for Irregular Data Transfers on RISC-V Linux Systems
Latest Articles
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks