VMXDOTP: A RISC-V Vector ISA Extension for Efficient Microscaling (MX) Format Acceleration
By Max Wipfli 1, Gamze İslamoğlu 1, Navaneeth Kunhi Purayil 1, Angelo Garofalo 2, Luca Benini 1,2
1 IIS, ETH Zurich, Switzerland;
2 DEI, University of Bologna, Italy
Abstract
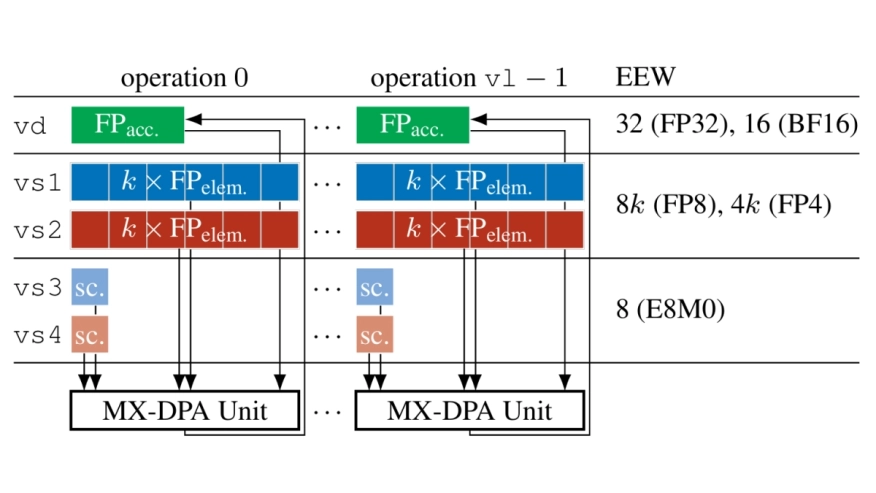
Compared to the first generation of deep neural networks, dominated by regular, compute-intensive kernels such as matrix multiplications (MatMuls) and convolutions, modern decoder-based transformers interleave attention, normalization, and data-dependent control flow. This demands flexible accelerators, a requirement met by scalable, highly energy-efficient shared-L1-memory vector processing element (VPE) clusters. Meanwhile, the ever-growing size and bandwidth needs of state-of-the-art models make reduced-precision formats increasingly attractive. Microscaling (MX) data formats, based on block floating-point (BFP) representations, have emerged as a promising solution to reduce data volumes while preserving accuracy. However, MX semantics are poorly aligned with vector execution: block scaling and multi-step mixed-precision operations break the regularity of vector pipelines, leading to underutilized compute resources and performance degradation. To address these challenges, we propose VMXDOTP, a RISC-V Vector (RVV) 1.0 instruction set architecture (ISA) extension for efficient MX dot product execution, supporting MXFP8 and MXFP4 inputs, FP32 and BF16 accumulation, and software-defined block sizes. A VMXDOTP-enhanced VPE cluster achieves up to 97 % utilization on MX-MatMul. Implemented in 12 nm FinFET, it achieves up to 125 MXFP8-GFLOPS and 250 MXFP4-GFLOPS, with 843/1632 MXFP8/MXFP4-GFLOPS/W at 1 GHz, 0.8 V, and only 7.2 % area overhead. Our design yields up to 7.0x speedup and 4.9x energy efficiency with respect to software-emulated MXFP8-MatMul. Compared with prior MX engines, VMXDOTP supports variable block sizes, is up to 1.4x more area-efficient, and delivers up to 2.1x higher energy efficiency.
To read the full article, click here
Related Semiconductor IP
- Real-time Pixel Processor for Vision applications
- 64-bit RISC-V core with in-order single issue pipeline. Tiny Linux-capable processor for IoT applications.
- Tiny, Ultra-Low-Power Embedded RISC-V Processor
- Low-Power Embedded RISC-V Processor
- Enhanced-Processing Embedded RISC-V Processor
Related Articles
- FPGA-Accelerated RISC-V ISA Extensions for Efficient Neural Network Inference on Edge Devices
- Extending RISC-V ISA With a Custom Instruction Set Extension
- Efficient Hardware-Assisted Heap Memory Safety for Embedded RISC-V Systems
- Bare-Metal RISC-V + NVDLA SoC for Efficient Deep Learning Inference
Latest Articles
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks