arithmetic IP
Filter
Compare
122
IP
from
42
vendors
(1
-
10)
-
Distributed Arithmetic FIR (DA-FIR) Filter Generator
- Variable number of taps up to 1024
- Multi-channel support (up to 32 channels)
- Polyphase interpolation/decimation filters
- Halfband filters

-
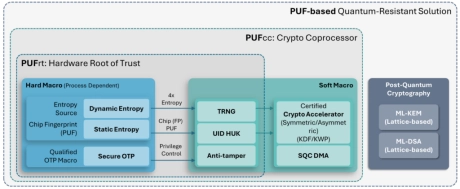
PUF-based Post-Quantum Cryptography (PQC) Solution
- PUFsecurity is proud to pioneer the world’s first PUF-based Post-Quantum Cryptography (PQC) solution, delivering cutting-edge, hardware-level security that sets a new standard.
- Our innovative solution integrates PUF technology with quantum-resistant cryptographic algorithms, ensuring robust key protection and seamless transition to a quantum-secure future.
-
RSA Signature Verification Accelerator - Compact RSA Signature Verification Accelerator for Constrained Devices
- Compact RSA Signature Verification Accelerator for Constrained Devices
-
High-Performance Hybrid Classical and Post-Quantum Cryptography
- The High-Performance Hybrid Cryptography IP core delivers accelerated support for both classical (RSA, ECC) and post-quantum (ML-KEM, ML-DSA) algorithms in a unified architecture optimized for maximum throughput.
-
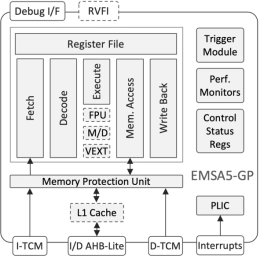
Vector-Capable Embedded RISC-V Processor
- The EMSA5-GP is a highly-featured 32-bit RISC-V embedded processor IP core optimized for processing-demanding applications.
- It is equipped with floating-point and vector-processing units, cache memories, and is suitable for concurrent execution in a multi-processor environment.
-
Asymmetric cryptographic accelerator
- The ACrypto Engine is an asymmetric cryptographic accelerator suitable for embedded application.
- It provides capability for basic arithmetic and frequently used operations. Along with driver, it is flexible to support popular upperlayer applications.
-
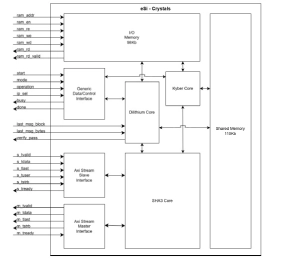
PQC CRYSTALS core for accelerating NIST FIPS 202 FIPS 203 and FIPS 204
- eSi-Crystals is a hardware core for accelerating the high-level operations specified in the NIST FIPS 202, FIPS 203 and FIPS 204 standards.
- It supports the Cryptographic Suite for Algebraic Lattices (CRYSTALS), it is lattice-based digital signature algorithm designed to withstand attacks from quantum computers, placing it in the category of post-quantum cryptography (PQC).
-
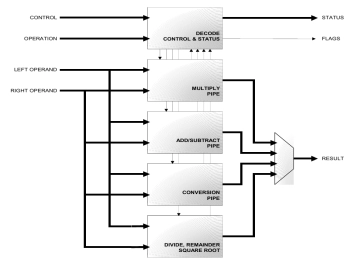
Double & Single Precision IEEE-754 complete FPU
- The A2FD is a fully synthesizable module implemented in Verilog RTL.
- It is a co-processor unit providing floating-point computation compliant with the ANSI/IEEE Std 754-1985, IEEE Standard for Binary Floating-Point Arithmetic (IEEE Standard).
- It is designed to provide high performance floating-point computation while minimizing die size and power. Pipelined, single-cycle throughput operation is available for all operations except Divide, Remainder and Square Root operations.
-
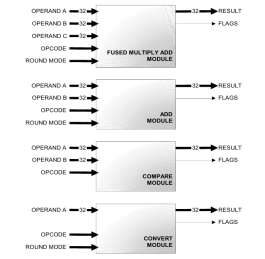
Very high performance IEEE-754 modules
- The A2FM product is a collection of floating-point execution units compliant with the ANSI/IEEE Std 754-1985, IEEE Standard for Binary Floating-Point Arithmetic (IEEE-754 Standard).
- The units are designed for high frequency, high throughput implementations. Each unit is implemented as a state less pipeline that can easily be integrated into a high-performance processor design.
-
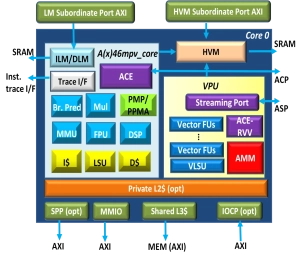
64 bit RISC-V Multicore Processor with 2048-bit VLEN and AMM
- 2 different packages with or without vector: AX46MPV, AX46MP
- in-order dual-issue 8-stage CPU core with up to 2048-bit VLEN
- Symmetric multiprocessing up to 16 cores
- Private Level-2 cache
- Shared L3 cache and coherence support