Sensitivity-Aware Mixed-Precision Quantization for ReRAM-based Computing-in-Memory
By Guan-Cheng Chen 1, Chieh-Lin Tsai 2, Pei-Hsuan Tsai 1, Yuan-Hao Chang 2
1 National Cheng Kung University, Tainan, Taiwan
2 National Taiwan University, Taipei, Taiwan
Abstract
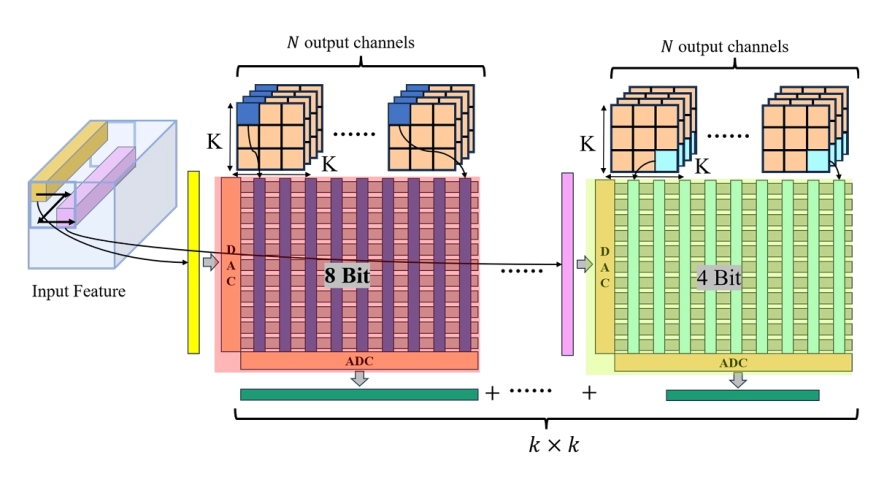
Compute-In-Memory (CIM) systems, particularly those utilizing ReRAM and memristive technologies, offer a promising path toward energy-efficient neural network computation. However, conventional quantization and compression techniques often fail to fully optimize performance and efficiency in these architectures. In this work, we present a structured quantization method that combines sensitivity analysis with mixed-precision strategies to enhance weight storage and computational performance on ReRAM-based CIM systems. Our approach improves ReRAM Crossbar utilization, significantly reducing power consumption, latency, and computational load, while maintaining high accuracy. Experimental results show 86.33% accuracy at 70% compression, alongside a 40% reduction in power consumption, demonstrating the method's effectiveness for power-constrained applications.
To read the full article, click here
Related Semiconductor IP
- ASA Motion Link PHY
- Configurable CNN accelerator
- RISC-V Display Connectivity Subsystem (DCS)
- AES-GCM - Authenticated Encryption and Decryption
- AES-GCM Authenticated Encryption and Decryption
Related Articles
- VitaLLM: A Versatile and Tiny Accelerator for Mixed-Precision LLM Inference on Edge Devices
- Pyramid Vector Quantization and Bit Level Sparsity in Weights for Efficient Neural Networks Inference
- Assessing Design Space for the Device-Circuit Codesign of Nonvolatile Memory-Based Compute-in-Memory Accelerators
- A novel 3D buffer memory for AI and machine learning
Latest Articles
- Verification and Validation (V&V)-in-the-Loop for RISC-V Design: The Holistic Vision of BZL
- EPAC: A RISC-V Accelerator from the European Processor Initiative
- AceleradorSNN: A Neuromorphic Cognitive System Integrating Spiking Neural Networks and Dynamic Image Signal Processing on FPGA
- VitaLLM: A Versatile and Tiny Accelerator for Mixed-Precision LLM Inference on Edge Devices
- SCENIC: Stream Computation-Enhanced SmartNIC