PermuteV: A Performant Side-channel-Resistant RISC-V Core Securing Edge AI Inference
By Nuntipat Narkthong, Xiaolin Xu
Northeastern University
Abstract
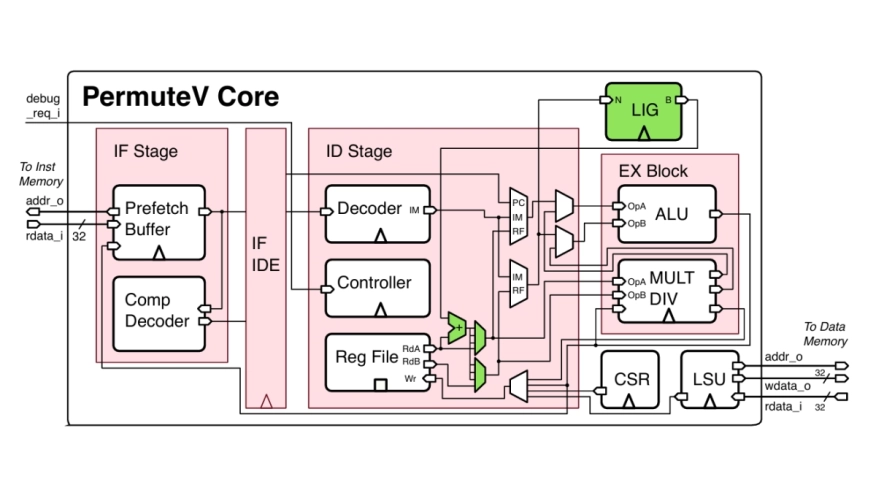
Edge AI inference is becoming prevalent thanks to the emergence of small yet high-performance microprocessors. This shift from cloud to edge processing brings several benefits in terms of energy savings, improved latency, and increased privacy. On the downside, bringing computation to the edge makes them more vulnerable to physical side-channel attacks (SCA), which aim to extract the confidentiality of neural network models, e.g., architecture and weight. To address this growing threat, we propose PermuteV, a performant side-channel resistant RISC-V core designed to secure neural network inference. PermuteV employs a hardware-accelerated defense mechanism that randomly permutes the execution order of loop iterations, thereby obfuscating the electromagnetic (EM) signature associated with sensitive operations. We implement PermuteV on FPGA and perform evaluations in terms of side-channel security, hardware area, and runtime overhead. The experimental results demonstrate that PermuteV can effectively defend against EM SCA with minimal area and runtime overhead.
Index Terms: Side-Channel, Defense, Microarchitecture, RISC-V
To read the full article, click here
Related Semiconductor IP
- RISC-V IOPMP IP
- RISC-V Debug & Trace IP
- Gen#2 of 64-bit RISC-V core with out-of-order pipeline based complex
- 64-bit RISC-V core with in-order single issue pipeline. Tiny Linux-capable processor for IoT applications.
- Tiny, Ultra-Low-Power Embedded RISC-V Processor
Related Articles
- AI Edge Inference is Totally Different to Data Center
- The Expanding Markets for Edge AI Inference
- FPGA-Accelerated RISC-V ISA Extensions for Efficient Neural Network Inference on Edge Devices
- RISC-V Based TinyML Accelerator for Depthwise Separable Convolutions in Edge AI
Latest Articles
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks