MING: An Automated CNN-to-Edge MLIR HLS framework
By Jiahong Bi, Lars Schütze and Jeronimo Castrillon
Technische Universitat Dresden, Germany
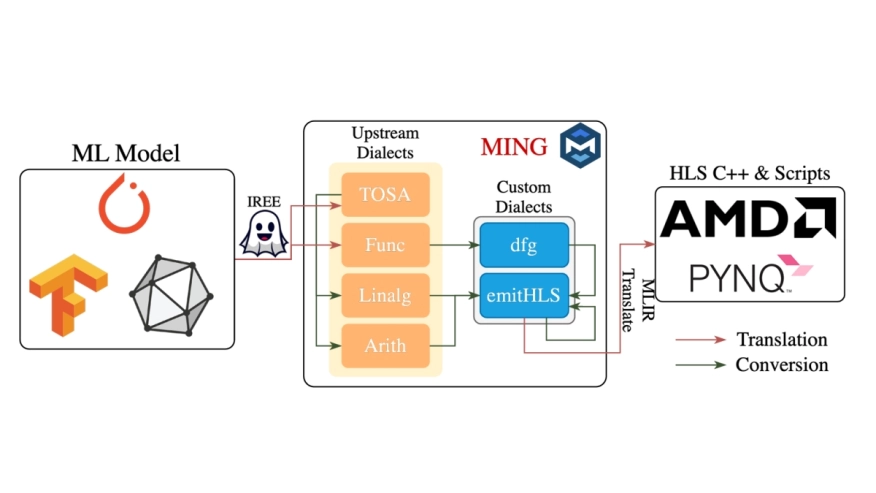
Abstract
Driven by the increasing demand for low-latency and real-time processing, machine learning applications are steadily migrating toward edge computing platforms, where Field-Programmable Gate Arrays (FPGAs) are widely adopted for their energy efficiency compared to CPUs and GPUs. To generate high-performance and low-power FPGA designs, several frameworks built upon High Level Synthesis (HLS) vendor tools have been proposed, among which MLIR-based frameworks are gaining significant traction due to their extensibility and ease of use. However, existing state-of-the-art frameworks often overlook the stringent resource constraints of edge devices. To address this limitation, we propose MING, an Multi-Level Intermediate Representation (MLIR)-based framework that abstracts and automates the HLS design process. Within this framework, we adopt a streaming architecture with carefully managed buffers, specifically designed to handle resource constraints while ensuring low-latency. In comparison with recent frameworks, our approach achieves on average 15x speedup for standard Convolutional Neural Network (CNN) kernels with up to four layers, and up to 200x for single-layer kernels. For kernels with larger input sizes, MING is capable of generating efficient designs that respect hardware resource constraints, whereas state-of-the-art frameworks struggle to meet.
Index Terms — Hardware Architectures, Compilers, High Level Synthesis, Quantized Neural Network, Edge Computing
To read the full article, click here
Related Semiconductor IP
- ReRAM NVM in DB HiTek 130nm BCD
- UFS 5.0 Host Controller IP
- PDM Receiver/PDM-to-PCM Converter
- Voltage and Temperature Sensor with integrated ADC - GlobalFoundries® 22FDX®
- 8MHz / 40MHz Pierce Oscillator - X-FAB XT018-0.18µm
Related Articles
- DDGEN: An Automated Device Driver Generation Tool for Embedded Systems
- An Automated Flow for Reset Connectivity Checks in Complex SoCs having Multiple Power Domains
- Modular design framework allows network processor software reuse
- Automated verification of configurable IP blocks
Latest Articles
- An FPGA-Based SoC Architecture with a RISC-V Controller for Energy-Efficient Temporal-Coding Spiking Neural Networks
- Enabling RISC-V Vector Code Generation in MLIR through Custom xDSL Lowerings
- A Scalable Open-Source QEC System with Sub-Microsecond Decoding-Feedback Latency
- SNAP-V: A RISC-V SoC with Configurable Neuromorphic Acceleration for Small-Scale Spiking Neural Networks
- An FPGA Implementation of Displacement Vector Search for Intra Pattern Copy in JPEG XS