aTENNuate: Optimized Real-time Speech Enhancement with Deep SSMs on RawAudio
By Yan Ru Pei, Ritik Shrivastava, FNU Sidharth (BrainChip)
Abstract
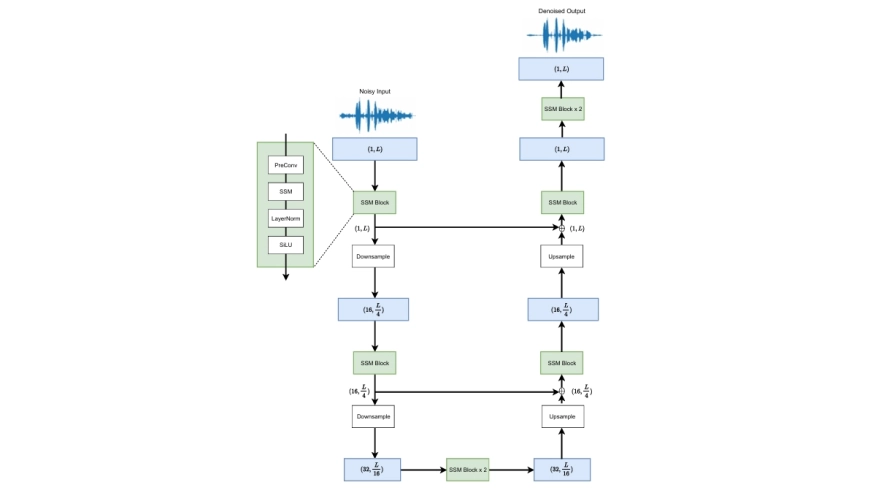
We present aTENNuate, a simple deep state-space autoencoder configured for efficient online raw speech enhancement in an end-to-end fashion. The network’s performance is primarily evaluated on raw speech denoising, with additional assessments on tasks such as super-resolution and de-quantization. We benchmark aTENNuate on the VoiceBank + DEMAND and the Microsoft DNS1 synthetic test sets. The network outperforms previous real-time denoising models in terms of PESQ score, parameter count, MACs, and latency. Even as a raw waveform processing model, the model maintains high fidelity to the clean signal with minimal audible artifacts. In addition, the model remains performant even when the noisy input is compressed down to 4000Hz and 4 bits, suggesting general speech enhancement capabilities in low-resource environments.
keywords: state-space models, autoencoder, denoising, super-resolution, de-quantization
To read the full article, click here
Related Semiconductor IP
Related Articles
- VLSI Based On Two-Dimensional Reconfigurable Array Of Processor Elements And Theirs Implementation For Numerical Algorithms In Real-Time Systems
- ASIC Implementation of a Speech Detector IP-Core for Real-Time Speaker Verification
- A Realtime 1080P30 H.264 Encoder System on a Zynq Device
- Understanding the Deployment of Deep Learning algorithms on Embedded Platforms
Latest Articles
- An FPGA-Based SoC Architecture with a RISC-V Controller for Energy-Efficient Temporal-Coding Spiking Neural Networks
- Enabling RISC-V Vector Code Generation in MLIR through Custom xDSL Lowerings
- A Scalable Open-Source QEC System with Sub-Microsecond Decoding-Feedback Latency
- SNAP-V: A RISC-V SoC with Configurable Neuromorphic Acceleration for Small-Scale Spiking Neural Networks
- An FPGA Implementation of Displacement Vector Search for Intra Pattern Copy in JPEG XS