David vs. Goliath: Can Small Models Win Big with Agentic AI in Hardware Design?
By Shashwat Shankar 1, Subhranshu Pandey 1, Innocent Dengkhw Mochahari 1, Bhabesh Mali 1, Animesh Basak Chowdhury 2, Sukanta Bhattacharjee 1, Chandan Karfa 1
1 Indian Institute of Technology, Guwahati, India
2 NXP USA, Inc.
Abstract
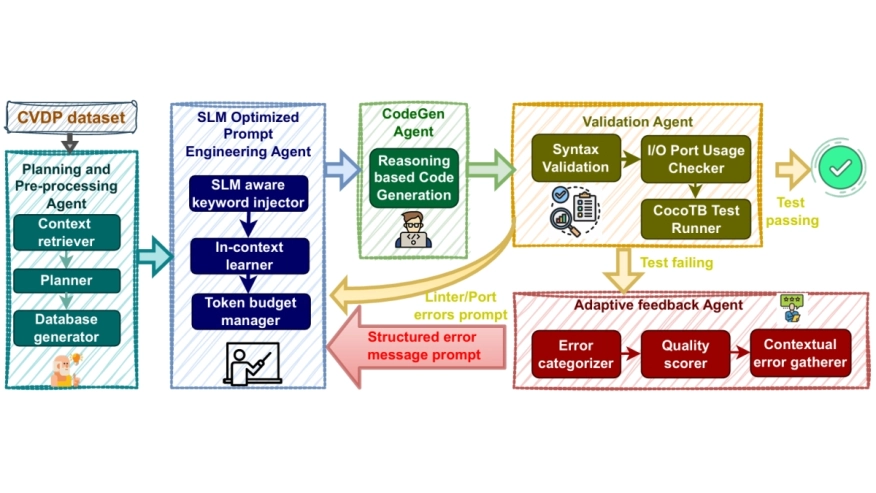
Large Language Model(LLM) inference demands massive compute and energy, making domain-specific tasks expensive and unsustainable. As foundation models keep scaling, we ask: Is bigger always better for hardware design? Our work tests this by evaluating Small Language Models coupled with a curated agentic AI framework on NVIDIA's Comprehensive Verilog Design Problems(CVDP) benchmark. Results show that agentic workflows: through task decomposition, iterative feedback, and correction - not only unlock near-LLM performance at a fraction of the cost but also create learning opportunities for agents, paving the way for efficient, adaptive solutions in complex design tasks.
Keywords: AI assisted Hardware Design, Agentic AI, Large Language Model, Small Language Model, Benchmarking
To read the full article, click here
Related Semiconductor IP
- DC-DC Split-Pi Boost-Buck Converter
- Deep learning accelerator
- MIL-STD-1553 Controller IP
- UFS 5.x Device IP
- UCIe 3.x Controller IP
Related Articles
- Optimizing Electronics Design With AI Co-Pilots
- The role of cache in AI processor design
- New PCIe Gen6 CXL3.0 retimer: a small chip for big next-gen AI
- Scaling AI Chip Design With NoC Soft Tiling
Latest Articles
- CVA6-RT: an Open-Source Time-Predictable RV64 Processor for Mixed-Criticality Systems
- CHIA: An open-source framework for principled, agentic AI-driven hardware/software co-design research
- Croc: Training the Next Generation Chip Designers on Domain-Specific End-to-End Open Source Silicon
- Design and Development of a Neuromorphic Silicon Suite: PVT Sensing, Stochastic LIF Inference, On-Chip STDP Learning, and Crossbar Programming
- LLM4RTL: Tool-Assisted LLM for RTL Generation