Prototyping Mesh-of-Tree NOC Based MPSOC on Mesh-of-Tree FPGA Devices
Mazen Khaddour, Omar Hammami (ENSTA-ParisTech)
Abstract :
Multi-Processors System on Chip (MPSoC) is a growing industry; studies predict the use of hundreds of processors in one system, however the impact of targeted device internal structure on the implementation of such systems has not been studied thoroughly. We developed a a Network on Chip (NoC) with Mesh of Trees topology that has been proposed in literature, this particular topology is implemented into 2 different FPGA devices the Xilinx Virtex4 and the AboundLogic Raptor 750. The Raptor FPGA has a mesh of trees as routing interconnect structure, while the Virtex 4 routing is based on a Manhattan Structure. Our paper examines the potential benefits of the correspondence in topology of logical and physical interconnect. Results shows an important boost in performance level but less gain in resources usage.
Keywords – AboundLogic Raptor 750, FPGA, Mesh of Trees, MPSoC, NoC, Virtex4.
I. INTRODUCTION
Network on Chip is becoming the standard interconnect to be used in Multi-core and Multi- Processors System on Chip because it provides higher performance while consuming less power and less resources [1]. Particularly because of its customizable topology it can be adapted to best suite any communication scenario between different cores. In this paper we examine the impact of targeted FPGA devices on implementation properties; the case study includes a NoC with Mesh of Trees topology [6-7] a complete shared memory MPSoC is built around this NoC and implemented onto two different FPGA Devices, the impact of targeted device has not been studied thoroughly before [2-7], we compare the effect of different FPGA global routing structures; the first FPGA has a routing based on island style structure: the Virtex4 [18], the second FPGA uses Mesh of Tree hierarchical Multi-Level structure: the AboundLogic Raptor 750, the second structure uses 3D Multi-layer [17] and provides several advantages like higher density logic, shorter delays [2-5,17] and better scalability. The paper is organized as follows: In section 2 we briefly present the routing structure of the used FPGAs, in section 3 we explain the implemented design, in section 4 we present our design methodology, in section 5 we present obtained results and finally we conclude in section 6.
II. FPGA ROUTING STRUCTURES
A. Xilinx Virtex 4 FPGA Structure
The Xilinx Virtex 4 programmable routing structure [18] consists of a matrix of programmable CLB
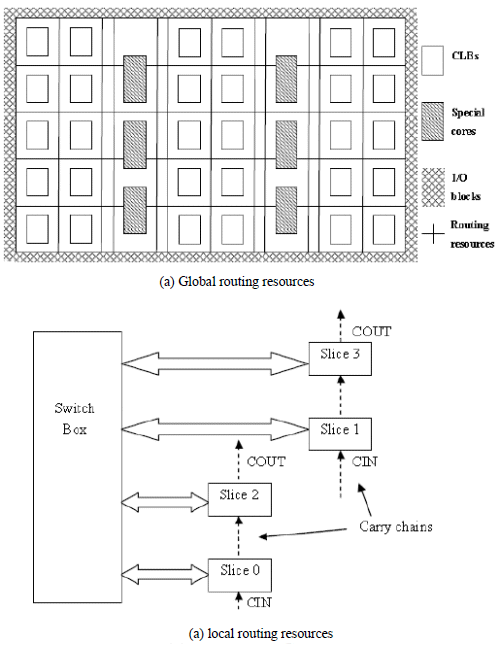
Figure1 : Virtex 4 routing structure
blocks that are connected via a number of global routing resources (wires), each CLB contains its own local routing resources and 4 slices. Each slice has 2 4-input LUT and 2 Flip Flops. 90% of FPGA area is dedicated for routing resource (wires and switch boxes). Figure 1 show global and local routing structure of the Virtex 4 FPGA B. Abound Logic Raptor750 FPGA Structure Figure 2 illustrates the Mesh of Tress Hierarchical structure of the Raptor FPGA routing interconnects that connects logical programmable elements MFC into each other to form the overall design. Where Multi-Function Cells MFC are organized into groups and groups are organized into clusters and so on, specialized units exists at different levels such as DSP48 and distributed memory units.
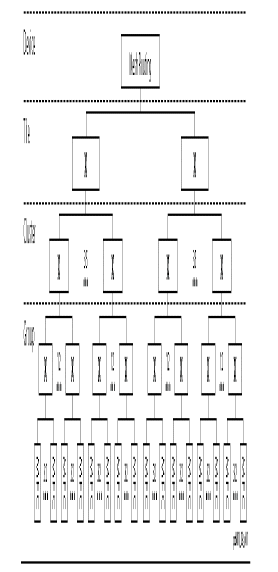
Figure 2: Raptor 750 Global routing structure
Local routing resources are implemented on the same plan of logical units while global routing resources are implemented on Multi-level Metal layers helping increase logical density and simplifying scalability.
III. IMPLEMENTED SYSTEM
C. Design Overview
Implemented MPSoC is presented in Figure 3 showing a MPSoC with N shared memory block units as slaves and N master PE (Processing Elements) Tiles interconnected by the Network on Chip (NoC) under test. The NoC architecture is illustrated in Figure 4, figure 4a shows the original MoT proposed in [6] while figure 4b shows the modified area efficient Hybrid MoT [7].
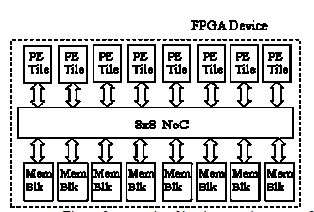
Figure 3: example of implemented systems; 8 PE(Processing Elements) connected to 8 shared Memory Blocks (Mem Blk)
Each PE Tile consists of a Traffic Generator to emulate a Processor activities and an OCP interfacing unit to connect to the NoC, we designed traffic generators based on NoC OCP-IP microbenchmark [8-9] in order to provide a platform
independent PE instead of using heterogeneous soft-core platform dependent processors, memory blocks contains a memory block (1Kbytes in our test), a memory controller and an OCP interface to connect to the NoC.
The used NoC topology was first proposed in [6] to achieve a high throughput for uniformly distributed traffic, it was modified in [7] to provide a more area efficient design while marginally losing performance.
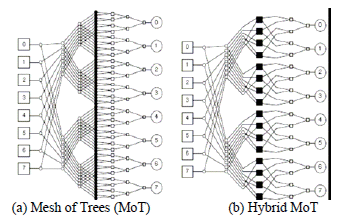
Figure 4: Implemented NoC architctures
Both topologies where implemented into the two FPGA devices with various NxN master and slave numbers, Table 1 shows implemented configuration and the number of used switches to build the NoC.
Table1: Implemented Master X Slave MPSoC Configurations and number of NoC switches for both NoC Architcture
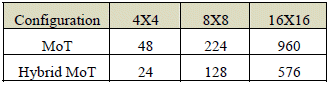
IV. DESIGN METHODOLOGY
Figure 5 shows the general flow of our design methodology for the Abound Logic FPGA
Figure 5: Design Methodology Flow for the Raptor FPGA
The same flow is vhdl files are re-used with minor platform dependent changes like memory basic blocks
V. RESULTS
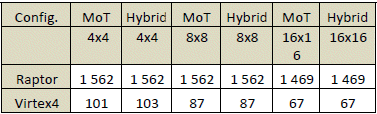
Results are limited to NoC Modeling tests; Synthesis resource usages per design configuration are presented in Figure 7 with a comparison between the two devices. While maximal frequencies indicated after Place and Route are illustrated in Table 2.
Table2: Maximum Frequencies after Place and Route on Virtex 4 FX140 and Raptor750 FPGAs for different design configurations
Results show an interesting advantage for Raptor 750 FPGA of up to 40% less Flip Flops (figure 6a) and 15% less LUT (figure 6b) usage for the same design.
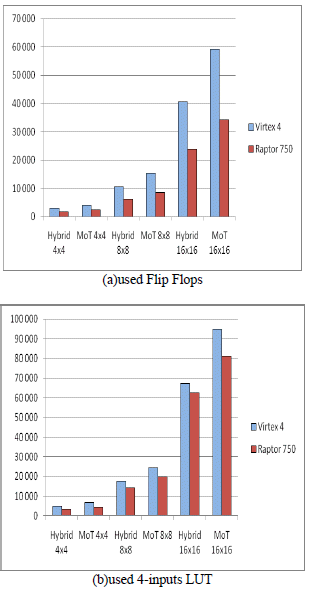
Figure 6: Used resources for different design configurations on Virtex4 and Raptor750 FPGAs
VI. CONCLUSION AND FUTURE WORK
We implemented various configurations of Multi- Processors with particular interconnect architecture on Abound Logic Raptor 750 and Xilinx Virtex4 FX140 FPGAs, primary results show very promising performance for the Raptor FPGA that has a similar structure to our designs architecture allowing up to 15 times faster performance, however more work is still to be done to answer fundamental questions about the impact of the particular structure of a given platform (the Raptor FPGA) on Multi-processors systems, this includes:
- Implementing a more complex and complete Multi-Processors system and evaluating it with real life applications.
- Implementing other interconnect architectures on the Raptor FPGA to evaluate the general impact of its particular structure in all case and not only in favorable situation.
- Other analysis on power and energy consumption.
REFERENCES
[1]- Radu Marculescu, Umit Y. Ogras, Li-Shiuan Peh, Natalie Enright Jerger, and Yatin Hoskote, “Outstanding Research Problems in NoC Design:System, Microarchitecture, and Circuit Perspectives†Ieee Transactions On Computer- Aided Design Of Integrated Circuits And Systems, Vol. 28, No. 1, January 2009
[2]- Zied Marrakchi, Hayder Mrabet, Emna Amouri, Habib Mehrez: “Efficient tree topology for FPGA interconnect network. ACM Great Lakes Symposium on VLSI†2008: 321-326
[3]- Zied Marrakchi, Hayder Mrabet, Christian Masson, Habib Mehrez: “Mesh of Tree: Unifying Mesh and MFPGA for Better Device Performancesâ€. NOCS 2007: 243-252
[4]- Hayder Mrabet, Zied Marrakchi, Pierre Souillot, Habib Mehrez: Performances improvement of FPGA using novel
[5]- Marrakchi, Z.; Farooq, U.; Parvez, H.;. Mehrez, H “Comparison of Tree-based and Mesh-based coarse-grained FPGA architectures†; Microelectronics (ICM), 2009 International Conference on
[6]- Balkan, A.O. Gang Qu Uzi Vishkin, “Application-specific Systems, Architectures and Processors, 2006. ASAP '06. International Conference on†IEEE.
[7]- Balkan, A.O. Gang Qu Uzi Vishkin, “An areaefficient high-throughput hybrid interconnection network for single-chip parallel processing†DAC '08: Proceedings of the 45th annual Design Automation Conference, ACM 2008.
[8]- OCP-IP Network-on-chip Benchmarking Specification Part 1: Application modelling and hardware description v.1.0. May 23rd, 2008. http://www.ocpip.org/
[9]- OCP-IP Network-on-chip Benchmarking Specification Part 2: Micro-benchmark Specification v.1.0. May 23rd, 2008. http://www.ocpip.org/
[10]- “Raptor User Guideâ€, UG001 (v0.9) – December, 2009, Abound Logic.
[11]- “mCompile User Guideâ€, UG002 (v1.2) – April, 2010, Abound Logic 2010.
[12]- Hermes NoC, http://www.inf.pucrs.br/~gaph/Projects/Hermes/He rmes.html
[13]- SONICS http://www.sonicsinc.com/
[14]- www.opencores.org
[15]- www.opensparc.net
[16]- Atlas - An Environment for NoC Generation and Evaluation http://www.inf.pucrs.br/~gaph/AtlasHtml/AtlasInd ex_us.html
[17]- Raphael Rubin, Andre DeHon "Design of FPGA Interconnect for Multilevel Metalization"
[18]- B. Dixon and C. Stroud, “Analysis and Evaluation of Routing BIST Approaches for FPGAs,†Proc. IEEE North Atlantic Test Workshop, pp. 85-91, 2007.
Related Semiconductor IP
- NPU IP Core for Mobile
- NPU IP Core for Edge
- Specialized Video Processing NPU IP
- HYPERBUS™ Memory Controller
- AV1 Video Encoder IP
Related White Papers
- An HDTV SoC Based on a Mixed Circuit-Switched / NoC Interconnect Architecture (STBus/VSTNoC)
- A SystemC/TLM based methodology for IP development and FPGA prototyping
- Performance Measurements of Synchronization Mechanisms on 16PE NOC Based Multi-Core with Dedicated Synchronization and Data NOC
- Multi-FPGA NOC Based 64-Core MPSOC: A Hierarchical and Modular Design Methodology
Latest White Papers
- Ramping Up Open-Source RISC-V Cores: Assessing the Energy Efficiency of Superscalar, Out-of-Order Execution
- Transition Fixes in 3nm Multi-Voltage SoC Design
- CXL Topology-Aware and Expander-Driven Prefetching: Unlocking SSD Performance
- Breaking the Memory Bandwidth Boundary. GDDR7 IP Design Challenges & Solutions
- Automating NoC Design to Tackle Rising SoC Complexity