Increased Verification Productivity through extensive Reuse
Abstract:
With today’s functional verification challenge outstripping the design challenge in terms of manpower, complexity and sheer time to complete, it is necessary to ensure that we reuse verification as extensively as is possible. There are three dimensions to this reuse challenge:
1. We must reuse firstly across abstraction levels so that the verification environment that is used to verify the initial abstract C++ models can also be used in its entirety to verify the subsequent revised models i.e. SystemC to RTL to Gates to Silicon.
2. We must ensure that module level verification environments can be completely reused in sub system and system level verification, since it is most effective to find module level bugs during module level verification. This requires the environment to be reusable across simulation platforms from software simulators to emulators to actual silicon.
3. Finally the verification environment must be maximally reused from design to design. This requires the use of generic Verification Components as well as consistent application of a specific methodology.
This paper describes a verification reuse methodology using Verisity’s Specman Elite tool suite with the ‘e’ Verification language. Taken together they fully address each dimension of the reuse challenge.
1. Introduction
The ‘e’ language is the means by which verification environments can be described for execution with Verisity's Specman Elite tool. Some unique features of ‘e’ include a combination of object oriented and constraint oriented mechanisms for the specification of data formats and interdependencies, unique mechanisms of inheritance, and an efficient combination of interpreted and compiled code. Please see [i] for more details on those unique features and their suitability for hardware verification.
One of the fundamental basics of design and verification reuse is the standardization of interfaces. This has resulted in a number of interface and bus protocols that are used to connect different entities together.
The logical conclusion for verification is to organize testbench components around those interfaces. Those components can then be used to verify multiple entities which have a particular interface.
A specific collection of ‘e’ files that are used together to address one particular verification interface or protocol is called an ‘e’ verification component (eVC). An eVC contains code to generate legal and interesting traffic, check the protocol and measure functional coverage. eVCs enjoy widespread use and can be commercially obtained or developed by verification engineers for inter-company reuse. One can envision building a testbench consisting of multiple eVCs possibly with some glue to perform end-to-end checking (e.g. for an AHB-to-APB bridge, one could use the AHB and APB eVC and add some scoreboard code for data checking).
The ‘e’ Reuse Methodology (eRM) standardizes how eVCs in particular, but in fact any testbench, should be architected, written and organized to ensure re-use in all of the dimensions previously mentioned. In order to enable efficient realization of and eRM verification environment, several important technology enhancements were added to the Specman Elite tool as well as some minor enhancements to the ‘e’ language. Finally eRM contains extensive training material as well as examples to educate and lead verification engineers by example.
2. Reuse across abstraction layers
To reuse verification components across multiple abstraction layers, the following requirements need to be addressed:
1) The stimulus should be modeled at as abstract a level as possible. This way the stimulus may be reused at all levels by using translation functions. For example, AHB traffic should be modeled at burst level, each burst containing a number of transfers. Actual tests should then be written using a further abstraction on top of bursts describing sequences of interesting activity.
2) Physical interfaces to the device under test should be partitioned into separate modules. These modules receive the traffic transactions and drive them at the desired layer (e.g. a RTL BFM would take the AHB burst and drive transfer by transfer on the bus using the exact AHB pin protocol, whereas a SystemC transaction level model might work with just the burst abstraction.). Passive modules will monitor the traffic at the desired layer abstraction, collect functional coverage measurements and perform checking and tracing.
3) The interface drivers for different abstraction levels should be easily switchable. This means that they need standard interfaces to traffic stream generators.
4) Functional coverage should also be modeled at stimulus level. Since stimulus is modeled in an abstract way, having functional coverage measurements at this level will enable to use the coverage definitions on all levels.
With all these points in mind, one can envision having a generic traffic generator, which can drive different interface modules to connect to the device under test, e.g. a transaction level interface for SystemC models, and HDL signal level interface for RTL models, and even a software interface to an FPGA board.
eRM suggests organizing those verification activities into separate components. It defines an agent as the topmost entity. The agent contains a sequence driver to generate traffic, a bus functional model (BFM) to drive the traffic onto the device under test and a monitor for functional coverage collection, protocol checking and traffic recovery.
The proposed architecture is outlined in Figure 1.
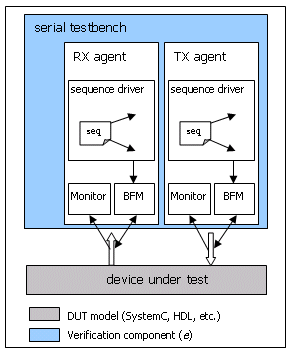
Figure 1 – eRM architecture
The interface between the traffic generator and the BFM is also standardized. There are two ways of communication, pull-mode and push-mode. In pull mode, the BFM will drive all outstanding stimulus and request new traffic from the traffic generator. In push mode the traffic generator will push the stimulus into the BFM and wait until the queues are empty. In most cases the pull mode is most appropriate.
The code snipped below shows a BFM in pull mode, requesting transfers from the sequence driver (traffic generator). This is the only interface between traffic generator and interface driver, which makes it very easy to replace the interface driver (BFM) to switch to a different abstraction layer.

3. Reuse from module to sub-system to system level
Module level verification has the fastest execution speed, the best observability and the smallest "verification space". This has led to a strong focus on module verification. In order to reap the benefits of those efforts at sub-system, system or chip level, the following aspects need to be considered:
1) Verification components which are able to drive traffic for module level verification should be able to passively monitor the interface activity, measure functional coverage and check for protocol violations as well as monitor the traffic for intermediate data checking.
2) Traffic generators should be able to synchronize with other traffic generators. This would allow the coordination of data on parallel channels in the system.
3) All coverage measurements and data checking should be based on passive monitors.
eRM recommends that agents can be either active or passive. The active agents will generate stimulus and actively drive it onto the device under test. Passive agents will not generate any traffic or drive DUT signals, but just monitor the interface, measure functional coverage, check for protocol violation and recover traffic data for data checking.
This change of agent functionality was introduced to handle the fact that in sub-systems some of the external interfaces are now internal interfaces, driven by other modules. Still we need to check the protocol and collect coverage on those interfaces. The introduction of a passive agent makes the step from module to sub-system transparent, since only the path to the interface needs to be changed.
The traffic generation is done in an entity called a sequence driver, which will generate and synchronize sequences. Sequences are a stream of traffic items encapsulating a high-level scenario of stimuli. This is done by generating items one after the other, according to some specific rules.
eRM defines a new sequence structure that has a set of predefined fields and methods. Sequences are hierarchical (i.e. they can contain sequences as well as basic data items). The sequence mechanism allows traffic to be generated and synchronized at the same time. This enables layering of sequences as well as construction of virtual sequence drivers, which can coordinate traffic on multiple interfaces
(e.g. to control multiple data channels). Combining all features mentioned above, we have shown the following flow from module to system level:
1) Module level:
- active agent on each interface, generating and driving stimulus
- protocol checking (assertions) and coverage collection in the agent monitor
- data checking was done by passing recovered data from the monitor to a separate data checking module (e.g. scoreboard)
2) Sub-system level:
- only external interfaces (i.e. external to the sub- system) are actively driven by agents
- driving agents are coordinated by virtual sequence drivers, allowing the reuse of already defined module sequences coordinated between different channels
- on internal interfaces, the agent kind is changed from active to passive (using a simple constraint)
- protocol checking (assertions) and coverage collection is performed in the agent monitor (all are reused from module verification)
- data checks are done by passing recovered data from the monitor of the external interface agents to a separate data checking module (e.g. scoreboard)
Following the flow outlined above it can be seen that apart from new end-to-end data checks, all verification infrastructure from module verification can be reused at sub-system or higher levels.
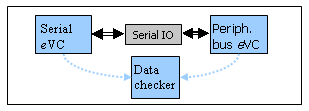
Figure 2 – module level example

Figure 3 – sub-system level example
4. Reuse from design to design
To increase reuse between project teams or from design to design one needs to address questions of verification infrastructure. This includes, but is not limited to, standardizing of the following aspects:
- naming of files and entities
- organization of files and directories
- debugging and visualization interface
- configuration and installation of verification components
- run-time coordination (i.e. multiple resets, end-of-test)
- structure of verification components (code architecture)
- test scenario generation and synchronization
eRM has defined rules for all of the above, also helped by additional new features in Specman Elite and the ‘e’ language. For example there are global message()/messagef() functions which can be called from any part of the verification component. Messages can be filtered using severity levels and can also be tagged to be sent to specific files. During verification runs, the message severity can be changed to get different levels of debug information. This can be localized to specific parts of the testbench, allowing us to just see specific messages of specific agent instances. While this is a simple concept, it is critical for reuse that all debug messages use a common facility like this so that they are printed according to a common format. It also allows an end user of an eVC to enable or disable specific messages of interest.
To elaborate on all of the mentioned aspects of infrastructure standardization would exceed the scope of this paper. The reader is referred to [ii] for detailed information.
5. eRM knowledge transfer
One main aspects of successful introduction of a new methodology is the ability to educate the users and industry on how to apply it. This has been addressed in eRM by providing not only training material and a complete eRM manual, but also verification component coding templates ('golden' example eVCs). In addition, standard documentation templates are provided to increase re-usability through consistent documentation.
Verisity also recently introduced a new static code analysis tool for ‘e’, which can also automatically check for eRM compliance.
6. Summary
We have shown how the methodology and technology introduced by Verisity's ‘e’ reuse methodology are able to address complex requirements of verification reuse. This methodology has been enthusiastically accepted and successfully applied on numerous projects in the industry.
7. References
[i] Y. Hollander, M. Morley and A. Noi. - The e Language: A fresh separation of concerns. - TOOLS Europe, March 12–14, 2001, Zurich.
[ii] Specman Elite, e Reuse Methodology (eRM) - Developer Manual, Version 4.2
Related Semiconductor IP
- NPU IP Core for Mobile
- MSP7-32 MACsec IP core for FPGA or ASIC
- UHF RFID tag IP with 3.6kBit EEPROM and -18dBm sensitivity
- NPU IP Core for Edge
- Specialized Video Processing NPU IP
Related White Papers
- Reduce SoC verification time through reuse in pre-silicon validation
- Layout compaction accelerates SoC design through hard IP reuse
- Maximizing Verification Productivity: eVC Reuse Methodology (eRM)
- Fast Design Productivity for Embedded Multiprocessor through Multi-FPGA Emulation: The case of a 48-way Multiprocessor with NOC
Latest White Papers
- Ramping Up Open-Source RISC-V Cores: Assessing the Energy Efficiency of Superscalar, Out-of-Order Execution
- Transition Fixes in 3nm Multi-Voltage SoC Design
- CXL Topology-Aware and Expander-Driven Prefetching: Unlocking SSD Performance
- Breaking the Memory Bandwidth Boundary. GDDR7 IP Design Challenges & Solutions
- Automating NoC Design to Tackle Rising SoC Complexity