HW/SW Interface Generation Flow Based on Abstract Models of System Applications and Hardware Architectures
Amin El Mrabti1, Frédéric Rousseau1, Hamed Sheibanyrad1, Frédéric Pétrot1, Romain Lemaire2, Jérôme Martin2, Emmanuel Vaumorin3, Maxime Palus3
1 TIMA Laboratory, 46 Ave Felix Viallet, 38031 Grenoble CEDEX, France {amin.elmrabti, hamed.sheibanyrad, rederic.rousseau, frederic.petrot}@imag.fr
2 CEA, LETI, MINATEC, F38054 Grenoble, France {romain.lemaire, jerome.marti}@cea.fr
3 Magillem Design Services, 4 rue de la pierre levée 75011 Paris, France {vaumorin, palus}@magillem.com
Abstract
The growing complexity of hardware architectures to meet the increasing performance requirements of the system applications reveals new programming problems, in particular when we aim to use a same hardware platform for different applications. Nowadays, in addition to several general purpose processors, a System-on-Chip may consist of a set of configurable IP (Intellectual Properties) components, connected by a Network-on-Chip (NoC). Programming such an architecture needs to define a set of different, but absolutely dependent, configuration codes. This definition makes very difficult the setting up of the generic generation flow of HW/SW interfaces, i.e. the adapters enabling an application to run on a given architecture.
In this paper, we present a code generation flow to deploy system applications over hardware architectures based on abstract descriptions. Our approach is defined in two steps: a front-end step which deals with abstract description of the application, the architecture (in extended IP-XACT), the mapping, and a back-end step which incorporates specific platform details necessary for HW/SW interface generation. A case study on the deployment of a complex 4G telecommunication application on a heterogeneous multi-core platform is also presented.
1. Introduction
The ever increasing complexity of applications requires complex hardware architectures to support application requirements. Technology evolution has contributed to the use of such architectures integrating high performance computing resources (CPU, DSP, hardware IP,…) as well as efficient communication resources (NoC, Bus,…). The deployment of an application on such architectures usually consists in producing several separated tasks that run on several resources. This is a difficult task since an efficient use of a large number of architecture resources is not trivial anymore, and also requires a separation between computing and communication functions. This difficulty increases with the complexity of hardware architecture and system application.
In order to efficiently perform architecture exploration on different resource allocation scenarios, and to make the hardware architecture reusable for some other application deployments, the software generation flow should be as independent as possible of application and architecture.
Thus, it is necessary to be able to represent applications and architectures by abstract models that do not contain all details of their implementations. These models are the inputs of the code generation flow. Moreover, the deployment supposes that the mapping between hardware resources and functionalities of computing and communication is known. Such code generation should provide a way to give mapping constraints, for instance to express that only one task is supposed to run on a processor. Therefore, the flexibility of a software generation flow depends on the expressivity of application, architecture and mapping models.
The traditional software design flow for multiprocessor architecture is presented on Fig. 1. It takes as inputs high abstraction level of application, architecture and mapping models. The objective is to generate executable code for programmable computing resources (CPU), and possibly information for compilation and link. The software generator may use software component libraries (Operating System, drivers, etc). For each processor, we obtain a binary code that is placed in memory sections belonging to the processor address spaces.
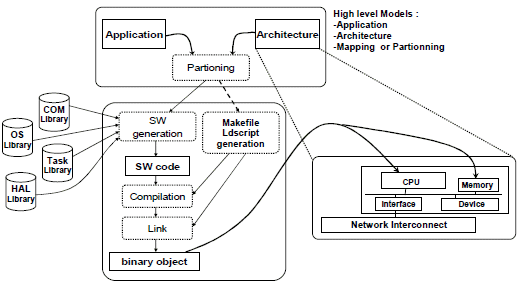
Figure 1. softaware code generation flow
It appears now that all architectures deploying complex applications are not only based on multiprocessor architecture, but also on a set of specific processing IP (Intellectual Properties) components. FAUST [22] and MAGALI [21] [24] platforms are real examples of such architectures using a Network-on-Chip (NoC) as the communication infrastructure. The interest of this kind of platform lies on the capability to configure communication and computing IPs (i.e. set register values). This kind of platform allows to launch execution scenarios locally by a communication interface component, or globally. The code generation becomes in this case the generation of configuration files that will be used to locally or globally configure IPs and scheduling scenarios. Indeed, the configuration for computing IPs consists in providing execution parameters for a defined functionality, and thus to program internal registers of the corresponding IP. For communication resources, configuration codes represent configurations for communication interfaces that link IPs with NoC routers. Some other configuration files and micro programs may need to be generated in order to orchestrate configuration scenarios that represent the overall application behavior.
In contrast to the traditional design flow of Fig. 1 which does not fit anymore with this IP-based architecture, the solution presented in this paper is a generic generation flow for HW/SW interfaces that supports various types of hardware architectures. We call HW/SW interface the set of needed information to operate the application functions on the architectural resources. Thus, HW/SW interfaces are the set of files needed to program IP-based architectures (configuration codes, micro programs) and multiprocessor architectures (executable binary codes). For these two types of architecture, HW/SW interfaces can be represented in different layers which will be described later in this paper. The flow is based on abstract descriptions of the application, the architecture and of the resources partitioning.. It is an approach that resembles to a classic compilation chain including two phases: a Front End and a Back End.
This paper is then organized as follows. Section 2 reviews some related works in the area of the automation of code generation. Section 3 introduces the different types of HW/SW interfaces. Section 4 presents our proposed HW/SW interface generation flow. Section 5 explains the Front End phase of the flow and the correspondent design environment. Section 6 details the Back End phase. Section 7 presents a case study to deploy a 3GPP-LTE (Long Term Evolution) application over a IP-based platform called MAGALI. Section 8 concludes this paper and gives outlooks on future works.
2. Related Works
The automation of HW/SW interfaces generation to deploy easily applications over architectures is an important research problem. Using abstract models of applications and architectures in the automation flow improves considerably the design time to market. Several methods for HW/SW code generation have been developed using KPN application models and multiprocessor target architecture [2] [3] [4]. In [4] [5] a tool called ESPAM (Embedded System level Platform synthesis and Application Mapping) uses a KPN application model, a multiprocessor architecture platform model and a mapping description, together with RTL components imported from an IP library to generate synthesizable VHDL and C/C++ code for the application tasks mapped onto cores. DSX [3], for Design Space eXplorer, uses abstract models to help mapping a multi threaded application on a multi processor architecture modeled with SocLib [6] components. DOL [2] standing for “Distributed Operation Layer” models applications as process networks. The semantic of the communication is a point-to-point first-in first-out (FIFO) channel. The architecture specification in DOL is multiprocessor architecture and contains structural data and performance information. The goal of using DOL is to achieve an efficient execution of the application on a heterogeneous MPSoC architecture by iterating the mapping process. The mapping language in DOL is specific to the mapping of a KPN application over a multiprocessor architecture. In [7] [8], a software design flow is proposed to generate the embedded software for simulation and performance estimation. The system architecture model is annotated with application and architecture parameters that can influence the global performance of the final system. Gaspard2 [9] is a tool implementing an MDA (Model Driven Architecture) based design flow. It allows modeling, simulation, test and code generation of the software and the hardware parts. The Gaspard flow focuses on intensive signal processing applications. The authors of [10] propose a mapping algorithm of an SDF (Synchronous Data Flow) application model over a NoC-based architecture [11]. The mapping is calculated by taking into account throughput constraints. SDF are used to model time-constrained multimedia applications. The model of architecture is a template of a tiles connected via a NoC. A tile must contain one processor, one memory, and a Network Interface. Syndex [12] (Synchronized Distributed EXecutives) is a system level CAD tool. An algorithm of deterministic image processing is described as a Data Flow Graph (DFG). An architecture graph describes a set of interconnected processors. The mapping consists in allocating and scheduling the different parts of the application algorithm over the architecture and to provide a timing graph. Then, the tool generates generic executives which are a set of micro calls. The M4 [13] macro processor transforms micro calls into compilable code for a specific target. PeaCE (Ptolemy extension as Codesign Environment) [14] is a codesign environment targeting multimedia applications. It begins with the specification of the application using formal models such as dataflow models and FSM. The architecture to be explored is also described (a predefined hardware platform or a new platform using a component library). PeaCE generates the partitioning code for each processing element.
The approach we present in this paper concentrates on generating HW/SW interfaces for different types of architectures (architectures with multiple CPUs, architectures with configurable processing elements such as hardware IPs) while most of the presented related works focus in multiprocessor architecture cases. We take into consideration complex data flow application that KPN and SDF are not able to express (section 5.2). We also propose a flexible mapping definition while most of the presented related works define a specific mapping language which depends on the application and the architecture types.
Some design flows are using proprietary languages for application, architecture and mapping description. The Metropolis [15] meta model specification is used to model the functionality, the architecture and the mapping. SystemC can be used to describe architecture and application too. In our approach we propose XML-based inputs to model the application and the architecture and to describe some extra information called meta data (The amount of data in a flow for example). The meta data can not be easily represented in a language like SystemC that targets execution. Our use of the XML notation is inspired from the IP-XACT [16] standard and because it is an interesting format to parse, to generate, and to store the system structure and parameters [17]. XML notation has already been used in some related works [2] [10].
3. HW/SW interface layers
3.1 HW/SW interface layers for multiprocessor architectures
In multiprocessor architectures (Fig. 2.b), HW/SW interfaces are modeled as a set of software layers (Fig. 2.a). The Application layer represents a set of communicating tasks. It uses a Task API to handle them. The task API layer includes primitives of task parallel programming (Posix Pthread API, MPI, etc). The implementation of task parallel programming primitives is based on primitives of the operating system (OS) layer. The communication layer provides a set of communication primitives which are going to be used in the Application layer to handle the communication between tasks. Communication primitives are basically primitives for reading and writing data and for synchronizing tasks. The OS is used to schedule tasks over a processor and it provides services for hardware resource management.
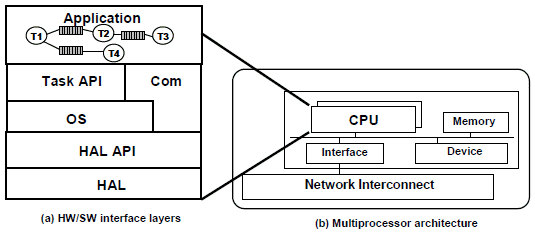
Figure 2. Hardware/Software interface for multiprocessor architecture
The hardware abstraction layer (HAL) contains the set of implemented services provided by the architecture to abstract it and handle it. The HAL API layer is an interface of the HAL layer and contains a set of primitives corresponding to the HAL services. As example, the switchcontext (CXT-type oldContext, CXT-type newContext) is a primitive taking part of the HAL API of the CPU component which enables context switching and may be used when scheduling tasks by the operating system. Primitives and services offered by the OS are built over the HAL API primitives. In [25] [26], a design flows are presented to generate the binary code which implements the HW/SW interface layers for multiprocessor architectures.
3.2 HW/SW interface layers for IP-based architectures
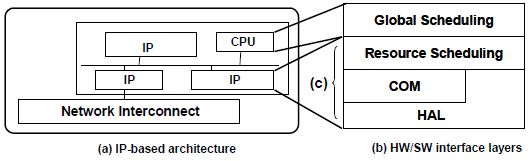
Figure 3. Hardware/Software interface for IP-based architecture
In architectures based on heterogeneous and configurable hardware IPs, HW/SW interfaces are modeled as a set of layers composed of configuration code and micro-programs. The “Global Scheduling” layer describes the application behavior based on the orchestration of the elementary behavior of the configurable IPs defined in the “Resource Scheduling” layer. The configuration stack (Fig. 3.c) abstracts a configurable IP and separates the computing and the communication functions [1] in two separate layers (respectively COM and HAL layers). The “Resource Scheduling” layer defines the IP behavior by scheduling a set of computing and communication configurations. The communication layer contains elementary communication configurations describing information about sending and receiving data and about synchronizing the global data flow. The HAL layer is different from the one presented for multiprocessor architectures. It still presents the elementary services and functions provided by the hardware resources. The HAL layer in this case is the set of tasks that the IPs can provide. Each task provided by an IP is defined by a set of parameters that initializes the registers of the IP to execute a well defined function.
3.3 HW/SW interface for MAGALI platform
MAGALI [21] [24] is an example of an IP-based architecture. In this NoC-based platform, each router could be interconnected to five nodes (4 routers and one resource).
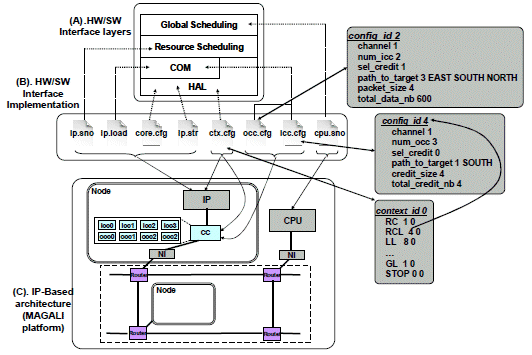
Figure 4. Hardware/Software interface for the MAGALI platform
Each node is composed of a network interface (NI), a “Configuration and Communication Controller” (CC Controller) which will ensure interfacing between the IPs and the NoC and one IP. Each CC Controller may include up to four input controllers (ICC) and four output controllers (OCC) for communication purpose. The NI is connected to the CC Controller and the CC Controller to the IP. The platform also contains one CPU which ensures the orchestration of communication and computation of all the nodes. The platform is programmed with several configuration files (Fig. 4.B) that constitute the HW/SW interface:
(1) The “Global Scheduling” is implemented in a file called “cpu.sno” which represents the global scenario of the application. The orchestration of IP configurations is implemented with micro programs using primitives such as loading a resource configuration (LOAD_RES
(2) The "Resource Scheduling" layer defines the behavior of the IP in MAGALI by calling elementary communication configurations (Communication layer) and computation configurations (HAL layer) of the IP. This layer is implemented in a file called “ip.sno” for each IP.
(3) The MAGALI platform implements this layer with ICC and OCC catalogs gathering basic configurations for communication, and micro programs which schedule them. The communication configurations are associated with the CC elements of the architecture. An ICC is configured to receive data from an OCC and an OCC element is configured to send data to an ICC.
An OCC configuration, defined in the “occ.cfg” file, explains how to send data from the IP directly connected to the OCC we want to configure, to other IPs. OCC configuration contains information such as the number of data to be transmitted, the path to follow through the NoC, the credit counter value and the identifier of the ICC that will receive the data. An ICC configuration, defined in the “icc.cfg” file, explains how to receive data by the IP directly connected to the ICC we want to configure. ICC configuration contains information such as the number of data to be received, the credit counter value and the identifier of the OCC that sends them. A file called “ctx.cfg” is used to schedule the ICC and the OCC configurations for an IP, using primitives such as RC: Request Configuration, LL: Local Loop, GL: Global Loop.
(4) The HAL layer in the MAGALI platform is implemented in a “core.cfg” file, for each IP, which initializes the IP parameters. Another file “ip.str” is also defined for each IP and contains parameters to configure the NoC so that the IP will be supported (number of ICCs and OCCs for example). The "ctx.cfg" file, which is the same that we mentioned in the communication layer, schedules the basic configurations defined in the "core.cfg” file to describe the IP behavior. In MAGALI, a configuration (core.cfg, icc.cfg, occ.cfg) is always indexed by an identifier which is referenced by a micro program (ctx.cfg).
This difficulty of manually configuring MAGALI to deploy an application is due to the high number of configuration files to develop (configuration of computing and communication, 80 files in the example detailed in the Experiment section), the high number of parameters to initialize in each file and the dependencies between all these files. The dependencies between parameters in various configuration files make the debug of an application described as a set of configuration files in MAGALI a bottleneck since the tracking of dependencies between parameters in multiple files is hard and takes time. In addition, adding a new IP to the platform requires the development of new configuration files and modifying the others. This highlights the interest of developing a method and tools to automatically generate HW/SW interfaces for this kind of platform.
4. HW/SW interface generation flow overview
The main objective of this work is to define a generation flow for HW/SW interfaces targeting different kind of platforms. We would like to describe the mapping to these multiple platforms in a flexibile way and to develop generators for different type of HW/SW interfaces.
In classical Y methodologies in SoC design, the mapping description languages are usually specific to a type of architecture (Multiprocessor, NoC-based, based on hardware IP, etc). The mapping language is always provided together with the architecture modeling language as a way to explore the architecture. The proposed flow is flexible enough to support different models of architectures and to define the corresponding mapping rules. It is defined, as in a compilation chain, in two parts: front-end and back-end. The compilation-like approach promotes the construction of flexible generation tools which are easy to maintain.
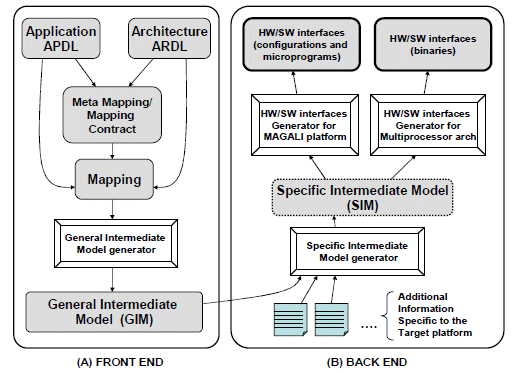
Figure 5. Hardware/Software interface generation flow
In the front end phase (Fig. 5.A), the application description language, called APDL (APplication Description Language), provides the possibility to model complex data flow with arbitration possibilities. The architecture description language, called ARDL (ARchitecture Description Language), brings two main novelties. The first one concerns the description of the physical communications paths to explore the architecture. The second one is the description of the low level software layer provided by the architecture. These two models can be written separately by two different persons (application designer and architecture designer). The mapping solution we present in our flow consists of two steps in order to support the mapping for these different architectures. The mapping constraints are defined in a previous step called meta-mapping. It defines the constraints on APDL and ARDL component mapping. It is a specialization of the classical mapping to a given architecture. The mapping itself complies with the constraints and rules presented in the meta-mapping phase. The General Intermediate Model (GIM) is then generated and describes the application deployed over the architecture resources. It supports the representation of HW, SW and hybrid components. Hybrid components are components which associate the APDL components to ARDL resources as defined in the mapping. At this level, no information about the interface we would like to generate is available.
In the Back-End part (Fig. 5.B), the Specific Intermediate Model (SIM) contains platform-specific information. It is deducted from the GIM of the Front-End part with additional details about the target platform. For example, we can specify information about the address spaces, or interruptions (type, address of the interrupt vector), which depend mainly on the platform. The SIM provides a description of the elements to be generated which constitute the HW/SW interface. It contains all the relevant information for the generation of configuration or binary code for simulation or prototyping.
In this model, the hybrid components described in the GIM are extended with details showing how the correspondence between the APDL part and the ARDL part could be expressed concretely in the target platform. In fact, we describe how to program the target platform (The structure of configurations, the way to describe memory sections in case of multiprocessor architectures, interruption addresses for devices, etc). Using such a model can ease the code generation which is difficult to realize from the GIM that does not include information about the target platform.
5. Front End: High level models for code generation
5.1 ARDL: ARchitecture Description Level
As input of our design flow, we need an abstract model of the platform. One way to express a model of a platform is to use IP-XACT. The IP-XACT standard is a XML-based language for hardware description for IP integration purpose. It has been developed mainly for RTL level (description of wire ports) and does not fit our requirements. So we have defined a new hardware description language, able to represent different kind of platforms at high abstraction level. This new language is an extension of the IP-XACT standard. We will use this format to exploit the TGI API provided by the standard to extract the design data and to use developed tools operating around the standard. ARDL is the proposed language to describe abstract architecture models (Fig. 6).
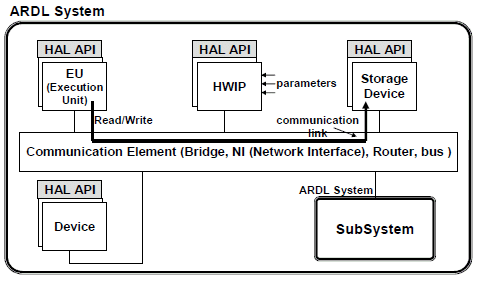
Figure 6. ARDL basic components
The architecture is modeled as a set of hierarchical systems. A system in ARDL is a set of computational components, communication components, storage components and devices. Computational elements are processing units which are an abstraction of CPUs or DSPs or configurable hardware IPs. ARDL is able to model communication components in a NoC-based design or in a bus-based design. If the communication is done with a NoC, we can specify in ARDL additional information concerning the NoC topology, size and routing algorithm. Two main novelties are presented in ARDL by comparaison to languages like [19] [10] in order to enhance application deployment automation:
(1) Modeling the HAL (Hardware Abstraction Layer) API which is a software layer composed of a set of primitives to handle hardware components. This information could be used for example to parameterize drivers in an operating system or to parameterize the communication support.
(2) Modeling the architecture physical communication links. We want to describe at a high level, information that could be useful for example for memory allocation or for implementing communication primitives (read, write) in case of an application running on a CPU-based architecture. In some hardware architectures, the number of communication links is large enough to make the architecture designer work difficult. A communication link between a source and a destination resource is described as the set of resources involved to realize it, as well as some other required information (access mode:read/ write, protocol, etc).
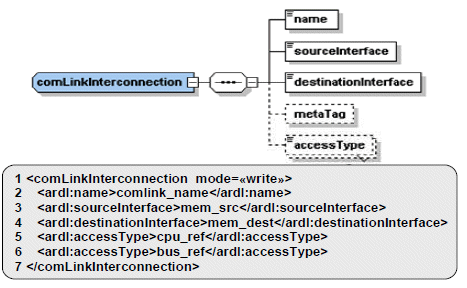
Figure 7. ARDL “comLinkInterconnection”
An example of a “communication link” is presented in Fig. 7 and details data writes (line1) from “mem_src” (line3) to “mem_dest” (line4) through the CPU “cpu_ref” (line5) and the bus “bus_ref” (line6). In case of IP-based architecture, this information will be used to configure the IPs.
5.2 APDL: APplication Description Level
We are facing specific requirements in telecommunication application modeling that can not be done with classical application model such as KPN (description of complex data flows with arbitration possibilities for example). Moreover, we need to describe other meta data like the amount of data exchanged between tasks, tasks complexities, etc. For these reasons, we have developed a new application description language based on the XML notation.
Describing an application with XML notation allows the description of the application metadata. These information are difficult to extract from a C or SystemC implementation. Many system level languages have been proposed in the past to support application description with XML notation [3] [2] [10] but only for KPN or SDF representation. The novelty in our proposal, called APDL, is the possibility to model complex data transfers between tasks (Fig. 8), so that the application description is not limited to KPN or SDF models. This language describes a set of tasks that run in parallel as well as the channels which ensure the transfer of data between tasks. An application described with APDL is composed of two different components: tasks and channels.
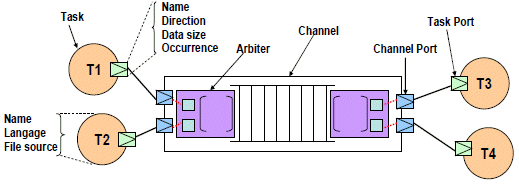
Figure 8. APDL basic components
APDL task is defined with a name, a link to the source file as well as information about the programming language. It accesses to channels via task ports. A task port is defined with a name, a direction, the size of data transferred through the port and the number of the sending and receiving data process done from the port. A task port models a call to a communication primitive (read or write) in the task implementation. The channels represent the communication medium between tasks. An APDL channel is a multi-input multi-output channel. It may model FIFO channels or channels based on shared memory.
An APDL channel can schedule accesses to inputs (resp. outputs) thanks to an input (resp. output) arbiter. A channel arbiter may be an input or output arbiter. It allows the scheduling of accesses to the channel by setting an access order for channel ports. The access order is defined with an input or output matrix. The use of arbiters in channel description is optional. This language supports modeling the well-known families of dataflow applications such as KPN and SDF. It is defined by two XML schemas: “apdl_library.xsd” which defines the syntax of the basic concepts in APDL such as Task, Channel, Arbiter and Port. The file “apdl.xsd” includes this library and defines the language syntax.
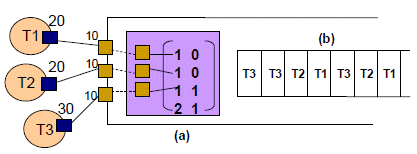
Figure 9. APDL channel with an input arbiter
Fig. 9 shows an example of an input matrix of an APDL channel. In this example, 3 tasks send data to a multi-input channel. We must describe, thanks to the input matrix, the order of data writes from the tasks to the channel. The matrix (Fig. 9.a) is composed of two columns. Each column is a scenario of data writes from tasks to the channel. The last element of each column, i.e. the last row of the matrix, details the number of times the scenario will be executed. In the given example, the first column indicates that task T1 will write 10 data followed by 10 data from T2 and T3. This scenario is repeated twice. Then, the second column of the input matrix starts when the scenario of the first column ends. It indicates that the task T3 will write 10 data in the channel. Therefore, the data are ordered in the FIFO of the channel like in Fig. 9.b. In this example, APDL assumes that the amount of data transferred between the tasks is known in advance.
5.3 Meta-Mapping and Mapping
In most of existing design flows, the mapping language is dependent on the type of application and architecture as it will associate application component to architecture resources. The mapping is done especially for KPN or SDF application over multiprocessor architecture [2] [10]. The mapping rules to be applied may differ from one type of architecture to another. To support several types of architectures in our generation flow, we introduced the mapping in two steps: The first step serves to adjust the mapping to the type of architecture and application by defining mapping rules (meta-mapping step). The second step is to apply these rules in the mapping of the application component over the architecture resources.
The meta-mapping model in our flow defines which type of APDL component might be mapped onto which type of ARDL component. This can be different from one ARDL architecture to another. We also call the meta-mapping model the “mapping contract”. The meta-mapping defines a set of constraints. We find two types of constraints: (1) general constraints concerning the general rules of mapping. For example, a general constraint could allow the mapping of an APDL channel over a configurable IP or forbid the mapping of a task over the CPU if it is reserved to resources configuration. Tasks in this case will be mapped over hardware IPs. (2) Specific constraints concern some architecture components. For example, if we have two processors A and B in our architecture, we may want that processor A executes only one task and processor B executes the rest of the application. This can be expressed in the meta-mapping step and taken into consideration during the mapping. The meta-mapping is done manually and represents a first step in the exploration process.
In [20], the authors distinguished three design scenarios according to the degree of dependencies between the mapping in one side and the architecture and application models in the other side. Our meta-mapping proposition supports those scenarios by offering a flexible way to describe different mapping rules. The meta-mapping language is defined also as a XML Schema.
Once the meta-mapping is achieved, the deployment of APDL application components over the ARDL components of the architecture could be described while respecting the constraints defined in the meta-mapping step. The mapping is defined by “Task Binding” and “Channel Binding”. The task binding allows mapping of APDL application tasks over ARDL processing units. Channel binding allows the mapping of APDL channels over ARDL communication links. This mapping is detailed by defining the correspondence between APDL channel subcomponents (arbiter, FIFO) and ARDL resources referenced as “AccessType” in the communication link definitions. The mapping language is also defined as an XML Schema.
The General Intermediate Model (GIM) is generated when executing the mapping file. It is an XML file describing the architecture resources (ARDL resources) onto which the application (APDL components) is deployed according to the constraints of meta-mapping and the mapping definition.
5.4 Overview of a Front End design environment
The front-end part of the design flow is developed as an extension of an existent industrial design tool called Magillem [18].
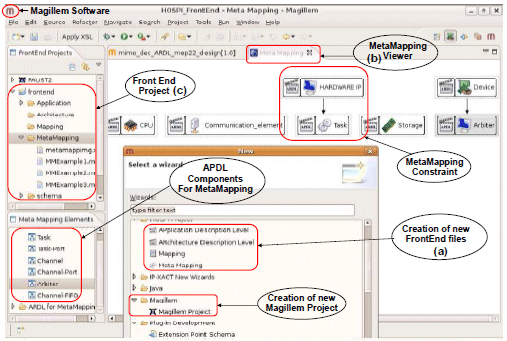
Figure 10. Front end execution environment
Magillem tool suite is an IP-XACT complete design environment including debugging functions and has the ability to run generators. The front-end part of the flow is developed as an Eclipse plugin (Fig. 10). The main functionalities of this plugin are the possibility to create a new application, architecture, meta-mapping and mapping models with the appropriate wizards (Fig. 10.a). A metamapping viewer (Fig. 10.b) and a Front-End project explorer (Fig. 10.c) are proposed. The transformation to generate the GIM is done by an “IP-XACT generator” component executed over an ARDL design and having as parameter the application file, the meta-mapping file and the mapping definition. This generator is implemented in the Magillem environment as ARDL is implemented as an extension to the IP-XACT standard.
6. Back End: The Specific Intermediate Model and HW/SW interface generation tools
6.1 The Specific Intermediate Model (SIM)
The Specific Intermediate Model (SIM) is a specialisation of the GIM for the specific target platform. It models all the necessary components to be implemented in the HW/SW interface to allow the deployment of the application over the target platform.
Fig. 11.c shows the elements of the SIM corresponding to the MAGALI platform. The IPScenario is the principal component which calls configurations and contexts elements from the communication and the HAL layer. The communication layer contains configuration components to allow the description of the data transfer from/to the IP (ICCConfig/OCCConfig).
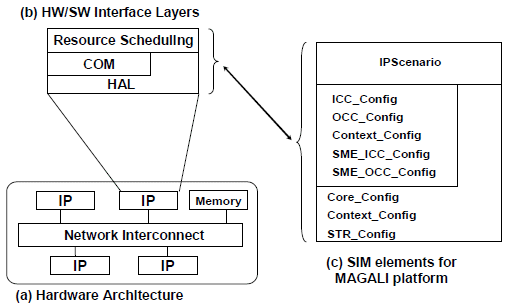
Figure 11. SIM definition for IP-based architecture
The HAL layer contains configurations to define the functions that will be given by the IP. More details about the configurations we be given in the experiment section.
6.2 HW/SW interface generation tools
The tools for generating the final code of the HW/SW interface extract information from the SIM. At this level in the flow, the tools have the information about the grammar of the code to generate (Makefile, configuration file grammar, SystemC templates, etc). These tools are not yet integrated to an industrial design tool and are specific to the target platform or to a type of platform. The use of such models facilitates the development of generators, improves productivity and promotes the development and the maintenance of tools.
7. Experiments
7.1 Description of the architecture
In this experiment, we consider the MAGALI platform which has been developed for telecommunication applications with complex data flow. The “top_magali” (Fig. 12.b) is a subsystem which contains a subset of MAGALI’s Hardware IPs. It includes IPs for specific functions (mep, asip, rx_bit) and IPs which model programmable storage devices (SME for Smart Memory Engine). “top_3gpp” (Fig. 12.a) is the main design used to test the “top_magali” sub system. It contains the processor for the orchestration of the configurations and two components for data generation and recording (recgen_00w, recgen_00s).
The Fig. 12.c is a graphical ARDL view of a MAGALI node (mep_10) designed in the Magillem environment. The router is connected to the network interface, and the network interface to the set of core controllers. To execute applications over MAGALI, a HW/SW interface composed of configuration files (as seen in 3.3) has to be developed.
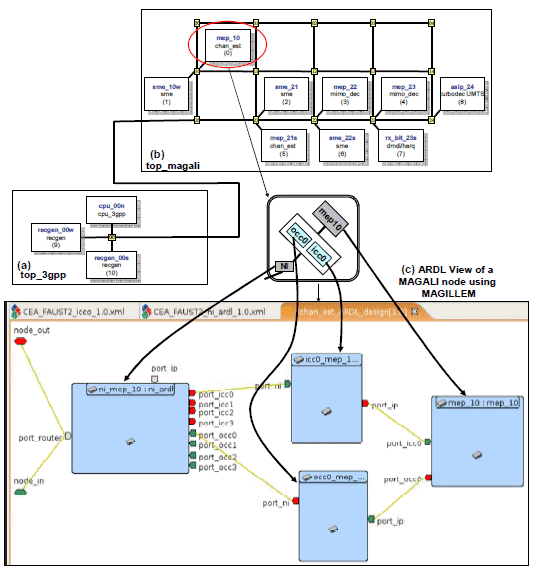
Figure 12. MAGALI architecture modeled with ARDL
7.1.1 Physical communication links in MAGALI
In MAGALI, all the available physical communication links through the NoC and between resources are allowed. They are listed in a generated file called “comlink.cl” during ARDL model loading. “comlink.cl” contains about 400 exploitable communication links for the architecture described in Fig. 12. A communication link in MAGALI is described as a couple made of one OCC corresponding to the sender resource, and one ICC corresponding to the receiver resource: IP_sender 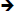 OCC ICC IP_receiver.
OCC ICC IP_receiver.
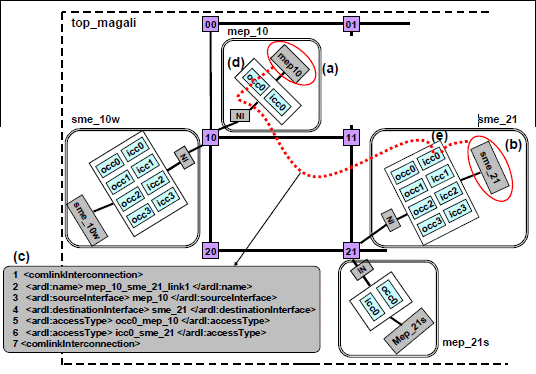
Figure 13. Physical communication links in the MAGALI platform
Fig. 13 shows an example of describing a communication link between the resource “mep10” (Fig. 13.a) and the resource “sme_21” (Fig. 13.b). “mep_10” is declared as the source component in the link (sourceInterface tag Fig. 13.c line3) and “sme_21” as the destination component (destinationInterface tag Fig. 13.c line4). This physical communication link is done via the OCC component “occ0” (Fig. 13.d) of the “mep10” resource and the ICC component “icc0” (Fig. 13.e) of the “sme_21” resource (AccessType tag Fig. 13.c line 5,6).
The generated file “comlink.cl” also contains other communication links between “mep_10” and “sme_21” where others ICC/OCC are used as “AccessType” elements. There are four generated communication links between “mep_10” and “mep_21”: mep_10 occ0 icc0/icc1 /icc2/icc3 sme_21. The description of these links in the architectural model helps in generating and initializing some communication configurations (icc.cfg, occ.cfg, ctx.cfg) to program and run the application over the NoC.
7.1.2 HAL API description in MAGALI
The HAL API is a set of primitives used to handle hardware components. Those primitives are described as software services for components like DMA (dma_start, etc), CPU (load_context, switch_context, etc), etc. For hardware IP, a HAL primitive is described as a set of parameters initialized to run a specific function on the IP.
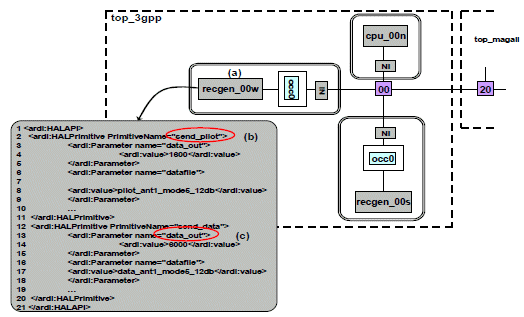
Figure 14. HAL (Hardware Abstraction Layer) description in MAGALI
The “recgen_00w” IP (Fig. 14.a) is an IP used to extend the “top_magali” design in order to simulate data inputs (samples of the Radio/Frequency output channel) which will be used in the considered 3GPP-LTE application. This IP offers two primitives called “send_pilot” (Fig. 14.b) and “send_data”. The “send_pilot” allows the sending of the OFDM pilot symbols in order to estimate the transmission channel.
The “send_data” (Fig. 14.c) primitive allows the sending of the OFDM data symbols which contains the payload data to be transferred over the NoC. The description of these primitives in the architecture model are useful when generating configuration files (core.cfg, ctx.cfg).
7.2 Description of the application: 3GPP-LTE application
The application we want to map over the architecture is a digital base band demodulation chain for wireless communication supporting multi-antenna (MIMO) and OFDMA techniques. Frame structures and system parameters are based on the OPUS [23] project implementation of the Long Terme Evolution (LTE) of the Third Generation (3G) cellular system currently normalized by the 3GPP (3G Partnership Project) (Fig.15).
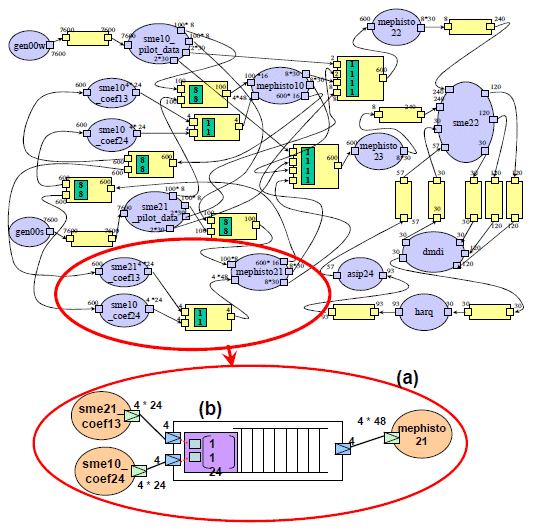
Figure 15. 3GPP-LTE application modeled with APDL
Fig. 15.a shows an example of the use of an APDL channel in the description of this complex dataflow application. The channel includes an input arbiter (Fig. 15.b). The input matrix defines a single data input scenario (number of column of the matrix) which is repeated 24 times.
The conduct of the scenario is defined by writing 4 data into the FIFO of the channel from the first port of the channel coming from “sme_21_coef13” task, then 4 data are written into the FIFO via the second port coming from “sme10_coef24” task. We described the application with 16 APDL tasks and 19 APDL channels including 11 single-input single-output channels, 2 single-input multiple-output channels and 6 multiple-input single-output channels.
7.3 Description of meta-mapping and mapping
The meta-mapping for MAGALI corresponds to defining over which element of MAGALI each element of the application model could be mapped. Fig. 16 shows two mapping constraints. The first one concerns the possibility of mapping an APDL task over an ARDL HWIP (Hardware IP) (Fig. 16.a, line3..6). The second constraint is about the mapping over the CC element, which is defined as an ARDL Device. The meta-mapping allows the mapping of the APDL channel arbiter or the APDL task port over the CC device (Fig. 16.c 16.b line7..11).
An example of the mapping file of the 3GPP-LTE application over MAGALI is shown in Fig. 17. This mapping is in conformance with the constraints defined in the meta-mapping. We can see that the task “sme10_coef24” (line 1) is mapped over an HWIP called “sme_10w” (line 3) (constraint 1). The task ports of the same task are respectively mapped over the ARDL devices “icc3_sme_10w” (line 6) and “occ3_sme_10w” (line 9).
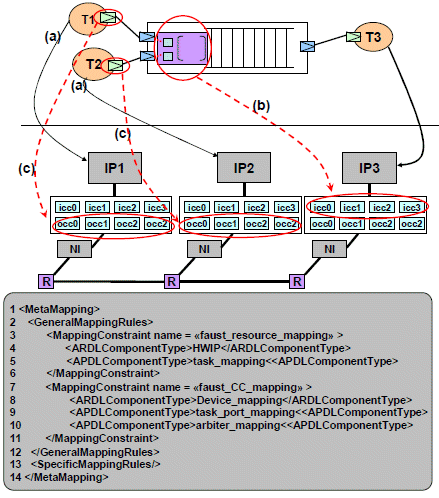
Figure 16. Meta-mapping for the MAGALI platform
The metadata concerning the trafic of data defined in tasks ports and in arbiters is used to generate communication configuration (icc.cfg , occ.cfg).

Figure 17. Example of Mapping for the MAGALI platform
7.4 Configuration files generation
The configuration files generated for MAGALI using our proposed generation flow are computation and communication configurations detailed in 3.3. In Fig. 18 we display the generated configuration files for the “recgen_00s” resource. The “occ.cfg” file (Fig. 18.a) details a data transfer by defining the path to take through the NoC (EAST EAST RES: sme_21), the amount of data to transmit (7600), the size of each packet (8) and the identifier of the ICC which is going to receive those data (num_icc 0). This configuration is called by a micro program defined in “ctx.cfg” file (Fig. 18.b).
The RC (Request Configuration) primitive is called to execute the referenced configuration detailed in “occ.cfg”. There is no “icc.cfg” generated file for this resource because the “recgen_00s” IP only sends data without receiving ones. The file “recgen_00s.load” (Fig. 18.c) details the path taken by the processor to communicate with the resource (SOUTH). The functions executed by the “recgen_00s” are defined as a set of initialized parameters. We illustrate the configurations of the functions “send pilots” and “send data” which are defined in the “core.cfg” file (Fig. 18.d). Those configurations are called by a micro program defined in the file “ctx.cfg” through the RC primitive. The micro-program calls “send pilots” once, then it calls the “send data” function also once.
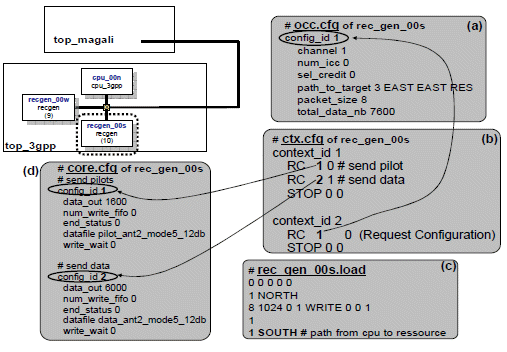
Figure 18. Communication and computation configurations in MAGALI
Configuration files are generated for all the IPs of the MAGALI platform and executed and validated over a SystemC/TLM simulation model of the platform. The number of configuration files to be generated to run the 3GPP-LTE application over MAGALI is about 80 configurations files. This experiment has been used to validate the methodology, the proposed languages (APDL, ARDL, meta-mapping and mapping) and the tools.
8. Conclusion
In this paper, we present a general flow for HW/SW interface code generation based on abstract description of application, architecture and partitioning. We introduce APDL and ARDL as the languages to describe abstract models of applications and architectures. We propose a novel way to define mapping rules and how to deploy an application over the architecture. We show in a case study how to model a complex application called 3GPP-LTE with APDL and a complex architecture called MAGALI with ARDL. We show the benefit of our meta-mapping step to support the mapping of such a complex application over the MAGALI platform. To prove the relevance of our solution, we present a part of the final generated configuration files to run the 3GPP-LTE application over MAGALI. Our future works will focus on generating the HW/SW interfaces with a multi level approach so that we can debug and validate the generated code at each level of abstraction. We will try to validate our proposed flow for other CPU-based platforms.
9. References
[1] K. Keutzer, S. Malik, R. Newton, J. Rabaey, and A. Sangiovanni- Vincentelli, “System-Level Design: Orthogonalization of Concerns and Platform-Based Design”, IEEE Transactions on CAD of circuits and Systems, vol. 19 no. 12, Dec. 2000
[2] L. Thiele, I. Bacivarov, W. Haid, K. Huang, “Mapping Applications to Tiled Multiprocessor Embedded Systems”, Application of Concurrency to System Design, ACSD 2007, pp. 29-40.
[3] N. Pouillon, A. Greiner. DSX. URL = https://www.asim.lip6.fr /trac/dsx/ , 2006-2008.
[4] H. Nikolov, T. Stefanov, E. Deprettere, “Multi-processor system design with ESPAM”, CODES 2006, pp. 211-216
[5] M. Thompson, H. Nikolov, T. Stefanov, A.D. Pimentel, C. Erbas, S. Polstra, E.F. Deprettere, “A framework for rapid system-level exploration, synthesis, and programming of multimedia MP-SoCs”, CODES 2007, pp. 9-14
[6] SoCLib Consortium. Projet SoCLib : Plate-forme de modélisation et de simulation de systèmes integrés sur puce. https://www.soclib.fr/
[7] K. Popovici, X. Guerin, F. Rousseau, P.S. Paolucci, A.A. Jerraya, “Platform-based software design flow for heterogeneous MPSoC“, ACM TECS. Volume 7 Issue 4 - Article No. 39 – 2008
[8] K. Huang, S.I Han, K. Popovici, L. Brisolara, X. Guerin, L. Li, X. Yan, S. Chae, L. Carro, A.A. Jerraya, “Simulink-based MPSoC design flow: case study of Motion-JPEG and H.264”, DAC 2007, pp. 39 – 42
[9] P. Boulet, J.L. Dekeyser, C. Dumoulin, P. Marquet, "MDA for SoC Design, Intensive Signal Processing Experiment", FDL 2003,
[10] S. Stuijk, M.C.W. Geilen, T. Basten, “SDF3: SDF For Free “ACSD 2006, pp. 276-278, Turku, Finland, June 2006
[11] S. Stuijk, T. Basten, M.C. W.Geilen, H. Corporaal. “Multiprocessor Resource Allocation for Throughput-Constrained Synchronous Dataflow Graphs”, DAC 2007, pp. 777-782
[12] M. Raulet, F. Urban, J.F. Nezan, C. Moy, O. Deforges, Y. Sorel, “Rapid Prototyping for Heterogeneous Multicomponent Systems: An MPEG-4 Stream over a UMTS Communication Link”, EURASIP journal on applied signal processing, 2006 , no 14
[13] GNU M4 project : http://www.gnu.org/software/m4/
[14] S. Ha, C. Lee, Y. Yi, S. Kwon, Y. Joo, “Hardware-Software Codesign of Multimedia Embedded Systems: the PeaCE”, RTCSA 2006, pp. 207–214
[15] A. Davare, D. Densmore, T. Meyerowitz, A. Pinto, A. Sangiovanni- Vincentelli, G. Yang, H. Zeng, Q. Zhu, “A Next-Generation Design Framework for Platform-Based Design“, Conference on Using Hardware Design and Verification Languages” (DVCon), 2007
[16] SPIRIT consortium web site: http://www.spiritconsortium.org [17] G. Martin, “Overview of the MPSoC design challenge”, DAC 2006, pp. 274-279
[18] Magillem Design Service, web site: www.magillem.com
[19] R. Marculescu, J. Hu, U.Y. Ogras, “Key research problems in NoC design : a holistic perspective” CODES+ISSS, Sept. 2005, pp. 69-74
[20] D. Densmore, R. Passerone, A. Sangiovanni-Vincentelli, "A Platform- Based Taxonomy for ESL Design", IEEE Design and Test of Computers, vol. 23, no. 5, pp. 359-374, 2006
[21] E. Vaumorin, M. Palus, F. Clermidy, J. Martin: “SPIRIT IP-XACT Controlled ESL Design Tool Applied to a Network-on-Chip Platform”, Design and Reuse Industry Articles, http://www.design-reuse.com/articles/18613/ip-xact-esl-noc.html
[22] D. Lattard, E. Beigne, F. Clermidy, Y. Durand, R. Lemaire, P. Vivet, F. Berens, “A Reconfigurable Baseband Platform Based on an Asynchornous Network-on-Chip”, IEEE Journal of Solid-State Circuits, Vol 43, Issue 1, Jan. 2008, pp. 223-235
[23] D.T. Phan Huy, R. Legouable, D. Kténas, L. Brunel, M. Assaad, "Downlink B3G MIMO OFDMA Link and System Level Performance", VTC Spring 2008. IEEE, pp. 1975-1979
[24] F. Clermidy, R. Lemaire, Y. Thonnart, X. Popon, D. Knetas, “An open and reconfigurable platform for 4G Telecommunication: concepts and application,” 12th Euromicro Conference on Digital System Design (DSD’2009), 27-29 août 2009, Patras, to be published.
[25] X. Guerin, K. Popovici, W. Youssef, F. Rousseau, A.A. Jerraya, “Flexible Application Software Generation for Heterogeneous Multi- Processor System-on-Chip”, COMPSAC (1) 2007, pp. 279-286
[26] G. Schirner, R. Dömer, A. Gerstlauer, “High level development, modeling and automatic generation of hardware-dependent software“, Hardware-dependent Software Principles and Practice, Springer 2009, Chapter 8, pp. 203-231
Related Semiconductor IP
- NPU IP Core for Mobile
- NPU IP Core for Edge
- Specialized Video Processing NPU IP
- HYPERBUS™ Memory Controller
- AV1 Video Encoder IP
Related White Papers
- Abstract C models speed system verification
- Gbit interface forces analog IP into digital flow
- An UML-driven Interface Generation Approach for SoC Design
- SoC RTL Signoff: Divide & Conquer with Abstract Models
Latest White Papers
- Ramping Up Open-Source RISC-V Cores: Assessing the Energy Efficiency of Superscalar, Out-of-Order Execution
- Transition Fixes in 3nm Multi-Voltage SoC Design
- CXL Topology-Aware and Expander-Driven Prefetching: Unlocking SSD Performance
- Breaking the Memory Bandwidth Boundary. GDDR7 IP Design Challenges & Solutions
- Automating NoC Design to Tackle Rising SoC Complexity