Do SoC Architects Have to Get Physical?
by Charlie Janac, President and CEO of Arteris
With the rapid adoption of the 16/14nm FinFET semiconductor manufacturing processes, the SoC architect’s job is becoming more difficult. Traditionally, architects were responsible for key decisions underlying the data flow and systemic functionality of a design but typically ignored the physical placement ramifications of their decisions, letting back-end synthesis place and route (SP&R) teams deal with the details. With the use of faster and smaller process dimensions, early front-end decisions are starting to cause problems with back-end timing closure at a later design phase. Architects now have to take more ownership of their designs’ ability to close timing.

Figure 1. SoC Architects must consider the ramifications of their design decisions before the project advances to the physical design phase where timing closure problem cause lengthy schedule slips.
The FinFET-type processes present timing closure challenges because signals travel greater distances because densities are greater, voltage thresholds are lower, and operating frequencies are typically higher. This impacts SoC architects who are typically focused on designing their chips from the logical and data flow perspectives. They usually draw an SoC floor plan on a piece of paper in the early design stages and then leave the physical constraints to the layout group on the back end of the process. Historically, this worked well enough, but at the 40nm SoC generation, life got harder due to timing closure issues. This issue became even more difficult at 28nm and even more so with 16/14nm FinFET designs.
The most important part of the SoC affecting timing closure is the interconnect because it contains the majority of the SoC wires which connect to all major parts of the chip, and because it spans across the entire chip. One of the important innovations in SoC design is the rapid deployment of network-on-chip (NoC) interconnect technology which introduces packetized transport communications inside the chip. NoC-type interconnect IP technology enables the interconnect to be isolated from other IP blocks in the chip by Network Interface Units (NIU) at the edge of the interconnect, which are abutted to their respective IP blocks with which they interface. This capability provides automated interconnect timing closure by closing timing separately in the interconnect before before the entire SoC.
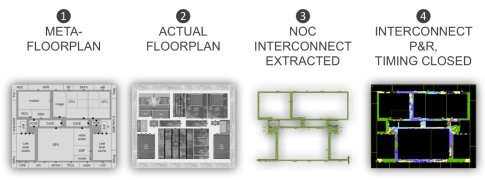
Figure 2. Technology exists today to optimize the timing of on-chip interconnects prior to executing full P&R iterations.
If it takes a signal more than one clock cycle to move across a physical connection from its initiator IP to its target IP, pipelines or repeaters need to be inserted in order to maintain target frequency. By inserting the correct pipelines in the right places, we manage to close timing.
In a FinFET SoC there are three choices for timing closure:
- Architects can ignore it until the physical layout phase of the project and have the place and route team deal with it. The problem with this approach is that the layout team has to deal with unverified RTL from a timing closure perspective which can lead to schedule slips and possible architecture rework. In FinFET SoC designs, it is very important not to leave the timing closure tasks until the tail end of the project. Project teams that choose this approach may face significant project schedule slips;
- When pipelines are added manually by the interconnect RTL team, it becomes a time-consuming process that is prone to errors. Furthermore, the interconnect IP changes faster than the timing can be closed due to engineering and marketing ECOs so the manual timing closure scheme has to be over engineered to anticipate the evolution of the SoC. This can cost area, power and performance as well as impact latency. Such a result can raise the cost of an SoC and reduce the financial return of the project. A large SoC can have over 6,000 pipeline choices which results in 6,000 factorial combinations which is a level of complexity that is difficult to handle with manual methods. This can also result in schedule slips;
- Timing closure can be automated using NoC interconnect RTL and physical awareness tools. Such tools can estimate frequency of timing closure at the architectural level, RTL level and can help set up timing closure at the place and route level. Using these tools can improve SoC schedule predictability and optimize interconnect area, power and latency.
It is a general rule that in a complex, sequential process such as SoC design, problems that are addressed early are less costly to deal with than problems addressed late. Therefore, it is best to fix potential timing closure problems during the earlier SoC architecture phase rather than during later RTL development or place-and-route phases. Design teams that leave the timing closure task until the place and route (P&R) phase of a complex SoC are exposing their project to the risk of having to perform several days- or weeks-long P&R iterations. This also opens up the possibility for RTL-level and architecture level engineering change orders (ECOs). These steps add costs and schedules slips and can cause the project to miss a critical market window, which negates any early market profits and market share momentum.
To close timing during the architecture phase three capabilities are needed:
- Ability to automatically generate a meta floorplan based on list of IPs and the parameters of their IP connectors. This provides the knowledge of interconnect distance;
- Ability to automatically place the interconnect IP RTL based upon IP block socket locations from the meta floorplan;
- Ability to automatically turn pipelines on to achieve timing closure.
At the architectural level, the timing closure process has limited accuracy due to preliminary interconnect RTL and floor plans. However, if a designer cannot close timing based on the architecture at this stage, it is unlikely that timing closure can be achieved later on in the SoC process. Therefore, architects can use automated timing closure feedback to avoid timing closure issues at the RTL and place-and-route stages of their design. Providing a timing closure verified architecture to the RTL team would then save time at the RTL stage and in turn save valuable SoC design cycle time and resources.
The timing closure problem will get even worse at 10nm generation of SoC and worse still at 7nm generation. Architects need to consider physical constraints at the architectural stage of an SoC design in order to ease the burden on the downstream RTL team and the layout teams. Network-on-chip interconnect IP with additional timing closure capabilities facilitates architectural level timing closure without excessive impact on the development of SoC architectures.
About the Author:
 K. Charles Janac is chairman, president and chief executive officer of Arteris. Over 20 years of his career, he has worked in multiple industries including electronic design automation, semiconductor capital equipment, nano-technology, industrial polymers and venture capital.
K. Charles Janac is chairman, president and chief executive officer of Arteris. Over 20 years of his career, he has worked in multiple industries including electronic design automation, semiconductor capital equipment, nano-technology, industrial polymers and venture capital.
Related Semiconductor IP
- FlexNoC 5 Interconnect IP
- High speed NoC (Network On-Chip) Interconnect IP
- Universal Chiplet Interconnect Express(UCIe) VIP
- AXI Interconnect
- AXI Interconnect Fabric
Related White Papers
- Do the Math: Reduce Cost and Get the Right Communications System I/O Connectivity
- Non-Power-of-Two FFT Circuit Designs Do Not Have to be Difficult
- How a voltage glitch attack could cripple your SoC or MCU - and how to securely protect it
- EDA in the Cloud Will be Key to Rapid Innovative SoC Design
Latest White Papers
- Transition Fixes in 3nm Multi-Voltage SoC Design
- CXL Topology-Aware and Expander-Driven Prefetching: Unlocking SSD Performance
- Breaking the Memory Bandwidth Boundary. GDDR7 IP Design Challenges & Solutions
- Automating NoC Design to Tackle Rising SoC Complexity
- Memory Prefetching Evaluation of Scientific Applications on a Modern HPC Arm-Based Processor