An IP core based approach to the on-chip management of heterogeneous SoCs
Oxford, UK
Abstract
This paper describes a new approach to solving the performance, scalability and leveragability challenges associated with the software programming model of multicore chip architectures. The proliferation of multiple cores on a single chip has arisen in response to market demand for more efficient architectures that can deliver optimal price-performance power characteristics for applications. This trend has been enabled from a hardware perspective by the advances in silicon potential offered by Moore's Law and associated EDA and IP-reuse standards.
However, the increase in hardware complexity that is associated with the increased number of cores can often prevent software developers from fully realising the potential of these architectures. The proposed solution utilises a unique combination of on-chip hardware together with a task-based programming model to balance the productivity (time to market) and application efficiency (BoM cost) that can be achieved by application developers targeting complex multicore architectures.
1 Introduction
The amount of functionality (represented by the number of transistors) economically viable on a single chip has risen 300 million-fold since the introduction of the first microprocessor 35 years ago. As Moore’s Law continues to provide opportunities for evergreater levels of system integration on a single chip, the embedded semiconductor sector is constantly challenged to effectively balance performance, power and price (“application-available” MIPs/mm2, MIPs/mW, MIPs/$).
As a rule of thumb, power dissipation in an SoC grows linearly with frequency and quadratically with voltage. Usually, lowering frequency enables the chip to operate at lower voltages - this has a cubic effect on power savings. Even if the achievement of the same level of performance comes at the expense of increased use of silicon area, the overall power savings can be considerable. Consequently, unlike desktop environments, embedded chip architects have typically not scaled the clock frequency in order to meet performance targets but have sought to increase the level of parallel execution at lower frequencies to balance performance and power.
Today, many embedded chip designers are attempting to leverage the increased silicon capacity offered by Moore’s Law to solve these considerable performance challenges by using an approach in which multiple dissimilar processing resources (“cores”) are integrated within a single chip. These heterogeneous “multicore” chips may be branded as ‘SoC’, ‘ASSP’, ‘multicore DSP’, ‘platform FPGA’ etc.
There are numerous hardware design challenges in creating a multicore architecture, requiring the integration of various cores using a standard methodology and interconnect strategy. However, the most significant multicore challenge is faced by the software designers tasked with creating applications on these increasingly complex chips. Software programmers must be able to harness the priceperformance potential of heterogeneous multicore chips to deliver the required application performance for their system.
2 Task Based Programming Models
Although each processor of a heterogeneous multicore architecture may exploit instruction level parallelism (ILP), these machines typically also take advantage of task or task level parallelism (TLP) to realise the potential performance of the underlying hardware. In contrast to ILP, which may be automatically identified at run-time, TLP is defined within application software at design-time.
A task defines an autonomous package of work (of arbitrary complexity) containing an execution state, instruction stream and dataset, which, by definition, may execute concurrently with other tasks. In principle, hardware blocks with clearly defined functionality may also be regarded as processing resources with a reduced instruction set (for example ‘input’ and ‘output’ on an I/O device) capable of executing specific tasks.This perspective provides a common abstraction from which to regard all processing resources, irrespective of complexity and is central to the Ignios vision of manageable multicore architectures. From this abstraction a task is equally descriptive of a complex and flexible software algorithm and a very basic hardware operation. Indeed, the tasking abstraction may be used regardless of the partitioning of the underlying system.
2.1 Leveraging Tasked Programming Techniques to Express Application Level Concurrency
This section suggests an example application, a voice over IP gateway product, and decomposes the functional requirements into the type of tasked abstraction discussed in the previous section. Whilst some business models, methodologies and technologies permit hardware and software flexibility, this example explores the OEM’s challenges of mapping the example application onto a complex ASSP (application specific standard platform) architecture (Figure 2), where the hardware resources have already been fixed by the semiconductor vendor.
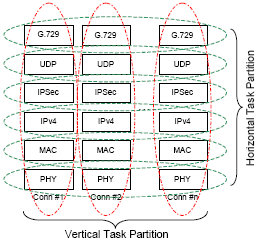
Figure 1: A Fully Partitioned VoIP Protocol Stack
Figure 1 shows a datapath protocol stack for a VoIP gateway. The example system takes multiple streams of PCM data, performs a G.729 encoding, and encapsulates the results using a secure IP datagram. Each protocol executes sequentially within a given connection, consuming data from its higher protocol peer and passing data to its lower protocol peer.
This application could be implemented monolithically. However, scalability across systems of varying performance and compatibility with multiple hardware platforms mandates a flexible, scalable approach. This approach must be capable of exploiting possibly multiple dissimilar hardware accelerators and providing the level of isolation mandated by modern network infrastructure.
In practice some level of processing resource class centric partitioning is inevitable. For example, the physical layer (PHY) and the media access control layer (MAC) would typically be implemented in dedicated blocks with a pipelined interface between them. This resource pair would be shared among the competing connections as a single processing resource. Figure 4 shows a directed graph where the classes of tasks and communication paths are identified. Additionally, this diagram shows an association of tasks with classes of processing resources.
An important distinction is drawn here between a class of processing resource and an instance of that class of processing resource. Since, on a given hardware architecture, multiple instances of a particular processing resource class may be present (for example DSPs in Figure 2.
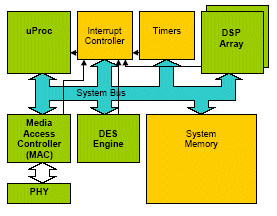
Figure 2: Optimised VoIP Gateway Multicore Architecture
By adopting processing resource class centric horizontal partitioning, where each algorithmic layer represents a possible task delineation point, particular functions, common to all connections, may be abstracted to a dedicated accelerator or heterogeneous processing resource instance. However, a purely horizontal partition lacks an intuitive method of providing per-connection services or policies, and also a method of scaling the solution across multiple homogenous processing resource instances.
By contrast, vertical task delineation enables perconnection isolation and policy enforcement whilst providing an ability to effectively load balance between multiple homogeneous processing resources.
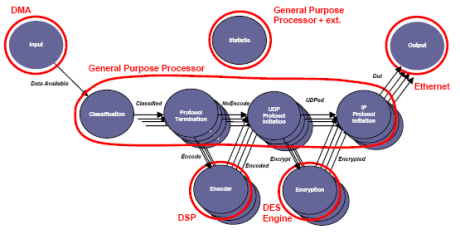
Figure 4: Example application directed graph
The most flexible and scalable solution combines both the horizontal and vertical partition into a twodimensional approach. In the fully partitioned protocol stack, tasks are delineated per protocol layer, per connection. This system is partitioned to leverage both homogeneous (load balancing across multiple identical processors) and heterogeneous (algorithmic accelerators) processing resources whilst enabling sophisticated system-wide quality of service policies. However, whilst this approach offers the most potential, it traditionally does so at the expense of runtime efficiency – an unacceptable compromise in the embedded community.
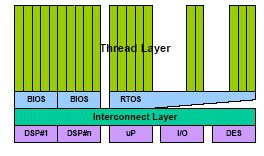
Figure 5: Typical multicore SoC control stack
3 Potential Costs of Tasking
A number of key challenges threaten the viability of optimally mapping tasked (concurrent) applications onto parallel hardware platforms – Performance, Complexity and Debugability. Together, these have become known as the ‘software multicore problem’. Their existence has historically led to the deployment of lower performance and inflexible ad-hoc schemes and their impact scales nonlinearly as more cores are integrated on-chip.
3.1 Performance
The responsibility for task management has historically fallen on an OS running on a generalpurpose processor (GPP).
Figure 5 shows a traditional control plane stack for our example architecture reflecting the tight coupling between the RTOS and the non ISA-based devices (I/O device, hardware accelerators). This proxy management is executed by the processor on behalf of the other processing resources and includes in-band configuration, interrupt servicing and scheduling. At any instant, proxy management requirements are temporally and logically unrelated to the datapath activities of the GPP. Figure 6 shows the impact of an IO event, for example, on the execution of an application task within a GPP.
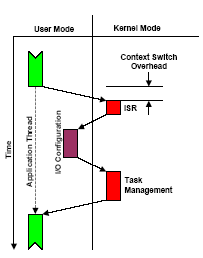
Figure 6: Task management overhead
Control plane tasks are summarised as follows:
- Task state management.
- Task scheduling; both horizontally – between instances of a particular task class competing for a resource - and vertically – between instances of dissimilar task classes competing for the same resource.
- Inter-task communication and synchronisation; both vertically - among peers within a given connection - and horizontally - with management agents.
Frequent and asynchronous control plane activities traditionally cause a significant performance degradation, both in terms of throughput and real-time behaviour, in general purpose processors.
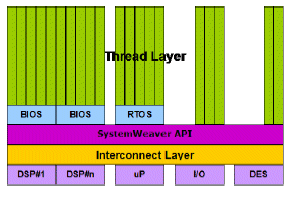
Figure 7: SystemWeaver API
Furthermore, the trend towards increased core frequencies has made the design of the generalpurpose processor increasingly inappropriately geared to task management at both a micro (instruction set, pipeline design) and a macro (caches, register file management) architectural level.
3.2 Complexity Management
Although recent developments at the hardware interconnect layer offer a socket based approach for the physical interoperation of dissimilar processing resources[1], there has historically been no similar unifying capability at the task management and communication layer. In the worst case this may lead to an n2 problem, where the communication and task management problem must be solved - by the application programmer - for each combination of processing resource instances, with its associated scalability challenges.
3.3 Debugability
The distributed nature of computation and control on multicore systems presents significant challenges for debug. Visibility on any SoC is challenging and the problem is compounded by the presence of multiple cores. Furthermore, key temporal relationships between tasks executing in parallel may be lost when debug code is introduced (so called Heisenberg bugs), rendering one of the most popular debug methodologies ineffective.
4 SystemWeaver – Addressing The
Software Multicore Challenges By providing a common task management and communication abstraction (the SystemWeaver API), which is efficiently implemented on-chip in an optimised hardware resource (the SystemWeaver Server IP core), with a rich multicore debug capability, Ignios’ SystemWeaver solution enables software designers to develop and validate efficient code on complex hardware, overcoming the key software multicore problems.
Figure 7 shows the deployment of the SystemWeaver API. This API layer provides the following services to complex multicore designs in a consistent and unified manner:
- Programming model abstraction.
- Any core to any core task creation/forwarding capabilities. Where ‘core’ is inclusive of both instruction set architecture (ISA) based cores and fixed function hardware accelerators.
- Synchronisation of shared resources (communication).
- Advanced task scheduling.
- Inline device configuration.
- Task based debug abstraction.
4.1 Key Features
4.1.1 Programming model abstraction
The programmer is presented with a consistent and unified view of the multicore device through the SystemWeaver API. Each class of core within the multicore device is accessed using the same methods (“access transparency”). This abstraction facilitates software development, provides an additional abstraction for autonomous subblock level hardware verification and accelerates system-level integration.
4.1.2 Task Creation and Forwarding
As the SystemWeaver task management API is very lightweight in terms of memory footprint and processing requirements, hardware and software processing resources can easily leverage the capabilities of the SystemWeaver Server regardless of their complexity. For example, rather than interrupting a general purpose processor on a perpacket bases, an input device can autonomously create a task and place that task in the work queue, or “ready queue”, for the GPP.
4.1.3 Task Synchronisation (communication)
The SystemWeaver API provides fundamental mechanisms by which tasks may synchronise and exchange information. The SystemWeaver solution supports all popular methodologies (mutexes, semaphores, monitors and message passing) across hybrid bus and memory hierarchies.
4.1.4 Advanced Task Scheduling
The SystemWeaver Server provides complex scheduling capabilities which may be refined throughout the development process of an SoC. In addition to the more common policies (FIFO, round robin, priority), more complex policies may be implemented in arbitrary combinations. These scheduling hierarchies may be deployed to implement any combination of application derived scheduling and/or hardware platform derived scheduling (load balancing, time slicing etc). They determine how a task instance is selected for execution from all the tasks present in the ready queue and how a given instance of a processor is selected from the available resource within a pool.
4.1.5 Inline Device Configuration
The SystemWeaver solution provides the ability to configure devices on a per task basis, obviating the need for proxy configuration leading to the frequent, tightly coupled processor interrupts and service routines observed in Figure 6.
4.1.6 Power Management
With appropriate configuration the SystemWeaver solution may use its task based viewpoint to intelligently schedule tasks to processor pools, enabling processing resource instances to be placed in low power state, closely correlating the presented load and “active” processing resources.
4.1.7 Debug abstraction
The SystemWeaver Server is ideally placed to provide a rich set of real-time debug records and breakpoint capabilities. A purpose built hardware debug module within the SystemWeaver Server provides full event visibility including task state transitions, task dispatch and synchronisation events in real-time without the probe effects traditionally associated with debug software builds.
5 Design and run-time
Although minimally disruptive to existing multicore hardware design practices and software design methodologies, there are some key differences in the way SystemWeaver enabled multicore devices are designed and the manner in which they operate at runtime. There are two types of logical entity within a SystemWeaver solution:
- The SystemWeaver server core, which is embodied in hardware and is attached to the system interconnect(s) and the interrupt structures.
- SystemWeaver clients, which are API agents that can be embodied in either hardware or software according to the capabilities of the processing resource (for Instruction Set Architectures (ISA) the client shim will be implemented in software).
5.1 Hardware Integration
Figure 8 shows the previous complex multicore design example with the hardware components of the SystemWeaver solution added. Several points are worthy of note:
- A SystemWeaver Server core has been added as a slave to the system bus.
- An amount of local memory has been added to the SystemWeaver private memory interface. This memory allows application-specific configurations to be created and loaded during the boot procedure.
- All peripheral interrupts are now routed to the SystemWeaver Server.
- Where processing resources are insufficiently flexible to interface directly with the SystemWeaver Server a SystemWeaver Hardware Client Shim core may be introduced between the interconnect agent and the processing resource.
- For greatest efficiency, processing resources are controlled via interrupts issued from the SystemWeaver Server.
- The interrupt controller and timer functions are a subset of SystemWeaver functionality and have consequently been removed.
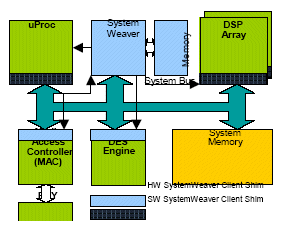
Figure 8: SystemWeaver enabled multicore device
The SystemWeaver hardware client shim has the following capabilities:
- SystemWeaver API compatibility
- Hardware support for synchronisation/communication.
- DMA functionality
- Processing resource configuration capability
Where a hardware client shim is deployed, the processing resource may have a very fixed function. In this case, the shim is responsible for responding to task related interrupts, fetching task data from memory, performing in-line configuration (relieving the system primary processor of proxy configuration responsibilities), stimulating the processing resource, data storage and dynamic task creation (if required).
5.2 A day in the life of a packet
The following section describes the control plain activities associated with a packet routing through our example VOIP protocol stack according to Figure 3.
As a packet arrives at the Ethernet port an interrupt is generated in the usual manner. Rather than interrupting the GPP, the interrupt is issued to SystemWeaver server. A blocked task is liberated into the ready queue structure for the GPP. Within this structure the arrival of a new task initiates a scheduling operation. The interrupt service task is scheduled along with the existing tasks waiting for the GPP, in this case the task is not of higher importance than the existing waiting tasks and therefore it is scheduled according to the configured policies within the ready queue.
When the task reaches the head of the ready queue SystemWeaver indicates that a task is available to the software client shim (SCS) of the GPP. This is normally achieved by an interrupt. The SCS reads the task control block (TCB) from SystemWeaver server and executes the application’s classification operation referenced within it. Upon completion the GPP creates a new task for the protocol termination function and places it into the GPP resource class ready queue within the SystemWeaver server.
When appropriate, the protocol termination stage of packet processing is carried out in a similar manner. During this stage the packet is identified as having very high priority. Therefore, when an encoder task is created for the DSP within the SystemWeaver server, it rapidly propagates to the head of the associated ready queue structure. However, in this case a cooperative scheduling policy has been selected so the SystemWeaver server is not permitted to pre-empt the currently executing task. The packet is encoded when the first of the DSP resources becomes available. Upon completion, the DSP creates a UDP protocol initiation task using the same set of server API calls as the GPP.
In this case, the GPP scheduler is permitted to preempt the currently running task. Consequently an interrupt is generated immediately and the SCS within the GPP ensures that state is stored for the pre-empted task. Processing continues and an encryption task is created. In addition, an IP protocol initialisation task is created and immediately blocked pending a synchronisation primitive from the DES engine hardware client shim (HCS).
Once again the DES engine ready queue is cooperative, as the hardware resource is not capable of context switching. When an interrupt is received for the packet the HCS reads the TCB, fetches the appropriate data and forwards it to the DES engine. Upon completion the HCS places the results back in memory and issues a synchronisation primitive to the waiting task within the SystemWeaver server core. The waiting task is now unblocked and, due to its importance, rapidly propagates to the head of the ready queue for the GPP resource class. Indeed, as pre-emption is enabled, the GPP is immediately interrupted.
Upon completion of the IP protocol initiation a new task is created for the output device. As before, the hardware client shim fetches the TCB and associated data from the SystemWeaver server and memory respectively. In this case the HCS also provides inband configuration to the Ethernet port prior to the data packet itself.
6 Conclusions
Sophisticated multicore designs are being applied to many application areas. These multicore devices raise complexity both at a hardware and, most significantly, at a software level.
A consequence of the highly-parallel, heterogeneous architecture of most multicore devices is that the burden of task management, both within and between processing resources, grows non-linearly, resulting in a “huge overhead of OS scheduling, interrupt processing, user-to-kernel transitions, context switches”[2]. This impacts the ease with which software developers can target multicore hardware – impacting their time to market and, ultimately, the cost efficiency of their end-system.
A task-based programming model enables the expression of an application's inherent concurrency, which can exploit hardware or software implementation parallelism equally. The SystemWeaver solution supports tasked programming techniques to deliver a solution that is tractable, flexible and, due to the unique hardware and software approach, provides this abstraction with no compromises to run-time efficiency.
In addition, the SystemWeaver API permits greater debug coverage, further accelerating the key time to market bottleneck of verification and validation.
7 References
[1] www.ocpip.org
[2] Pat Gelsinger (Chief Technology Officer, Intel), Intel Developer Forum, Spring 2004
Related Semiconductor IP
- DeWarp IP
- 6-bit, 12 GSPS Flash ADC - GlobalFoundries 22nm
- LunaNet AFS LDPC Encoder and Decoder IP Core
- ReRAM NVM in DB HiTek 130nm BCD
- UFS 5.0 Host Controller IP
Related Articles
- Stop-For-Top IP model to replace One-Stop-Shop by 2025... and support the creation of successful Chiplet business
- An Outline of the Semiconductor Chip Design Flow
- Open-Source Design of Heterogeneous SoCs for AI Acceleration: the PULP Platform Experience
- An Open-Source Approach to Developing a RISC-V Chip with XiangShan and Mulan PSL v2
Latest Articles
- Assertain: Automated Security Assertion Generation Using Large Language Models
- VolTune: A Fine-Grained Runtime Voltage Control Architecture for FPGA Systems
- A Lightweight High-Throughput Collective-Capable NoC for Large-Scale ML Accelerators
- Quantifying Uncertainty in FMEDA Safety Metrics: An Error Propagation Approach for Enhanced ASIC Verification
- SoK: From Silicon to Netlist and Beyond Two Decades of Hardware Reverse Engineering Research