Integrating eFPGA for Hybrid Signal Processing Architectures

As system requirements evolve toward multi-standard, reconfigurable platforms, signal processing architectures are under pressure to deliver both ASIC-class performance and software-like flexibility. Semiconductor engineers face a fundamental tradeoff: fixed logic yields, unmatched throughput, and efficiency, but cannot adapt once taped out. Software-programmable solutions offer flexibility but often miss hard real-time performance constraints and can consume more power.
Embedded FPGA (eFPGA) technology offers a practical middle ground — a reconfigurable hardware fabric, just like FPGA chips use, that can be instantiated directly within a SoC or ASIC. When used alongside CPUs, vector processors, DSP cores, and fixed accelerators, eFPGA enables a hybrid signal processing approach that meets performance, power, and adaptability targets simultaneously.
Benefits of a hybrid approach with eFPGA include:
- 10x – 100x acceleration of critical kernels like correlation or matrix multiplication
- Improved power over a vector processor for MAC intensive filters
- Improved power and area efficiency versus a standalone FPGA by eliminating redundant I/O, logic, SerDes, PHY’s, etc.
- Dynamic reconfiguration to switch between multiple signal processing modes on demand to handle multiple protocols, sensor types, or waveform profiles.
High-Throughput DSP Implementation: Vector Processor vs Programmable Logic
Modern signal-processing workloads increasingly push system designers into a regime where throughput and energy efficiency matter more than peak clock frequency. While high-performance vector processors can execute DSP algorithms efficiently, they remain fundamentally sequential machines that reuse arithmetic hardware across operations. In contrast, programmable logic implements the algorithm directly in hardware, allowing operations to occur simultaneously and with deterministic timing. The practical consequence is not simply higher performance, but the ability to sustain high data-rate processing within a constrained power envelope — a key requirement in communications, radar, and edge-AI sensing systems.
The difference becomes clearer when comparing how a high-speed FIR-style DSP workload maps onto a vector CPU versus programmable logic.
| Processing Criteria | Vector CPU (e.g., ARM SVE) |
FPGA (e.g., Xilinx UltraScale+) |
| Processing Style | Sequential vector processing (SIMD) | Spatial parallel processing |
| Parallelism | ~16–32 samples processed per cycle using SIMD | All filter taps operate simultaneously |
| Arithmetic Resources | Limited number of ALUs reused across operations | Dedicated hardware multipliers instantiated per tap (e.g., 64 multipliers) |
| Pipeline Behavior | Multiply-accumulate operations serialized across cycles | Fully pipelined datapath |
| Cycles per Sample | ~4–6 cycles per sample (pipeline + memory fetch latency) | 1 sample per clock cycle |
| Memory Access | Dependent on cache and memory bandwidth | Data streamed directly through logic fabric |
| Determinism | Affected by cache misses and OS scheduling | Fully deterministic timing |
| Clock Frequency | ~2 GHz | ~300 MHz |
| Achievable Sample Rate | ~300–500 MS/s (heavily optimized) |
~300 MS/s sustained throughput |
| Power Consumption | ~10–20 W (high-performance core) | ~3–5 W |
The takeaway is not that processors are unsuitable for DSP, but that once sustained throughput and power efficiency become system-level constraints, spatial computing architectures such as programmable logic become the practical implementation choice.
This is precisely the class of workload where embedded programmable logic becomes useful within an SoC architecture.
A hybrid approach leverages fixed logic for known, stable functions and eFPGA for functions that may need to change for different end use processing requirements or to support new functionality such as new waveform types, filter banks, or adaptive beamforming modes.
A representative SoC-level block diagram might include:
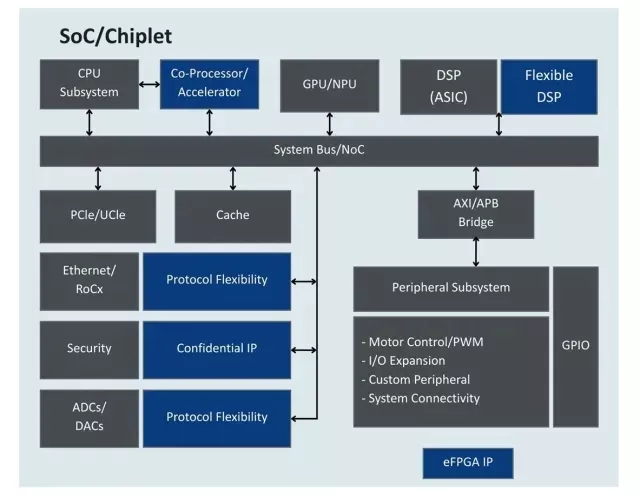
- The software programmable CPU/DSP handles control, adaptation, and lower-rate computations
- Fixed logic (ASIC DSP or hardware accelerators) implements deterministic pipelines such as FFT or channelization that are always required
- eFPGA fabric bridges the gap — implementing reconfigurable kernels or extensions that may change over time
So, how do you decide what to implement in eFPGA versus fixed logic? It depends on the markets, systems, applications, as well as the intended system lifespan of the ASIC. The table below provides general guidelines of which solution would be better.
| Criteria | When to Use Fixed Logic | When to Use eFPGA |
| Algorithm Stability | Will always be used (e.g., FIR filter) | Need to support a variety of future algorithms |
| Latency | Hard real-time (< 100 ns) | Near real-time w/pipelined RTL |
| Power efficiency | Ultra-low power | Very low power with use of eHVT standard cells |
| Bit-width optimization | Fixed, well defined | Support variable precision from various data sources |
| Future hardware updates | None | Anytime during product lifetime |
As an example: In a 5G/6G modem or phased-array radar SoC, FFT and DUC/DDC chains are best left as fixed accelerators since they are base filtering functions that typically will always be required, while adaptive beamforming, pulse compression, or digital filters might need to be updated to address new spectral bands, modify beamforming coefficients or array geometries or changes to modulation or coding schemes.
While eFPGA provides greater flexibility in a hybrid solution, there are some performance and power implications to be aware of.
- While there are no external I/O overhead, an eFPGA still requires I/O around the fabric to connect to on-chip buses, SerDes, and data converters. A high I/O requirement can force a larger fabric than would otherwise be needed to support planned designs.
- Area efficiency is typically 5–10× lower logic density than fixed ASIC gates, but acceptable for the small portion of logic requiring reconfigurability.
- Power is roughly 2–3× higher per operation than fixed logic, but still 10× more efficient than a discrete FPGA or software-based solution.
As a rule of thumb: Use eFPGA for 10–20% of the design’s total DSP workload — the part that benefits most from hardware adaptability.
As an illustration, consider a wideband digital receiver pipeline:
- Front-end ADC interface → hard logic
- Polyphase filter bank → fixed accelerator
- Adaptive equalization / beamforming → implemented in eFPGA for algorithm agility
- Control / mode selection → CPU/DSP
When requirements shift (e.g., new modulation schemes, adaptive spatial filtering), only the eFPGA bitstream needs to be updated—no silicon re-spin is required. Additionally, High-Level Synthesis (HLS) tools from Rise Technology, Siemens or MathWorks’ HDL Coder can help generate new RTL from C/C++ and Simulink models which would then be used by the eFPGA programming tools.
Conclusion
For semiconductor engineers architecting next-generation signal processing SoCs, eFPGA integration provides a strategic flexibility point. It enables:
- Post-silicon algorithm updates
- Rapid adaptation to evolving standards
- Acceleration of select DSP functions without a full hardware redesign
In essence, eFPGAs transform static ASICs into reconfigurable compute platforms—bridging the gap between fixed-function efficiency and programmable adaptability.
As signal processing algorithms continue to evolve faster than hardware lifecycles, eFPGA-based hybrid architectures will become an essential part of high-performance SoC design.
Related Semiconductor IP
- Radiation-Hardened eFPGA
- eFPGA Hard IP Generator
- eFPGA on GlobalFoundries GF12LP
- eFPGA IP — Flexible Reconfigurable Logic Acceleration Core
- Heterogeneous eFPGA architecture with LUTs, DSPs, and BRAMs on GlobalFoundries GF12LP
Related Blogs
- Jeff Bier's Impulse Response - Open Source Digital Signal Processing?
- Digital Signal Processing for Wireless Application: DSP IP core is dominant
- ARM Cortex-M7: Digital Signal Processing Drives Family Evolution
- Silicon Creations Presents Architectures and IP for SoC Clocking
Latest Blogs
- Considerations When Architecting Your Next SoC: NoCs with Arteris
- Implementing Dual-core Lockstep in the CHIPS Alliance VeeR EL2 RISC-V core for safety-critical applications
- Rethinking Display Safety: Why RISC-V-Supervised DisplayPort Subsystems Enable Secure, Isolated Automotive Architectures
- Area, Pipelining, Integration: A Comparison of SHA-2 and SHA-3 for embedded Systems.
- Why Your Next Smartphone Needs Micro-Cooling