Boosting AI Performance with CXL
As AI applications rapidly advance, AI models are being tasked with processing massive amounts of data containing billions – or even trillions – of parameters. Each large workload involves numerous iterations for data comparison, predictive calculations, and parameter results updating during training. Hence, there is a constant demand for flexible memory expansion and memory sharing among devices to meet the urgent need for rapid data access while maintaining coherency within the system.
Compute Express Link® (CXL®) was created to address these problems through CXL.mem, which offers memory expansion, memory sharing, and CXL.cache to ensure data coherency within the fabric; all while maintaining the basic PCIe structures for communication via CXL.io.
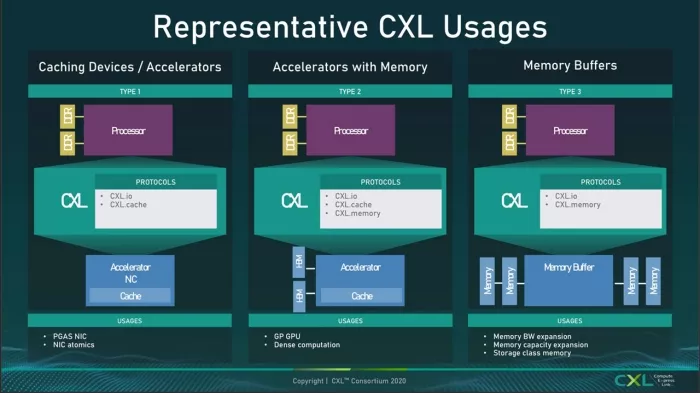
Source: From CXL Consortium
Every AI parameter must be stored in memory during both training and inference. These iterative processes require substantial memory storage for both training and processing temporal data. Traditionally, when local RAM reaches capacity, data is stored in physical memory, such as an external SSD or host memory. This type of transfer typically experiences long latency due to the translation drag time between virtual and physical addresses as well as the longer access times associated with external flash memory or host memory compared to accessing local RAM and DDR memory.
Addressing the demand for memory expansion, the CXL memory expander allows devices to extend their local RAM memory to external DDR memory modules. This centralized resource is then treated as a shared pool managed by system software, such as hypervisors. By virtualizing them as a single, unified resource for applications, system software can dynamically allocate memory based on workload demand, improving performance, enhancing memory usage efficiency, and resolving the issue of underutilized memory assigned locally to individual devices.
CXL architecture allows memory to connect as a separate device on the PCIe bus, enabling the addition of a CXL memory expander that can provide extra memory capacity without being restricted by the CPU's memory channels. In traditional architecture, the CPU's capacity is limited by the number of memory channels, each of which contains several DIMM slots. As the demand for memory increases, adding new channels to CPUs becomes overly complex, expensive, and results in high-power consumption, particularly if the channels were previously underutilized for low-performance applications. The CXL memory expander solution allows the expansion and dynamic allocation of memory devices on the PCIe bus, bypassing the restrictions of the traditional memory channel bottleneck and enabling AI systems to scale effectively, meeting the growing demands of current and future complex AI applications.
Beyond its memory expansion capability, CXL facilitates memory pooling and resource sharing across multiple devices to enhance AI processing. With CXL, multiple processors, GPUs, and AI accelerators can access the same shared memory pool, facilitating efficient resource utilization. AI systems are then able to dynamically allocate memory as workloads grow, eliminating the constraints of traditional, fixed-memory architecture. This flexibility allows for the intensive memory requirements of large AI models, such as GPT-4. In addition, CXL's disaggregated architecture optimizes resource utilization and overall system efficiency, making it a perfect fit for AI workloads.
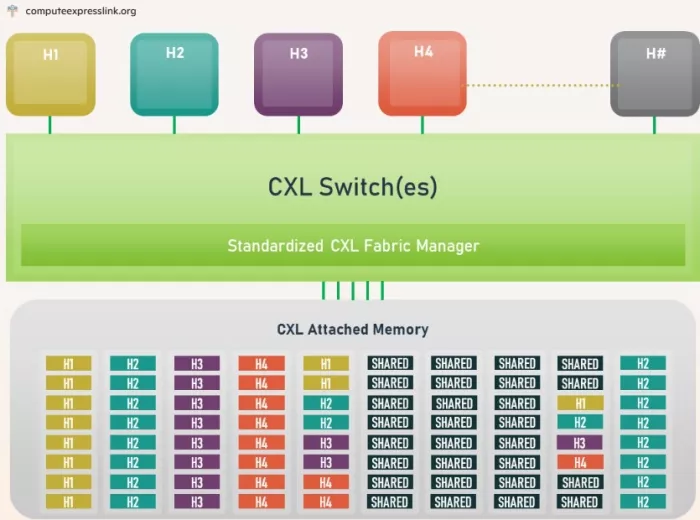
Source: From CXL Consortium
CXL also ensures cache coherency between the CPU and attached memory devices, maintaining consistent data across all devices. This enables seamless integration and efficient data sharing while avoiding delays caused by redundant memory management. With cache coherency, updates made by one device are immediately visible to other devices within the system. This reduces the need to transfer data between devices and saves both time and power while ensuring consistency during AI training or inference tasks. Most importantly, CXL cache coherency eliminates inconsistencies that could lead to incorrect computations, stale data, or race conditions during parallel data computations across multiple devices within an AI system.
CXL's low-latency architecture significantly enhances communication between CPUs, GPUs, and accelerators, making it crucial for real-time AI applications such as autonomous vehicles and financial trading, where delays can undermine performance. With advanced features like memory expander, memory pooling, memory sharing, and cache coherency, CXL architecture optimizes the performance of AI/ML tasks and is particularly effective for handling complex AI workloads like vector databases and large language models (LLMs). These features ensure that demanding workloads have the necessary memory bandwidth and resources to operate efficiently with minimal latency.
The Cadence CXL controller offers advanced CXL3.X solutions to ensure our customers' success. Contact the Cadence Sales team for more information.
Related Semiconductor IP
- CXL 4 Verification IP
- VIP for Compute Express Link (CXL)
- CXL 3.0 Controller
- CXL Controller
- CXL 4.0/3.2/3/2 Verification IP
Related Blogs
- Boosting Data Center Performance to the Next Level with PCIe 6.0 & CXL 3.0
- Unleashing Leading On-Device AI Performance and Efficiency with New Arm C1 CPU Cluster
- Desktop-Quality Ray-Traced Gaming and Intelligent AI Performance on Mobile with New Arm Mali G1-Ultra GPU
- How CXL 3.0 Fuels Faster, More Efficient Data Center Performance
Latest Blogs
- Ensuring reliability in Advanced IC design
- A Closer Look at proteanTecs Health and Performance Management Solutions Portfolio
- Enabling Memory Choice for Modern AI Systems: Tenstorrent and Rambus Deliver Flexible, Power-Efficient Solutions
- Verification Sanity in Chiplets & Edge AI: Avoid the “Second Design” Trap
- Embedded Security explained: Cryptographic Hash Functions