Time-of-Flight Decoding with Tensilica Vision DSPs - AI's Role in ToF Decoding
In our previous blog, we discussed the fundamentals of time-of-flight (ToF) technology, including the signal processing requirements for pre-processing and decoding ToF sensor data. We also examined how Tensilica Vision DSPs meet the computational demands while ensuring energy efficiency. In case you missed it, here's the link to the previous post.
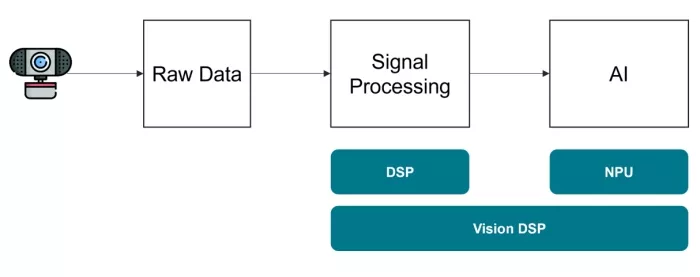
Building on that, today we will examine how artificial intelligence is being utilized for ToF decoding and the shift in computational requirements from traditional signal processing to neural network-based approaches. We will also explore how Cadence Tensilica Vision DSPs are facilitating these advancements.
Artificial Intelligence, particularly deep learning with Transformer networks, is increasingly vital in ToF sensing. It enhances the quality of depth data and facilitates higher-level scene understanding based on 3D information. Transformers, originally designed for natural language processing, have demonstrated powerful capabilities in computer vision due to their ability to model long-range dependencies and global context within data through self-attention mechanisms. This makes them highly effective for tasks requiring a comprehensive understanding of spatial relationships, such as those found in 3D depth data. Tensilica Vision DSPs, with their strong AI inference capabilities, provide an efficient platform for deploying these AI algorithms in addition to the classical pre-processing at the edge.
AI for Improving Depth Quality
AI presents innovative solutions for improving the quality of raw depth data from iToF sensors, overcoming limitations of traditional filtering methods when dealing with complex artifacts. Key AI-powered enhancement techniques include:
- AI Denoising: Deep learning models, including those based on Transformers, can surpass classical filters in removing noise. They learn to differentiate between noise and subtle structural details, leading to clearer, more accurate depth maps. Transformers excel at this by analyzing global patterns in the depth data to identify and suppress noise effectively.
- MPI Reduction: Multipath Interference (MPI) is a challenging systematic error in iToF. AI techniques, including Transformer-based models, are being used to understand and reduce the impact of MPI, either by correcting distorted depth values or by identifying and masking affected pixels. The self-attention mechanism in Transformers can help in recognizing complex MPI patterns and correcting them based on a wider contextual understanding of the scene.
- Depth Completion and Super-Resolution: ToF depth maps can have missing data points due to low signal return or filtering. AI models, such as those leveraging Transformer architectures, can intelligently fill in missing depth data (holes) and enhance the effective resolution of depth maps beyond the sensor's original capability. Transformers' ability to capture global relationships makes them well-suited for inferring missing information and generating high-resolution outputs from lower-resolution inputs.
- Motion Artifact Correction: In dynamic scenes, motion during sensor integration can cause blurring or distortions. AI techniques, including Transformer-based approaches, are being developed to detect and compensate for motion-induced blurring or distortions, enhancing depth accuracy for moving objects or during camera movement. Transformers can analyze sequences of depth frames to understand motion patterns and apply corrections.
Integrating these AI enhancement techniques early in the processing pipeline, potentially on the same Vision DSP used for initial decoding, can significantly boost the quality and reliability of the final depth output before it's used for subsequent tasks. This signifies a move towards leveraging AI to actively refine and correct sensor data, not just interpret it.
AI for Scene Understanding
AI algorithms significantly enhance the utility of ToF sensor data beyond just improving depth information. By extracting semantic meaning and facilitating advanced perception, often in combination with other sensors like RGB cameras, AI unlocks sophisticated environmental understanding through 3D data.
Key applications of AI-powered perception using ToF data include:
- Object Detection and Recognition: Leveraging geometric information from ToF point clouds or depth maps, AI models can reliably detect and classify objects like pedestrians, vehicles, and furniture in diverse settings, thus augmenting traditional 2D object detection.

- Semantic Segmentation: AI enables pixel-level classification of depth maps, assigning semantic labels (e.g., road, person, building). This detailed, spatially-aware scene understanding is vital for navigation and interaction in robotics and automotive contexts.
- Gesture Recognition: The 3D data from ToF provides a strong foundation for accurate hand gesture recognition. AI models can analyze 3D hand poses derived from ToF to interpret intricate gestures for human-computer interaction in automotive interiors, AR/VR systems, and smart devices.
- Face Detection and Authentication: ToF-generated depth information improves face detection and facilitates 3D facial recognition for secure authentication or driver/occupant identification, potentially offering greater resistance to spoofing compared to 2D approaches.

The integration of ToF sensing and efficient edge AI processing empowers systems with these AI-driven perception capabilities, enabling a shift from basic distance measurement to a more complete and actionable comprehension of their surroundings.
Vision DSPs as Efficient AI Inference Engines
Tensilica Vision DSPs, particularly the Vision 331/341 series, are engineered as efficient, high-performance engines for both traditional vision tasks and AI inference at the edge. Their architecture incorporates several key features:
- High MAC Throughput: Leveraging wide SIMD units, these DSPs deliver substantial multiply-accumulate (MAC) performance. For instance, Vision 331 DSP offers 512-bit SIMD while Vision 341 DSP offers 1024-bit SIMD and provides 2X MAC capability compared to Vision 331 DSP. The 128-bit Tensilica Vision 110 DSP and 512-bit Vision 130 DSP also offer AI performance enhancements, with improvements on specific kernels. This enables rapid processing of the convolutional and fully connected layers prevalent in convolutional neural networks (CNNs).
- Optimized Data Type Support: The DSPs efficiently handle the integer (8-bit and 16-bit) and half-precision floating-point (FP16, on VFPU-equipped cores) data types commonly found in optimized AI models. This reduces memory usage and bandwidth requirements compared to FP32 inference, while maintaining adequate accuracy for many applications.
- High Memory Bandwidth: Neural networks, including Transformer models, rely on extensive weight parameters and intermediate feature map data. The high-bandwidth local memory subsystem prevents data starvation for the compute units. Additionally, coefficient decompression techniques further optimize memory bandwidth.
- Comprehensive Software Ecosystem: The NeuroWeave SDK automatically translates neural networks from standard frameworks (TensorFlow, Caffe, ONNX, etc.) into highly optimized code tailored for the Vision DSP architecture. By utilizing Cadence's hand-optimized NN library functions, NeuroWeave simplifies hardware-specific optimization for AI developers, accelerating the development cycle.
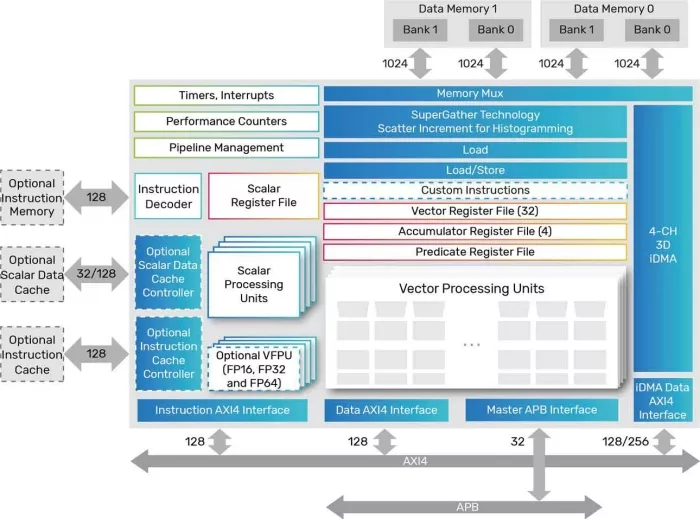
Vision DSPs offer a dedicated architecture capable of running all neural network layers (convolution, fully connected, pooling, normalization, and self-attention mechanisms crucial for Transformers) efficiently in a standalone manner. This minimizes power consumption and data movement compared to approaches that distribute NN execution across a DSP and a separate hardware accelerator. The Vision 331/341 series provides an integrated solution that is adept at both traditional vision/imaging pre/post-processing and AI inference on a single core.
The capacity to efficiently execute the intensive signal processing of iToF decoding alongside subsequent AI-driven enhancement and perception tasks on a unified, programmable, and power-efficient platform positions Tensilica Vision DSPs as a compelling choice for enabling advanced 3D sensing capabilities at the edge.
Stay tuned for the next post, where we will explore how ToF can be used in Automotive.
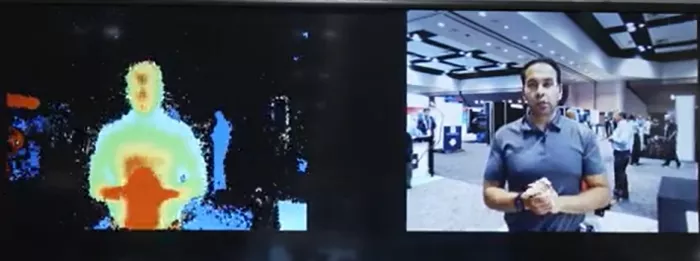
In the meantime, take a look at this video of the ToF decoding running on Vision DSP that was showcased at CES 2025 and most recently at CadenceLive Silicon Valley. There are tons of resources online if you want to dive deeper into the details of Vision DSPs.
Related Semiconductor IP
- Tensilica Vision Q7 DSP
- Vision AI DSP
- Tensilica Vision P1 DSP
- Tensilica Vision P6 DSP
- Tensilica Vision Q8 DSP
Related Blogs
- Next-Gen Cadence Tensilica Vision Processor Core Claims Big Performance, Energy Consumption Gains
- Tensilica Vision P6 Processor Core Adopts Deep Learning-Focused Enhancements
- A New Era Needs a New Architecture: The Tensilica Vision Q6 DSP
- Tensilica 5th Generation DSP: Mix of Vision and AI
Latest Blogs
- Area, Pipelining, Integration: A Comparison of SHA-2 and SHA-3 for embedded Systems.
- Why Your Next Smartphone Needs Micro-Cooling
- Teaching AI Agents to Speak Hardware
- SOCAMM: Modernizing Data Center Memory with LPDDR6/5X
- Bridging the Gap: Why eFPGA Integration is a Managed Reality, Not a Schedule Risk