Arithmetic Mathematic IP
Welcome to the ultimate Arithmetic Mathematic IP hub! Explore our vast directory of Arithmetic Mathematic IP
All offers in
Arithmetic Mathematic IP
Filter
Compare
81
Arithmetic Mathematic IP
from
19
vendors
(1
-
10)
-
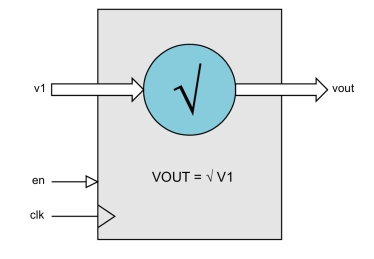
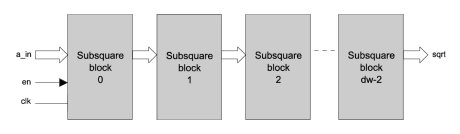
Pipelined Square Root
- PIPE_SQRT is a pipelined square-root with configurable data width.
- The design is fully scalable and modular permitting the user to specify large bit widths without compromising maximum attainable clock speed.
-
Sine Function
- SIN_X calculates the sine of an angle. It has a fully pipelined architecture and uses fixed-point mathematics throughout.
- Input values are accepted as 16-bit unsigned values in the range 0 to π/2.
- Output values are 16-bit unsigned values in the range 0 to 1.
-
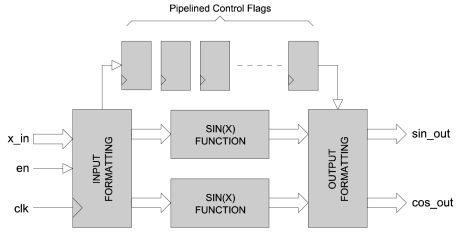
18-bit Sine/Cosine Function
- SINCOS_X calculates the sine and cosine of an angle in radians.
- It has a fully pipelined architecture and uses fixed-point mathematics throughout.
- Input values are accepted as 18-bit signed values in the range -π to π.
- Output values are 17-bit signed values in the range -1 to 1.
-
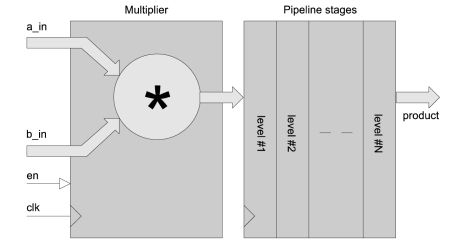
Pipelined Multiplier with generic width and depth
- Function y = a * b is a high-speed multiplier with configurable width and depth.
- Inputs and outputs may be specified as either signed or unsigned values.
- Forms a fundamental building block in all digital processing functions.
-
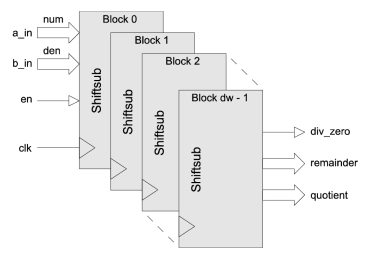
Pipelined Divider
- Function y = a / b is a very high-speed divider with configurable dividend and divisor width.
- Inputs and outputs may be specified as either signed or unsigned values.
- Generates the quotient and remainder after division and includes a flag for a divide by zero exception.
- Fully scalable alternative to using large LUT-based dividers.
-
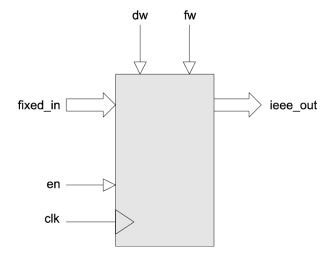
Fixed-point to 32-bit floating-point converter
- Converts fixed-point numbers to 32-bit floating-point representation. The fixed-point input has a configurable word and fraction width.
- Floating-point outputs are based on the IEEE 754 standard.
- The design features a high-speed, fully pipelined architecture with a 2 clock-cycle latency.
-
16-bit Cosine Function
- COS_X calculates the cosine of an angle in radians.
- It has a fully pipelined architecture and uses fixed-point mathematics throughout.
- Input values are accepted as 16-bit unsigned values in the range 0 to π/2.
- Output values are 16-bit unsigned values in the range 0 to 1.
-
4-Quadrant Arctan Function
- ATAN2_XY calculates the 4-quadrant inverse tangent in the range -π to π. It has a fully pipelined architecture and uses fixed-point mathematics throughout.
- Input values are accepted as 12-bit signed numbers in the range -2048 to 2047.
- The calculated output phase (in radians) is a 19-bit signed value with 1 sign bit, 2 integer bits and 16 fractional bits.
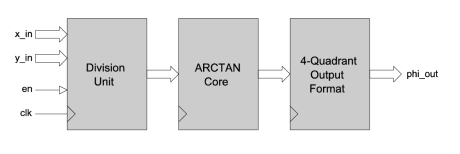
-
Arctan Function
- ATAN_X calculates the inverse tangent of a fraction. It has a fully pipelined architecture and uses fixed-point mathematics throughout.
- Input values are accepted as 16-bit unsigned fractions in the range 0 to 1. Output values are 16-bit unsigned fractions in the range 0 to π/4.
- Both input and output values are in [16 16] format with 0 integer bits and 16 fraction bits.
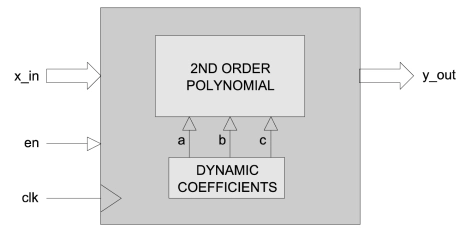
-
32-bit Floating-point Square-root IP Core
- High-speed fully pipelined 32-bit floating-point square-root function based on the IEEE 754 standard. Features a generic latency from 2 to 24 clock cycles.
- Ideal for floating-point pipelines, arithmetic units and processors.