NPU Processor IP Cores
NPU (Neural Processing Unit) Processor IP cores provide high-performance computing power for tasks such as image recognition, natural language processing, and data analysis, enabling real-time AI processing at the edge.
All offers in
NPU Processor IP Cores
Filter
Compare
50
NPU Processor IP Cores
from
13
vendors
(1
-
10)
-
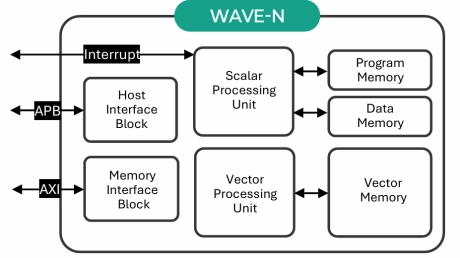
Specialized Video Processing NPU IP for SR, NR, Demosaic, AI ISP, Object Detection, Semantic Segmentation
- WAVE-N is a high-performance, video-specialized NPU IP designed to deliver real-time, deep learning-based image enhancement for edge devices.
- By utilizing a proprietary 'Line-by-Line' processing architecture, it significantly reduces DRAM bandwidth and achieves 4x to 10x faster processing speeds compared to conventional NPUs.
-
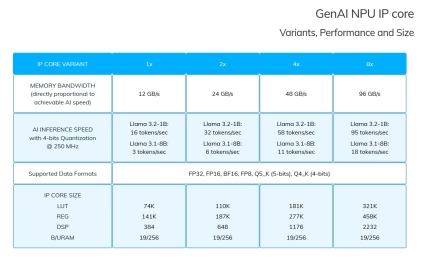
Embedded AI accelerator IP
- The GenAI IP is the smallest version of our NPU, tailored to small devices such as FPGAs and Adaptive SoCs, where the maximum Frequency is limited (<=250 MHz) and Memory Bandwidth is lower (<=100 GB/s).
-
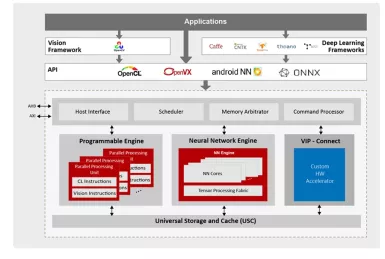
NPU IP for AI Vision and AI Voice
- 128-bit vector processing unit (shader + ext)
- OpenCL 3.0 shader instruction set
- Enhanced vision instruction set (EVIS)
- INT 8/16/32b, Float 16/32b
-
NPU IP for Wearable and IoT Market
- ML inference engine for deeply embedded system
NN Engine
Supports popular ML frameworks
Support wide range of NN algorithms and flexible in layer ordering
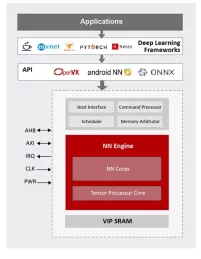
- ML inference engine for deeply embedded system
-
NPU IP for Data Center and Automotive
- 128-bit vector processing unit (shader + ext)
- OpenCL 1.2 shader instruction set
- Enhanced vision instruction set (EVIS)
- INT 8/16/32b, Float 16/32b in PPU
- Convolution layers
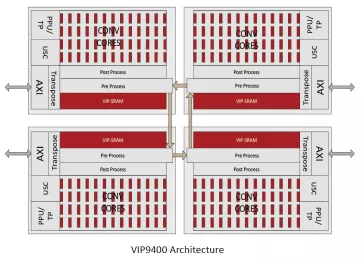
-
RISC-V-Based, Open Source AI Accelerator for the Edge
- Coral NPU is a machine learning (ML) accelerator core designed for energy-efficient AI at the edge.
- Based on the open hardware RISC-V ISA, it is available as validated open source IP, for commercial silicon integration.
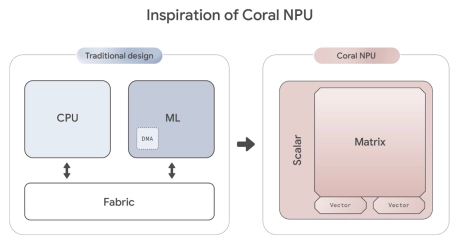
-
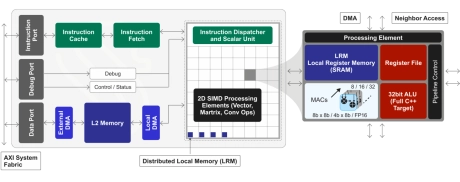
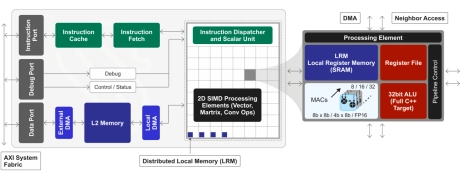
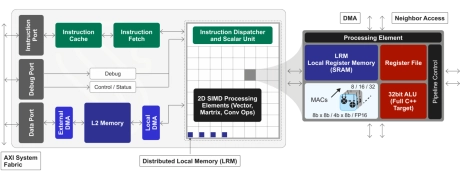
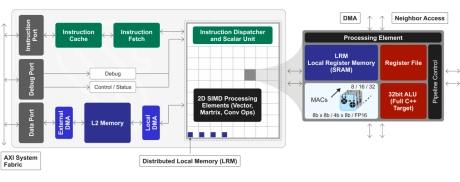
GPNPU Processor IP - 32 to 864TOPs
- 32 to 864TOPs
- (Dual, Quad, Octo Core) Up to 256K MACs
- Hybrid Von Neuman + 2D SIMD matrix architecture
- 64b Instruction word, single instruction issue per clock
- 7-stage, in-order pipeline
- Scalar / vector / matrix instructions modelessly intermixed with granular predication
-
-
-