RoMe: Row Granularity Access Memory System for Large Language Models
By Hwayong Nam †, Seungmin Baek †, Jumin Kim †, Michael Jaemin Kim ‡, and Jung Ho Ahn †
Seoul National University †, Meta ‡
Abstract
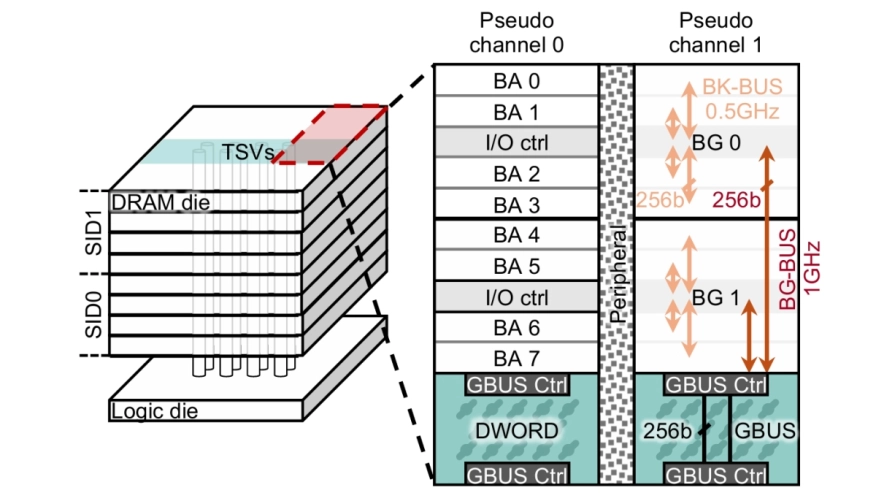
Modern HBM-based memory systems have evolved over generations while retaining cache line granularity accesses. Preserving this fine granularity necessitated the introduction of bank groups and pseudo channels. These structures expand timing parameters and control overhead, significantly increasing memory controller scheduling complexity. Large language models (LLMs) now dominate deep learning workloads, streaming contiguous data blocks ranging from several kilobytes to megabytes per operation. In a conventional HBM-based memory system, these transfers are fragmented into hundreds of 32B cache line transactions. This forces the memory controller to employ unnecessarily intricate scheduling, leading to growing inefficiency.
To address this problem, we propose RoMe. RoMe accesses DRAM at row granularity and removes columns, bank groups, and pseudo channels from the memory interface. This design simplifies memory scheduling, thereby requiring fewer pins per channel. The freed pins are aggregated to form additional channels, increasing overall bandwidth by 12.5% with minimal extra pins. RoMe demonstrates how memory scheduling logic can be significantly simplified for representative LLM workloads, and presents an alternative approach for next-generation HBM-based memory systems achieving increased bandwidth with minimal hardware overhead.
To read the full article, click here
Related Semiconductor IP
- HBM 4 Verification IP
- Verification IP for HBM
- Simulation VIP for HBM
- HBM Synthesizable Transactor
- HBM DFI Synthesizable Transactor
Related Articles
- SV-LLM: An Agentic Approach for SoC Security Verification using Large Language Models
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- Scaling On-Device GPU Inference for Large Generative Models
- Customizing a Large Language Model for VHDL Design of High-Performance Microprocessors
Latest Articles
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks