OmniSim: Simulating Hardware with C Speed and RTL Accuracy for High-Level Synthesis Designs
By Rishov Sarkar and Cong Hao
Georgia Institute of Technology
Abstract
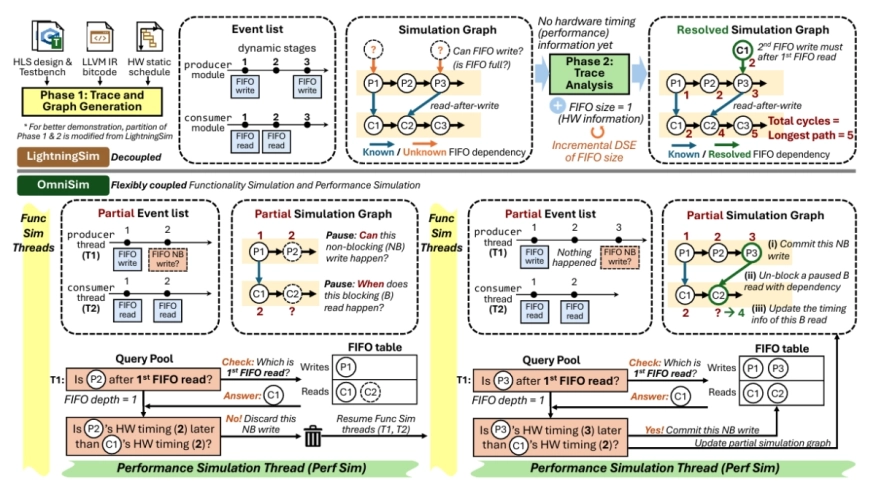
High-Level Synthesis (HLS) is increasingly popular for hardware design using C/C++ instead of Register-Transfer Level (RTL). To express concurrent hardware behavior in a sequential language like C/C++, HLS tools introduce constructs such as infinite loops and dataflow modules connected by FIFOs. However, efficiently and accurately simulating these constructs at C level remains challenging. First, without hardware timing information, functional verification typically requires slow RTL synthesis and simulation, as the current approaches in commercial HLS tools. Second, cycle-accurate performance metrics, such as end-to-end latency, also rely on RTL simulation. No existing HLS tool fully overcomes the first limitation. For the second, prior work such as LightningSim partially improves simulation speed but lacks support for advanced dataflow features like cyclic dependencies and non-blocking FIFO accesses.
To overcome both limitations, we propose OmniSim, a framework that significantly extends the simulation capabilities of both academic and commercial HLS tools. First, OmniSim enables fast and accurate simulation of complex dataflow designs, especially those explicitly declared unsupported by commercial tools. It does so through sophisticated software multi-threading, where threads are orchestrated by querying and updating a set of FIFO tables that explicitly record exact hardware timing of each FIFO access. Second, OmniSim achieves near-C simulation speed with near-RTL accuracy for both functionality and performance, via flexibly coupled and overlapped functionality and performance simulations.
We demonstrate that OmniSim successfully simulates eleven designs previously unsupported by any HLS tool, achieving up to 35.9x speedup over traditional C/RTL co-simulation, and up to 6.61x speedup over the state-of-the-art yet less capable simulator, LightningSim, on its own benchmark suite.
Keywords
Dataflow Designs, Design Simulation, High-Level Synthesis
To read the full article, click here
Related Semiconductor IP
- UCIe D2D Adapter & PHY Integrated IP
- Low Dropout (LDO) Regulator
- 16-Bit xSPI PSRAM PHY
- MIPI CSI-2 CSE2 Security Module
- ASIL B Compliant MIPI CSI-2 CSE2 Security Module
Related Articles
- Veri-Sure: A Contract-Aware Multi-Agent Framework with Temporal Tracing and Formal Verification for Correct RTL Code Generation
- QiMeng: Fully Automated Hardware and Software Design for Processor Chip
- RTL synthesis requirements for advanced node designs
- Creating SoC Designs Better and Faster With Integration Automation
Latest Articles
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks