FlexLLM: Composable HLS Library for Flexible Hybrid LLM Accelerator Design
By Jiahao Zhang 1, Zifan He 1, Nicholas Fraser 2, Michaela Blott 2, Yizhou Sun 1, Jason Cong 1
1 Computer Science, University of California, Los Angeles, California
2 AMD, Dublin, Ireland
Abstract
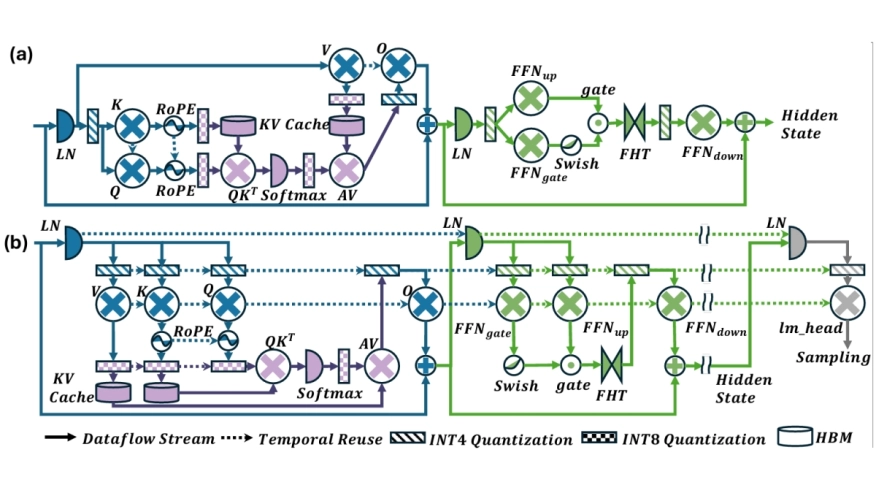
We present FlexLLM, a composable High-Level Synthesis (HLS) library for rapid development of domain-specific LLM accelerators. FlexLLM exposes key architectural degrees of freedom for stage-customized inference, enabling hybrid designs that tailor temporal reuse and spatial dataflow differently for prefill and decode, and provides a comprehensive quantization suite to support accurate low-bit deployment. Using FlexLLM, we build a complete inference system for the Llama-3.2 1B model in under two months with only 1K lines of code. The system includes: (1) a stage-customized accelerator with hardware-efficient quantization (12.68 WikiText-2 PPL) surpassing SpinQuant baseline, and (2) a Hierarchical Memory Transformer (HMT) plug-in for efficient long-context processing. On the AMD U280 FPGA at 16nm, the accelerator achieves 1.29× end-to end speedup, 1.64× higher decode throughput, and 3.14× better energy efficiency than an NVIDIA A100 GPU (7nm) running BF16 inference; projected results on the V80 FPGA at 7nm reach 4.71×, 6.55×, and 4.13×, respectively. In long-context scenarios, integrating the HMT plug-in reduces prefill latency by 23.23× and extends the context window by 64×, delivering 1.10×/4.86× lower end-to-end latency and 5.21×/6.27× higher energy efficiency on the U280/V80 compared to the A100 baseline. FlexLLM thus bridges algorithmic innovation in LLM inference and high-performance accelerators with minimal manual effort.
To read the full article, click here
Related Semiconductor IP
- UCIe D2D Adapter & PHY Integrated IP
- Low Dropout (LDO) Regulator
- 16-Bit xSPI PSRAM PHY
- MIPI CSI-2 CSE2 Security Module
- ASIL B Compliant MIPI CSI-2 CSE2 Security Module
Related Articles
- ChipBench: A Next-Step Benchmark for Evaluating LLM Performance in AI-Aided Chip Design
- Assessing Design Space for the Device-Circuit Codesign of Nonvolatile Memory-Based Compute-in-Memory Accelerators
- The Quest for Reliable AI Accelerators: Cross-Layer Evaluation and Design Optimization
- Open-Source Design of Heterogeneous SoCs for AI Acceleration: the PULP Platform Experience
Latest Articles
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks