A Reconfigurable Framework for AI-FPGA Agent Integration and Acceleration
By Aybars Yunusoglu 1, Talha Coskun 2, Hiruna Vishwamith 3, Murat Isik 4, I. Can Dikmen 5
1 Purdue University, West Lafayette, USA
2 University of Illinois, Urbana-Champaign, Urbana, USA
3 University of Moratuwa, Moratuwa, Sri Lanka
4 Stanford University, Stanford, USA
5 Istinye University, Istanbul, Turkey
Abstract
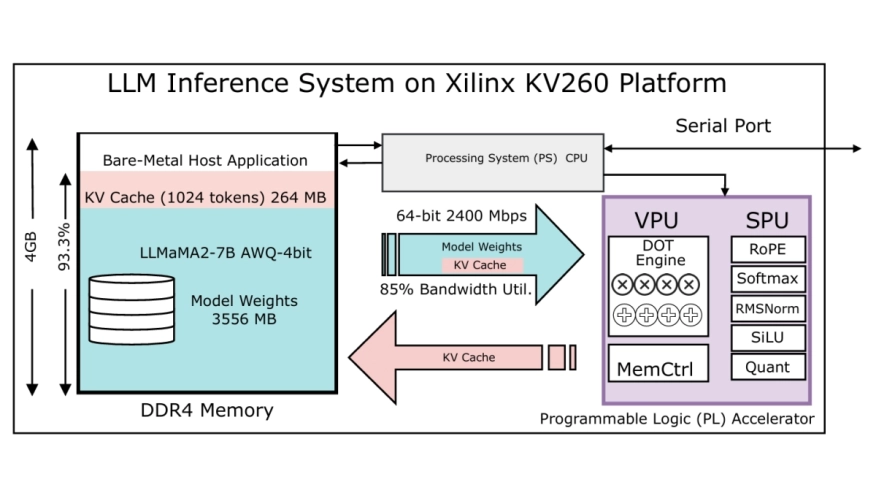
Artificial intelligence (AI) is increasingly deployed in real-time and energy-constrained environments, driving demand for hardware platforms that can deliver high performance and power efficiency. While central processing units (CPUs) and graphics processing units (GPUs) have traditionally served as the primary inference engines, their general-purpose nature often leads to inefficiencies under strict latency or power budgets. Field-Programmable Gate Arrays (FPGAs) offer a promising alternative by enabling custom-tailored parallelism and hardware-level optimizations. However, mapping AI workloads to FPGAs remains challenging due to the complexity of hardware-software co-design and data orchestration. This paper presents AI FPGA Agent, an agent-driven framework that simplifies the integration and acceleration of deep neural network inference on FPGAs. The proposed system employs a runtime software agent that dynamically partitions AI models, schedules compute-intensive layers for hardware offload, and manages data transfers with minimal developer intervention. The hardware component includes a parameterizable accelerator core optimized for high-throughput inference using quantized arithmetic. Experimental results demonstrate that the AI FPGA Agent achieves over 10x latency reduction compared to CPU baselines and 2-3x higher energy efficiency than GPU implementations, all while preserving classification accuracy within 0.2% of full-precision references. These findings underscore the potential of AI-FPGA co-design for scalable, energy-efficient AI deployment.
To read the full article, click here
Related Semiconductor IP
- UCIe D2D Adapter & PHY Integrated IP
- Low Dropout (LDO) Regulator
- 16-Bit xSPI PSRAM PHY
- MIPI CSI-2 CSE2 Security Module
- ASIL B Compliant MIPI CSI-2 CSE2 Security Module
Related Articles
- CD-PIM: A High-Bandwidth and Compute-Efficient LPDDR5-Based PIM for Low-Batch LLM Acceleration on Edge-Device
- Veri-Sure: A Contract-Aware Multi-Agent Framework with Temporal Tracing and Formal Verification for Correct RTL Code Generation
- A novel 3D buffer memory for AI and machine learning
- Interstellar: Fully Partitioned and Efficient Security Monitoring Hardware Near a Processor Core for Protecting Systems against Attacks on Privileged Software
Latest Articles
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks