Dynamic Floorplanning: A Practical Method Using Relative Dependencies for Incremental Floorplanning
Ramaprasad Kadiyala, Philips Semiconductors, DV Platform Group, San Jose, CA
Mark Basel, Mentor Graphics, Wilsonville, Oregon 97070
ABSTRACT
Capturing the designer¡¦s intent during floorplanning plays a critical role to improve design productivity of systems-on-chip (SoC). This paper presents a design technique which helps manage changes very late in the design process caused by the concurrent implementation of blocks in a hierarchical layout.
We developed a floorplan description language and associated a methodology to capture the actual designer¡¦s intent for block placement, soft macro shaping, JTAG cell placement, power grid and power rings design.
The concept allows re-use of the description and therefore fast iterations during incremental changes at the top level or at the block level. This technique can accommodate changes very late in the design process by removing tedious manual adjustment of the hierarchical layout.
This approach has successfully been applied on a complex SoC and IP block implementation .It has demonstrated a reduction from one day to few minutes for a floorplan iteration, crucial in a concurrent design environment where asynchronous changes in the blocks require to constantly revisit the top level layout and vice versa.
1. INTRODUCTION
As designs become larger and more complex, the use (and re-use) of hard and soft IP is mandatory to achieve reasonable time to market. With dispersed teams, for a better control on timing performances as well as for a better usage of the EDA tools, hierarchical design approach is rapidly becoming a necessity for SoC implementation.
While the block implementation still faces technology challenges, it has reached a level of automation where once the physical and timing constraints are given, a block can essentially be ¡§compiled¡¨ to a GDSII file.
At the chip level on the other hand, the degree of automation in floorplanning tasks is either non existent or at best inappropriate to capture and take into account the chip level constraints that are necessary to allow fast automated design iterations.
Some existing literature [1],[2],[3],[4],[5] focuses on algorithm to fully automate the generation of the initial chip ¡¥s floorplan, shaping flexible blocks and placing macros. Although efficient to explore initial topology such approaches usually have limited usage in incremental iterations since they rely on regenerating the solution each time, discarding the manual refinement (as illustrated in figure 1) that always takes place between the initial topology and the subsequent iterations.
The primary objective in our approach is the capture of the designer¡¦s intent using dedicated constraints with associated priorities which guide what constraints should be obeyed preferably when overlaps are detected in later incremental iterations.
Despite improvements in hierarchical design methodology, many optimizations don't occur because blocks are implemented separately and inter-block dependencies are not visible and addressed "globally". In an ideal top-down approach the initial partitioning, block sizing, power grid planning, etc. is perfect the first time. The blocks returned after implementation fit exactly and the design moves on to chip level tasks. In reality designs proceed iteratively. For example, a block may require slightly more area than was budgeted. In the process of integrating this block the chip architect has to alter the placement of surrounding blocks (at a minimum). More likely this small change will also affect the power grid, pin placement and numerous other items. By automating this rippling effect, small changes from the previous block implementation require fewer manual operations (Figure 1b) resulting in faster iteration cycles.
In this paper, we present a chip design method enabling faster design iterations, which incorporates a means of creating a floorplan by relative references. The main goal is not to reduce the number of iterations but to develop a hierarchical layout flow where the unnecessary recurrent manual tuning work is replaced with ¡§design knowledge aware¡¨ semi-automated refinement
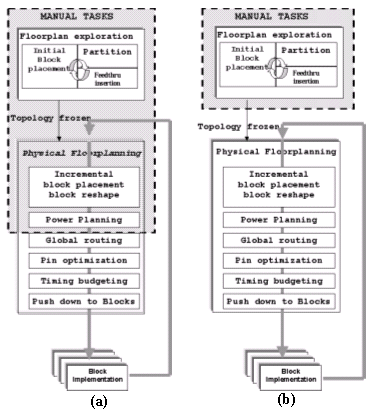
Figure 1 (a) Typical Chip level floorplanning flow with manual tasks on the iteration paths. (b) The proposed flow with floorplan automation added for the incremental changes.
2. PROBLEM DESCRIPTION
Traditional formats for storing physical design data usually store the location of each object relative to a single reference (e.g. the origin). While this convention works well to capture a static design it is not flexible enough in the design process early stages when changes are common. A more symbolic approach is better suited. This method should capture the designer¡¦s floorplan intents as opposed to the designer¡¦s floorplan static picture.
In figure 2 (a), the designer¡¦s intent is: ¡§The hard macro HM1 must be located in the upper left corner of the core and soft block SB1 always need to be placed on the right side of HM1 and have the same height¡¨. Current floorplan exchange formats such as DEF are based on absolute coordinates such as P1(x¡¦,y¡¦) and P2(x¡¨,y¡¨):
DEF:
- InstanceHM1 HM1 + PLACED ( x¡¦ y¡¦ ) FN ;
- InstanceSM1 SM1 + PLACED ( x¡¨ y¡¨ ) N ;
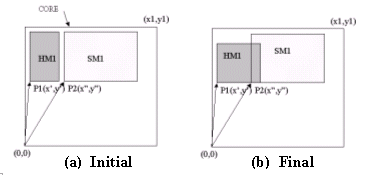
Figure 2: Floorplan using traditional absolute coordinates
Figure 2 (b) shows the result of applying the initial design absolute floorplan information to the final design, where the hard macro HM1 has changed. Clearly enough, this results in the overlapping of the 2 blocks. None of these coordinates are actually meaningful anymore. Manual work is required to re-establish the original design intent.
In a SoC design, composed of hundreds of hard macros and numerous top level soft blocks, this process of manually readjusting the floorplan can quickly grow unmanageable and time consuming.
Creating a hierarchical floorplan is both a concurrent and iterative process in which chip-down constraints, and module-up implementation need constant readjustment. The shape of the blocks, hard macros as well as their position will change frequently. Additionally, the power grid structure, the IO ring layout will also change as the physical architecture is refined. These changes (size, congestion, utilization, slack, shapes¡K) must be easily and automatically propagated to the top level as the understanding of the design solidifies.
The rest of this paper presents a new methodology based on a new relative floorplan description language developed to capture the designer¡¦s intent and speed-up the design iterations.
3. THE PROPOSED METHOD
We propose to always describe the position or shape of an object in the floorplan relatively to the most relevant other object it depends on. Figure 3 (a) depicts the proposed approach, which consists in capturing the relevant floorplan information for future design iterations.
# 1- Hard Macro instance in the top left of the corebox
HM1 TL corebox
#2- Soft Macro instance is placed on the right of HM1
SM1 RightOf HM1
# 3-Soft macro instance has same height as hard macro
SM1 sameHeight HM1
Figure 3 (b) shows the result of applying the initial design relative floorplan information to the final design. Clearly, the designer¡¦s intents have been correctly restituted : Block HM1 is positioned back in the upper left corner of the core. The SM1 has been re shaped to have the same height as HM1 and is located on the right of HM1 without overlapping it.
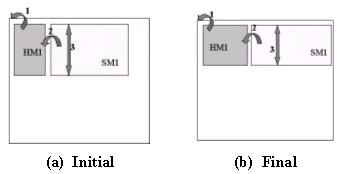
Figure 3: Floorplan using relative references
From the architecture exploration phase, all the way to the final physical design implementation the complete SoC floorplan is gradually refined. The relative position and dependencies of the blocks, power grids, power ring, pins, JTAG blocks, etc are captured. Any changes such as pad ring, pad order, hard macro size or aspect ratio, soft macro size, soft macro aspect ratio, chip¡¦s core size, power grid specification, is then automatically propagated.
3.1 Macro Placement by Relative Placement
We describe the macro placement hierarchically by referencing each object through a 2-tuple pair {reference Point, Quadrant}: Placement of hard and soft macros is defined relative to anchor points such as the corners of each macros instance. The use of quadrant and offsets provides additional flexibility for describing the placement of an object around the reference point.
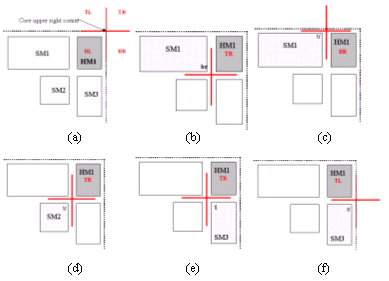
Figure 4 : HM1 placement can be described in 6 ways :
(b) { Reference Point , Quadrant } „³ { br SM1, TR }
(c) { Reference Point , Quadrant } „³ { tr SM1, BL }
(d) { Reference Point , Quadrant } „³ { tr SM2, TR }
(e) { Reference Point , Quadrant } „³ { tl SM3, TR }
In figure 4, the Hard Macro HM1 can be placed by referencing the corner of any of the neighboring blocks together with the associated quadrant: Top Right (TR), Bottom Right (BR), Bottom Left (BL), Top Left (TL) are used for both referencing the corners or quadrants. The same neighboring block can as well be referenced using different quadrants. This gives the designer the flexibility of six different ways to capture the position of a block HM1 as opposed to a single absolute coordinate.
The following operations are used to generate the macro placement
- handplace: This construct will place an instance of a block in a specific orientation in the specified quadrant with a given spacing in both x and y directions.
- relativehandplace: This construct will place a given instance in the specified quadrant defined in reference to the corner of another instance.
Note that a similar approach was mentioned in [6]. We have extended the concept beyond just macro placement
Also, we group each macro placement within a block into clusters where each cluster has only one reference point defined relatively to the core boundary. Figure 5 shows an example with 3 clusters. Changes in the aspect ratio of block F will not affect the relative placement of the macros within their cluster.

Figure 5: Example of the macro placement section in the floorplan file for a block.
3.2 Soft Macro Relative Shaping
Similarly we define the shapes of soft macros through a {Reference Instance, Constrained edge} pair. The soft macro height or width is defined relative to an edge such as the space between two other macros, the height or width of another instance or relatively to any spacing between the core or pad and an instance. We use the following operations (Figure 6) to generate the soft macro shaping:
- reshape: This construct will change the shape (but not the area) of a soft block instance from a fixed corner {BL TR BR BL} with the dimension {W or H} specified by the user. An offset may also be used when more flexibility is needed.
- relativereshape: This construct is similar to the reshape command above except that instead of passing a value as the constraint, a second instance name is passed together with the dimension constrained.
- reshapebetween: This construct will reshape an instance from a fixed corner so that it fits between two other specified instances.
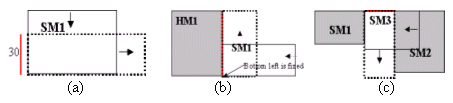
Fig6: (a)reshape, (b)relativereshape, (c) reshapebetween
These operations are used at the chip level where the dependencies of the shapes are captured after the hard macros and cores have been positioned as described previously. The top-level floorplan is manually written by order of importance of the constraints between blocks. In subsequent iterations, these constraints will be executed in the priority order.
The dependencies order is important because it may not be possible to automatically readjust the layout after an important change in one of the blocks. In such a case, this approach better manages the circular dependencies that can become unsolvable when a change¡¦s impact is too broad. Ordering allows the designer to guide the automated ripple effect and concentrate the top-level changes in specific less critical sections of the chips.
3.3 JTAG in Physical Design
This section describes a change tolerant method for boundary scan cell placement that provides a relative link between the cells and the pads they are associated with: When a pad is moved the associated scan cell moves with it. The scan cell placement becomes independent from the actual pad ordering.
The insertion of boundary scan logic usually is a post-processing step after the logical and structural test design has been completed. This design step requires input from the physical domain, such as the pad type and pad order. Effectively, the boundary scan cells need to be ordered in relation to the pads to minimize top-level connectivity. At Philips we use an internal tool to insert the JTAG logic as well as order the scan chain based on the pad ordering.
In addition, special care must be taken in the physical implementation with respect to the functional path to minimize the length of connections and maintain the timing performance. This requires the JTAG cells to be placed close to the Io pad.
Traditionally these dependencies on the physical design usually involve much manual floorplanning work when the JTAG cells are placed at the top of level of the physical hierarchy independent of their implementation as ¡§glue¡¨ logic or as JTAG macros. Each time the IO placement is changed due to packaging changes the boundary scan order, associated buffering, etc. must be reworked.
In this approach, for every change in the pad-ring order only the chain order in the netlist is changed. The placement of the boundary scan cells is re-generated automatically.
Figure 7 illustrates the relationship between a pad and its associated boundary-scan blocks. The construct used to setup the relationship is:
BstNextToPad Pad_A bst_A_oen 5 0
Where 5 and 0 represent the offsets in x and y directions with regards to the pad center.
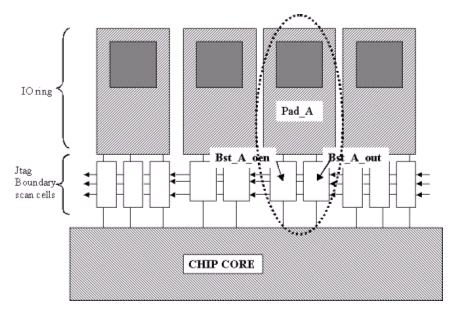
Figure 7 : Boundary scan blocks associated with Pad_A
3.4 Rectilinear Power Ring
Chip level power ring is dependant upon the positioning of hard macros as well as soft macro since it meanders between them to accommodate analog and digital power domains. Every change at the top level potentially requires to stretch and manually adjust the power structure. Here again, we use an approach, where the power ring is described such that ripple effect after changes is automated.
In figure 8 (a), we define a set of point P0, P1, P2 and P3 used to create the rectilinear ring. In figure 8(b) we show what the result of a change in the shape and size of the hard macro HM1 would have produced using absolute coordinates defined with respect to the origin. In figure 8 (c), the coordinates are computed automatically based on changes in HM1. Each coordinate is described as a {Object edge} pair.
P0 = ({Core L}, {Core B})
P1 = ({HM1 L}, {HM1 B})
P2 = ({HM1 R}, {HM1 B})
P3 = ({HM1 R}, {HM1 T})
Where the following convention is used: The lower left and upper right coordinates of a rectangular area are given by (L,B) and (R,T)
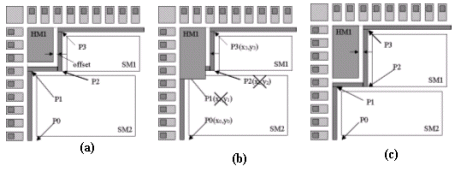
Figure 8 : Ripple effect of macro resizing on power ring
(b) Defined with absolute coordinates
(c) Defined relative to HM1
3.5 Hierarchical Paradigm
In a hierarchical physical implementation, the concurrent nature of the design process makes the refinement of the floorplan an underlying activity: data is often exchanged between the top level and the lower levels. We use one ¡§dynamic floorplan file¡¨ (.dfp) for every level of hierarchy. The dfp file is based on the language presented in the previous sections and therefore dynamic since every object¡¦s position is recomputed ¡§on the fly¡¨ as opposed to a static view. We manage the hierarchical instance names such that the same floorplan file can be executed at the block level as well as at the chip level.
The block level .dfp file essentially describes the placement of hard macros relatively to any reference chosen by the designer as illustrated in Figure 4. In many cases this is the block boundary. With only two levels of physical hierarchy, we don¡¦t have any shaping of sub-blocks within a block itself although our approach would allow it.
For the chip level, the dynamic floorplan file captures the placement of the hard macros that often don¡¦t have alternative position. As the design process continues information about relative soft macro shapes, IO order, etc solidifies. The updates of the macro positions within the changed soft blocks are automatically carried on at the top level using the associated lower level dfp files.
At any time, we benefit from the flat view of all objects relevant to the global optimization. Efficient hierarchical layout implementation cannot be achieved by simply cycling through the hierarchy using the same tools available for a flat approach. Some of the design steps for instance pin optimization, power grid creation, congestion analysis benefit substantially from a full chip based optimization in which the understanding of the macro position as well as other objects in the lower level of the hierarchy is important.
4. RESULTS
This process of dynamic floorplanning has been used in the design of both a media processing core as well as a digital video SoC. For most of the floorplanning steps described earlier in Figure 1, we used Cadence¡¦s First Encounter Tool. To implement our concept, we¡¦ve extended its Tcl Application Procedural Interface with a library of constructs, some of which presented in this paper. Cadence has since adopted a similar mechanism and has added a Graphical User Interface to facilitate the capture of relative dependencies between blocks. It is now available in SoC Encounter.
Figure 9 (before) shows the chip layout with its hierarchical boundaries and macros in each top-level block. Note that the original chip level connectivity was ¡§logically pushed¡¨ into each partition, allowing abutment of the blocks at the top level.
Given an initial topology of the top-level blocks constrained by the IO pad positions, the dynamic floorplan file was created. On one refinement iteration, the placement density (P) of blocks C, E, F and G had to be changed after analysis of the routing congestions, while blocks A, B, J and H could not be modified.
Figure 9(after) shows the result of a fully automated adjustment of the top and sub levels as well as propagation of ripple effects enabled by the replay of the dynamic floorplan . Blocks C, I, E, F and D have had their aspect ratio changed, as well as their power grid reconstructed (not shown here for clarity).
This eliminated a large number of manual steps such as changing spacing of top-level blocks, re-position macros, rebuilding power structure etc.. Even though the creation of the .dfp is a manual process and may take a few hours, the overall savings is significant as shown in Table 1.
| Manual | Dynamic | |
| Initial Setup Time | 0 | 2 hrs |
| Time per Iteration | 6 hrs | 10 mins |
| Avg. Num. Iterations | 10 | 10 |
| Total Time | 60 hrs (7.5 8 hr days) | 3.7 hrs |
Also, in this channel-less approach, the ability to maintain an up to date flat view of all macro placements while at the same time implementing each block concurrently, contributed significantly to a better optimization of the global nets and associated logical feed-troughs as well as pins on the hierarchical boundaries.
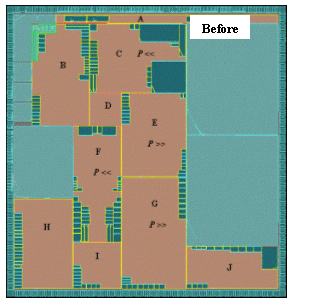
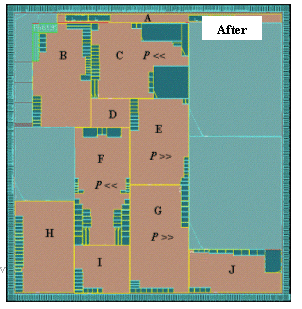
Figure 9 : Automated floorplan refinement after changes of placement density in blocks C,E,F,G
5. CONCLUSIONS
In this paper, we demonstrated a floorplan by relative position method, which enables automation of incremental floorplan refinements.
By implementing a set of operations we were able to describe a floorplan with no reference to absolute coordinates. The placement of hard macros and JTAG cells, shaping of soft block and positioning of power structure were captured to be re-playable after minor changes, avoiding expensive manual adjustments.
Results show that this new approach reduces the iteration loops in a concurrent physical design implementation. It also contributes to better global optimizations of such things as pins, routing congestion and power grids by always maintaining the consistent view of the appropriate objects across the hierarchy.
6. ACKNOWLEDGMENTS
Our thanks to DVP implementation team for helpful discussions. Thanks also to Cadence Design System for their support on the database access scheme and their belief in the proposed approach.
7. REFERENCES
[1] S-K. Dong J. Cong and C. L. Liu "Constrained floorplan design for flexible blocks" in Dig. Int. Conf. Computer-Aided Design Nov.1989 pp.488-491.
[2] Shigetoshi Natatake,¡§consistent floorplanning with hierarchical superconstraints.¡¨ IEEE Trans CAD, vol 21 No. 1,p42-49, Jan2002
[3] J. Xu, P.-N. Guo, and C.-K. Cheng, "Rectilinear block placement using sequence-pair, " IEEE Trans. on Comp. Aided Design of IC's and Systems, Vol. 18, No. 4, pp. 484-493, 1999.
[4] M. Z. Kang and W. Dai, "General floorplanning with L- shaped, T-shaped and soft blocks based on bounded slicing grid structure," Proc. ASP-DAC, pp. 265-270, 1997.
[5] Jun Cheng Chi, Mely Chen Chi, ¡§An Effective Soft Module Floorplanning Algorithm Based On Sequence pair¡¨, 15th Annual IEEE International ASIC/SOC Conference, pp.54-58,Sept. 2002.
[6] S. Posluszny, N. Aoki, D. Boerstler, P. Coulman, S. Dhong, B. Flachs, P. Hofstee, N. Kojima, O. Kwon,K Lee, D. Meltzer, K. Nowka, J. Park, J. Peter, J. Silberman, O. Takahashi, P. Villarrubia Proceedings of Design Automation Conference, June 2000 ¡§Timing Closure by Design, A High Frequency Microprocessor Design Methodology¡¨ p71.
Related Semiconductor IP
- Wi-Fi 7(be) RF Transceiver IP in TSMC 22nm
- PUF FPGA-Xilinx Premium with key wrap
- ASIL-B Ready PUF Hardware Premium with key wrap and certification support
- ASIL-B Ready PUF Hardware Base
- PUF Software Premium with key wrap and certification support
Related White Papers
- Dynamic instruction set load-in method for Java SoC
- Design Rule Checks (DRC) - A Practical View for 28nm Technology
- It's Not My Fault! How to Run a Better Fault Campaign Using Formal
- UPF Constraint coding for SoC - A Case Study
Latest White Papers
- Boosting RISC-V SoC performance for AI and ML applications
- e-GPU: An Open-Source and Configurable RISC-V Graphic Processing Unit for TinyAI Applications
- How to design secure SoCs, Part II: Key Management
- Seven Key Advantages of Implementing eFPGA with Soft IP vs. Hard IP
- Hardware vs. Software Implementation of Warp-Level Features in Vortex RISC-V GPU