Heterogeneous NPU Data Movement Tax: Intel's Own Slides Tell the Story

At Quadric, we have long argued that heterogeneous NPU designs — those that stitch together multiple specialized fixed-function engines — carry an unavoidable hidden cost: data has to move. A lot. And data movement burns power, adds latency, and creates silicon-area overhead that scales with every new generation of AI models. We have made this case in the abstract. Now, Intel has made it for us in the concrete.
A 2024 Intel Tech Tour presentation detailing their Gen 4 NPU architecture — the AI accelerator inside their latest PC chipsets — walks through exactly how a transformer graph executes on their heterogeneous design. The slides are technically thorough and clearly explained. They are also, for anyone paying attention to the data flow, a near-perfect illustration of everything we have been warning about.
The Architecture: Two Worlds Under One Roof
Intel's NPU organizes its compute fabric around two fundamentally different engine types. At the core of each Neural Compute Engine sits a MAC Array — the matrix-multiply unit optimized for the dense linear algebra that dominates transformer inference. Sitting alongside every MAC Array is a pair of SHAVE DSPs: general-purpose programmable vector processors inherited from Intel's acquisition of Movidius, included specifically to handle operations the fixed MAC arrays cannot execute.
This is the classic heterogeneous pattern. MAC arrays handle the matrix math. SHAVE DSPs serve as the escape valve for everything else. A shared Scratchpad RAM, L2 cache, MMU, and DMA engine provide the memory infrastructure connecting the two worlds. On paper, the combination covers the full operator space of modern AI models. In practice, the seams between those worlds are exactly where the inefficiency lives.

Figure 1 — Intel Gen 4 NPU block diagram from the 2024 Tech Tour. Six Neural Compute Engines, each pairing a MAC Array with SHAVE DSPs, sit beneath shared MMU, DMA, and Scratchpad RAM infrastructure.
Multi-Head Attention: The Transformer's Core Primitive
Multi-Head Attention (MHA) is the defining computational primitive of modern transformer models — the mechanism that lets LLaMA, Phi, Mistral, and virtually every serious AI model today understand relationships across context windows. Its formulation is elegant:
Attention(Q, K, V) = SoftMax(QKᵀ / √dₖ) · V
Executing MHA in practice requires a specific sequence of operations: three Linear projections to produce Query, Key, and Value vectors; a first matrix multiply (QKᵀ) to compute raw similarity scores; a SoftMax to normalize those scores into attention probabilities; a second matrix multiply to weight the Value vectors by those probabilities; a Concat across heads; and a final Linear projection. Each operation in that chain is well-understood. The question is which engine on a heterogeneous NPU runs each one — and what happens to the data in between.
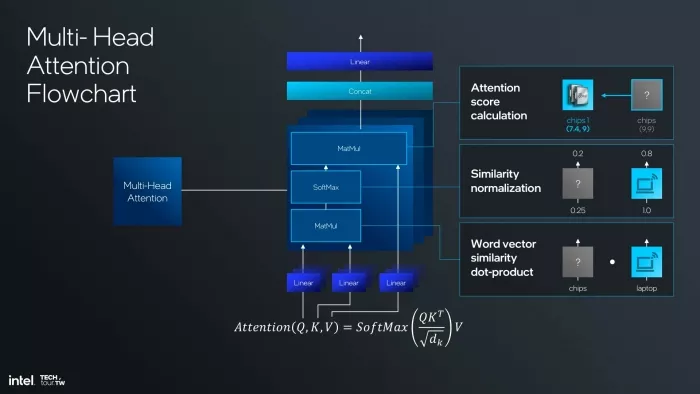
Figure 2 — Intel's MHA computation graph, showing the full operator chain: three Linear projections, two MatMuls, SoftMax, Concat, and a final Linear.
The Ping-Pong Problem: Following the Data
Intel's presentation walks through MHA execution step by step, and the data movement story it tells is revealing. Let's follow the activations.
The first MatMul — computing the dot products between Query and Key vectors to generate raw similarity scores — runs on the MAC Arrays. This is exactly what MAC arrays are built for, and they do it well. The activations are produced inside the MAC Array subsystem.
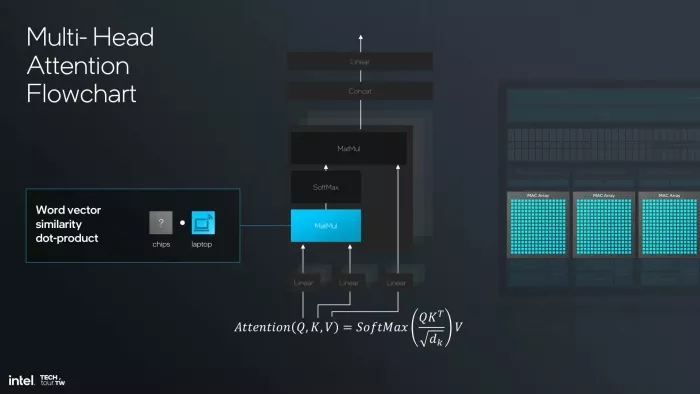
Figure 3 — Step 1: The first MatMul (word vector similarity dot-product) executes on the MAC Arrays. Intermediate activations are produced inside the MAC Array subsystem.
Then SoftMax arrives. SoftMax converts those raw similarity scores into normalized attention probabilities. It is not a matrix multiply. The MAC Arrays cannot execute it. So the intermediate activations — the full output of that first MatMul — must leave the MAC Array subsystem, transit through the shared memory hierarchy, and arrive at the SHAVE DSPs. The SHAVE DSPs execute the SoftMax.
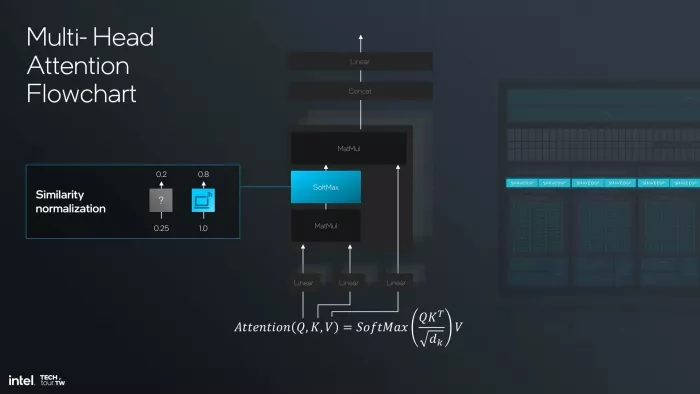
Figure 4 — Step 2: SoftMax (similarity normalization) executes on the SHAVE DSPs. Intermediate activations have crossed from the MAC Array subsystem into DSP territory via shared memory.
Now the second MatMul — multiplying the normalized attention probabilities by the Value vectors — needs to execute. That is matrix multiply again. Back to the MAC Arrays. The activations must move again: SHAVE DSP output through shared memory, back into the MAC Array subsystem.
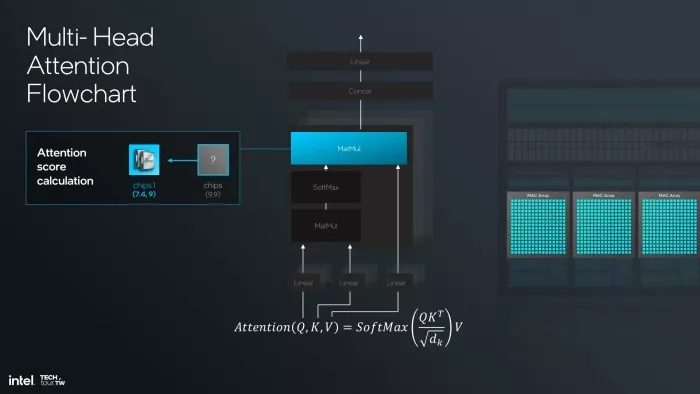
Figure 5 — Step 3: The second MatMul (attention score calculation) executes on the MAC Arrays. Activations have completed a full round-trip: MAC Arrays → SHAVE DSPs → MAC Arrays.
MAC Arrays → SHAVE DSPs → MAC Arrays. That round-trip through shared memory happens for every SoftMax in every attention layer. In a model with 32 layers and multi-head attention, that is not a rounding error — it is a structural, repeating tax on every inference.
The Compounding Costs
The data movement problem does not stop at power and latency. It creates a cascade of secondary costs that compound as models grow more complex:
-
Memory bandwidth pressure. Every activation crossing between engines must be written to and read from shared memory. The Scratchpad RAM and L2 cache visible in Intel's block diagram are working hard — not to compute useful results, but to ferry intermediate data between compute domains. Bandwidth consumed by this traffic is bandwidth unavailable for feeding the compute engines themselves.
-
DMA and control overhead. The DMA engine and Global Control unit shown in Intel's NPU diagram exist largely to manage exactly this inter-engine coordination. That is silicon area and dynamic power dedicated to traffic management rather than inference. You pay for it on every chip and burn it on every token generated.
-
Synchronization stalls. Before the second MatMul can begin, the SoftMax on the SHAVE DSPs must complete and its results must be available in the shared memory. The MAC Arrays sit idle during that window. Heterogeneous pipelines create pipeline bubbles at every engine boundary, and transformer graphs cross a lot of boundaries.
-
Fixed-function fragility. The SHAVE DSPs handle SoftMax today. But the operator space of AI models expands continuously: standard attention, grouped-query attention, sliding window attention, multi-query attention, and variants researchers have not yet published. Each new variant introduces operator patterns that may or may not map cleanly to the available engines. Heterogeneous designs are always one model evolution behind.
The Architecture That Does Not Have This Problem
Quadric's approach starts from a different premise. Rather than assembling a collection of fixed-function engines and managing the data movement between them, the Quadric Chimera GPNPU is built around a 2-D array of fully programmable ALUs that execute any operator — matrix multiply, SoftMax, layer norm, activation functions, custom operators not yet invented — without ever handing off intermediate activations to a different engine. These ALUs are intertwined with banks of MACs (multiply accumulate) engines that perform highly-efficient matrix multiplications and convolutions similar to the behavior of classic systolic arrays.
The result is what we call a unified execution model. When SoftMax follows a MatMul on a Quadric processor, the computation happens in the same programmable fabric. The data does not migrate. There is no DMA transaction. There is no synchronization stall. There is no Global Control unit scheduling a handoff between DSPs and MAC arrays. The power that would have been consumed moving data instead goes into computing the next useful result.
This matters especially as models evolve. The attention mechanisms that define AI today were not the same as those from three years ago, and they will not be the same three years from now. A fully programmable architecture adapts in software — no new silicon tape-out, no new engine to bolt on. A heterogeneous fixed-function design adapts by adding another engine, which adds another engine boundary, which adds another set of data movement round-trips.
Explore NPU IP:
- GPNPU Processor IP - 32 to 864TOPs
- Safety Enhanced GPNPU Processor IP
- GPNPU Processor IP - 4 to 28 TOPs
- GPNPU Processor IP - 1 to 7 TOPs
The Tax Is Real. The Question Is Whether to Pay It.
We appreciate the technical transparency Intel showed in this presentation. The detailed execution flow walkthrough is exactly the kind of rigorous documentation that lets the industry reason clearly about architectural tradeoffs. And what it shows, clearly, is that the heterogeneous NPU model creates a data movement tax that every heterogeneous NPU device running a modern AI model pays — on every inference, on every attention layer, in every product.
The question for SoC designers evaluating NPU IP is not whether that tax exists. Intel's own slides confirm it does. The question is whether to design it in from the start — or to choose a fully programmable architecture that eliminates the engine boundaries entirely and puts every watt of power budget to work on computation rather than transportation.
At Quadric, we know which answer we chose. And increasingly, so do the SoC teams we work with.
Source: Intel Tech Tour 2024 presentation, "Transformer Architecture on Intel's NPU / Multi-Head Attention Flowchart." All diagrams reproduced from public presentation for editorial commentary purposes.
Related Semiconductor IP
- GPNPU Processor IP - 32 to 864TOPs
- Safety Enhanced GPNPU Processor IP
- GPNPU Processor IP - 4 to 28 TOPs
- GPNPU Processor IP - 1 to 7 TOPs
- NPU
Related Blogs
- Efficiency Defines The Future Of Data Movement
- Why You Should Create Your Own NPU Benchmarks
- Can You Rely Upon your NPU Vendor to be Your Customers' Data Science Team?
- Introducing MIPS Sense data movement engines
Latest Blogs
- Area, Pipelining, Integration: A Comparison of SHA-2 and SHA-3 for embedded Systems.
- Why Your Next Smartphone Needs Micro-Cooling
- Teaching AI Agents to Speak Hardware
- SOCAMM: Modernizing Data Center Memory with LPDDR6/5X
- Bridging the Gap: Why eFPGA Integration is a Managed Reality, Not a Schedule Risk