aTENNuate: Real-Time Audio Denoising

BrainChip’s aTENNuate is a new audio denoising solution that uses a type of deep learning model called Temporal Neural Networks (TENNs) to remove background noise from speech. Unlike traditional deep learning models that often require a large amount of computing power and memory, aTENNuate is designed to be lightweight and efficient, making it ideal for devices with limited resources, like earbuds or IoT devices.
The Problem with Noise
Getting rid of background noise is a critical challenge, especially with the rise of voice-activated applications like virtual assistants. Traditional methods for denoising, such as Wiener filtering, rely on assumptions about the type of noise, so their performance suffers in environments where the noise changes. More recent deep learning approaches have improved denoising quality, but they often come with a high cost in terms of memory and computational complexity. Many of these models use a process that transforms the audio into a visual representation called a spectrogram, which can be computationally expensive and lead to redundant calculations.
For example, models that use convolutional neural networks (CNNs) need to be very deep to capture long-term patterns in audio, which increases their size. Similarly, transformer models, which are great at understanding long-range context, also require a lot of computing power and a large number of parameters, making them impractical for small, low-power devices.
How aTENNuate Works
aTENNuate is a deep state-space autoencoder that works directly with raw audio waveforms, which eliminates the need for spectrogram generation and helps preserve fine-grained audio details. This end-to-end approach simplifies the denoising process and makes it easier to deploy the model. The model is built on BrainChip’s proprietary TENNs, which are an efficient alternative to conventional CNN and recurrent neural network (RNN) architectures.
The Power of Temporal Neural Networks (TENNs)
TENNs are a type of state-space model that can efficiently capture long-range patterns in audio signals using linear recurrent units. This allows them to encode global speech patterns and noise profiles with a small number of parameters and reduced computational needs compared to other models.
A key advantage of TENNs is their ability to operate in two distinct modes:
- Training Mode: During training, TENNs use a convolutional mode that allows them to leverage the power of parallel processing on GPUs, making the training process faster.
- Inference Mode: For real-time use, TENNs switch to a recurrent mode. In this mode, the model maintains an internal “state,” so it doesn’t have to repeatedly process overlapping windows of audio. This eliminates redundant computations and allows for real-time, low-latency processing on edge devices.

Ritik Shrivastava of BrainChip presents our Audio Denoising application at the Interspeech 2025 Conference in Rotterdam, The Netherlands.
Model Design and Performance
The aTENNuate model has an encoder-decoder structure. The encoder compresses the noisy raw audio into a more compact feature representation, and the decoder then reconstructs a clean, denoised waveform from those features.
To train the model, a diverse dataset was created by mixing clean speech with various types of noise at different signal-to-noise ratios (SNRs). The model was trained using a special “composite loss” function that combines a basic loss function with a spectral loss to ensure both stability and high perceptual quality.
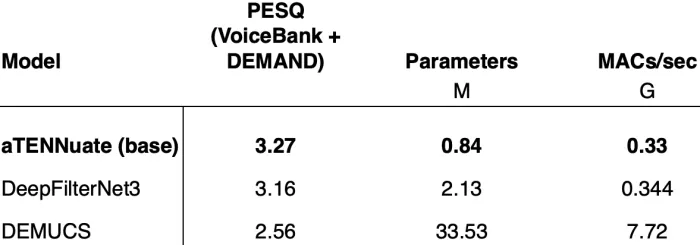
In benchmark tests, aTENNuate outperformed popular real-time denoising models like DeepFilterNet3 and RNNoise on key metrics like the Perceptual Evaluation of Speech Quality (PESQ) score. The base aTENNuate model achieved a PESQ score of 3.27 on the VoiceBank + DEMAND test set and 2.98 on the DNS1 test set. This was accomplished with fewer than one million parameters and only 0.33 GMAC/s, demonstrating its superior efficiency.
Real-World Applications
By processing raw audio directly with an efficient architecture, aTENNuate streamlines the denoising pipeline and makes deployment on resource constrained devices more practical. It delivers the same level of audio enhancement as larger systems while requiring only a fraction of the compute and memory. This efficiency enables real-time performance on wearables, IoT devices, and other edge hardware. On BrainChip’s Akida processor, aTENNuate provides efficient and low-latency denoising, marking a significant step forward for audio enhancement at the edge. Its ability to maintain high quality even with down-sampled or quantized inputs further demonstrates its robustness in real-world scenarios.
To explore the research in depth, please read the paper here: aTENNuate: Optimized Real-time Speech Enhancement with Deep SSMs on Raw Audio
Author
Ritik Shrivastava is a Solutions Architect at BrainChip, where he develops machine learning algorithms and solutions for speech, audio, large language models (LLMs), and sequential data. He holds a Master’s degree in Electrical Engineering from the University of Washington, Seattle, and a Bachelor’s degree in Engineering from the Institute of Engineering and Technology, DAVV Indore, India. Prior to BrainChip, Ritik worked in data science and engineering positions, gaining experience in applied machine learning and model optimization.
Related Semiconductor IP
Related Blogs
- ARM furthers its "cover the earth" strategy with introduction of R5 and R7 core variants for fast, real-time, deterministic SoC applications
- Oxford Digital Offers Small Audio DSP Core With Graphical Programming
- CEVA's TeakLite-4: Audio Once Again Comes to the Fore
- Android Audio Offload Explained at Mobile World Congress
Latest Blogs
- Physical AI at the Edge: A New Chapter in Device Intelligence
- Rivian’s autonomy breakthrough built with Arm: the compute foundation for the rise of physical AI
- AV1 Image File Format Specification Gets an Upgrade with AVIF v1.2.0
- Industry’s First End-to-End eUSB2V2 Demo for Edge AI and AI PCs at CES
- Integrating Post-Quantum Cryptography (PQC) on Arty-Z7