Leveraging ASIC AI Chips for Homomorphic Encryption
By Jianming Tong (Georgia Institute of Technology), Tianhao Huang (Massachusetts Institute of Technology), Leo de Castro (Massachusetts Institute of Technology), Anirudh Itagi (Georgia Institute of Technology), Jingtian Dang (Georgia Institute of Technology), Anupam Golder (Georgia Institute of Technology), Asra Ali (Google), Jevin Jiang (Google), Arvind (Massachusetts Institute of Technology), G. Edward Suh (Cornell University/NVIDIA), Tushar Krishna (Georgia Institute of Technology)
Abstract
Cloud-based services are making the outsourcing of sensitive client data increasingly common. Although homomorphic encryption (HE) offers strong privacy guarantee, it requires substantially more resources than computing on plaintext, often leading to unacceptably large latencies in getting the results. HE accelerators have emerged to mitigate this latency issue, but with the high cost of ASICs. In this paper we show that HE primitives can be converted to AI operators and accelerated on existing ASIC AI accelerators, like TPUs, which are already widely deployed in the cloud. Adapting such accelerators for HE requires (1) supporting modular multiplication, (2) high-precision arithmetic in software, and (3) efficient mapping on matrix engines. We introduce the CROSS compiler (1) to adopt Barrett reduction to provide modular reduction support using multiplier and adder, (2) Basis Aligned Transformation (BAT) to convert high-precision multiplication as low-precision matrix-vector multiplication, (3) Matrix Aligned Transformation (MAT) to covert vectorized modular operation with reduction into matrix multiplication that can be efficiently processed on 2D spatial matrix engine. Our evaluation of CROSS on a Google TPUv4 demonstrates significant performance improvements, with up to 161x and 5x speedup compared to the previous work on many-core CPUs and V100. The kernel-level codes are open-sourced at https://github.com/google/jaxite.git.
1. Introduction
Artificial intelligence (AI) is rapidly evolving and often exceeds human capabilities in diverse applications. Examples include large language models that excel in complex reasoning and diffusion models that generate creative contents [8, 44, 47, 64]. In order to utilize sensitive or private data for AI, we need strong confidentiality protection for the AI serving life-cycle even in untrusted environments. Homomorphic Encryption (HE) promises strong end-to-end confidentiality by enabling data processing in an encrypted form, as shown in Fig. 1. However, HE inflates data sizes by 200× and computation by 10,000×, resulting in a 1000× slowdown on a multi-core CPU.

Figure 1. HE enables direct computation on encrypted data to enable privacy-preserving model serving
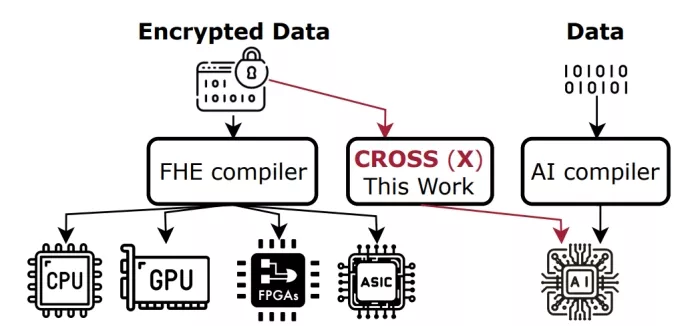
While HE’s inherent parallelism seems tailor-made for dedicated ASICs, the cost of designing, verifying, and maintaining such an ASIC is daunting, often requiring years and millions of dollars. HE implementations on CPUs, GPUs, and FPGAs have made significant strides recently but still fall short of ASICs’ performance by at least 20× . To reduce this performance gap without fabricating a custom ASIC only for HE, this paper studies opportunities and challenges in accelerating HE using existing ASICs for Artificial Intelligence (AI), which are already pervasive in the cloud. We propose a compilation framework, CROSS1 , to enable HE deployment on AI accelerators.
The following characteristics of AI accelerators make accelerating HE feasible: (1) mix of vector processing unit and matrix multiplication unit that combine to provide a high throughput via a massive number of arithmetic units (≥ 105 MACs), (2) large amounts of programmable on-chip memory (≥ 100 MB), and (3) on-chip transpose/shuffling unit to enable parallel irregular memory access.
However, functionally, an AI accelerator lacks two features that enable ASIC HE accelerators use to run HE workloads: (1) support for modular arithmetic and (2) high-precision arithmetic (most AI inference accelerators only support 8- bit integer operations). To bridge these gaps, we implement Barrett reduction [12] to facilitate modular operations using existing multiplication, addition, and shift capabilities of AI accelerators. To further enable high precision, we propose chunk decomposition to decompose high-precision data into many low-precision chunks and convert the original high-precision operation into low-precision chunkwise multiplication and reduction.
Despite enabling functional correctness of HE processing in AI accelerators, several challenges hinder optimal performance: (1) decomposing a high-precision modular operation into many low-precision chunkwise operations introduces extra on-chip data movement, reducing performance for memory-bounded HE operations, (2) the rigid-shape 2D systolic array in AI accelerators only favors large-scale matrix multiplications, resulting in low computation resource utilization when processing vectorized HE operations including Number Theoretic Transform (NTT) and BasisChange.
To further gain performance, we propose two mapping optimizations in our compiler, CROSS. (1) Basis Aligned Transformation (BAT) schedules chunkwise multiplications as dense matrix multiplications. By aligning the additional on-chip data movements with the native datapath of AI accelerators, BAT maximizes data reuse and computational efficiency. (2) Matrix Aligned Transformation (MAT) reformats both the computation and data layouts of vectorized operations from NTT and basis change into matrix forms. These matrix representations are then transformed into larger low-precision matrix multiplications through BAT. Leveraging the synergy between BAT and MAT, CROSS enhances overall compute utilization of both vector processing units and matrix multiplication units in AI accelerators while reducing memory accesses and on-chip memory storage requirements. To the best of our knowledge, CROSS represents the first work to investigate deployment of HE workloads on AI accelerators, introducing a new paradigm of AI/HE co-acceleration on the same hardware substrate (see Fig. 2). CROSS shows that AI accelerators without any additional hardware support can indeed be used to accelerate HE workloads that require no bootstrapping.
Our evaluation of HE implementation on Google TPUv4 shows that we can achieve as much as a 12× speedup over Lattigo [48] on a CPU, 5× speedup over a previous GPU implementation (100× [35]) on an NVIDIA V100, and 1.05× speedup over an FPGA implementation (Xilinx U280 [3]). While still approximately 50× slower than a well-designed HE ASIC, the lack of commercial HE chips and the widespread availability of TPU-like AI accelerators make our approach highly compelling. The primary performance gap with HE ASICs stems from the absence of dedicated modular reduction units in TPUs. Adding such units can bring an additional 1.34× speedup, as discussed in §6.4.
This result suggests that HE acceleration on ASIC AI accelerators is a promising direction to investigate. ASIC AI accelerators can provide significantly higher HE performance compared to CPUs and be competitive to other programmable accelerators such as GPUs and FPGAs. We note that the current experimental results do not include bootstrapping, which may be required for large applications, and the HE performance on GPUs and FPGAs can also be improved with optimizations. For example, a more recent study (Cheddar [38]) on GPU-based HE acceleration reports higher HE performance on an NVIDIA A100. In that sense, fully understanding the potential of AI accelerators for complex HE applications with bootstrapping and the detailed comparisons across different programmable accelerators will need further studies.
We make the following contributions in this paper:
- A systematic characterization of HE operators consisting of (1) computation analysis and latency profiling of various HE operators, identifying NTT/INTT, Basis Change, and element-wise multiplication as the key performance bottlenecks. These operators account for 74.5% ∼ 92.3% of the overall latency under Brakerski/Fan-Vercauteren (BFV) and Cheon, Kim, Kim and Song (CKKS); (2) a programmer’s view of available functionalities inside ASIC AI accelerators. (3) the gap between workloads and hardware.
- A novel compilation framework, CROSS, to systematically lower HE kernels into hardware primitives on off-theshelf AI accelerators without any hardware modifications. At its core, CROSS introduces BAT, a foundational set of arithmetic transformations that map high-precision scalar modular operations to low-precision hardware. Using BAT, CROSS achieves highly efficient vectorized modular operations (VecModOp) and modular matrix multiplication (ModMatMul), which are critical for most HE kernels. For complex HE kernels like NTT, CROSS further proposes MAT to reformulate interleaved VecModOps with cross-coefficient reduction as ModMatMul, ensuring efficient execution.
- We conducted a comprehensive evaluation of the HE operators on TPUv4 across various practical security parameters. Our TPUv4 implementation achieved up to a 12× speedup over a SotA CPU implementation (Lattigo [48]) on an Intel i5-6600k, a 5× speedup over a GPU implementation on an NVIDIA V100 (100x [35]), a 50% slowdown over a GPU implementation on an NVIDIA A100 (Cheddar [38]), and a 1.05× speedup over a SotA FPGA implementation (FAB [3]) on Xilinx Alevo U280. We note that A100s use a new technology node and have higher power consumption compared to TPUv4. These results demonstrate that AI accelerators like TPUv4 can perform HE operations competitively with SotA GPU and FPGA implementations, indicating a promising direction for further exploration, including computationally intensive tasks like bootstrapping.
To read the full article, click here
Related Semiconductor IP
- NPU IP Core for Mobile
- NPU IP Core for Edge
- Specialized Video Processing NPU IP
- HYPERBUS™ Memory Controller
- AV1 Video Encoder IP
Related White Papers
- Leveraging RISC-V as a Unified, Heterogeneous Platform for Next-Gen AI Chips
- Why Interlaken is a great choice for architecting chip to chip communications in AI chips
- Integrating Ethernet, PCIe, And UCIe For Enhanced Bandwidth And Scalability For AI/HPC Chips
- ASIC technology is morphing as demand for custom chips remains solid despite rising mask costs and slow growth in many end markets.
Latest White Papers
- Ramping Up Open-Source RISC-V Cores: Assessing the Energy Efficiency of Superscalar, Out-of-Order Execution
- Transition Fixes in 3nm Multi-Voltage SoC Design
- CXL Topology-Aware and Expander-Driven Prefetching: Unlocking SSD Performance
- Breaking the Memory Bandwidth Boundary. GDDR7 IP Design Challenges & Solutions
- Automating NoC Design to Tackle Rising SoC Complexity