How High-Level Synthesis Can Raise the Efficiency of Design Reuse
Abstract
Design reuse and IP-based design are established design practices enabling fast integration of large-scale, high-complexity systems. But while silicon potential keeps improving through node shrinks, designs meant for reuse cannot leverage these technological advances due to their rigidly defined micro-architecture. In this paper we present a design methodology based on high-level synthesis that allows retargeting functional IPs in the form of C++ programs to technology optimized RTL implementations. We will expose results that show that this approach can eliminate the usual compromise of design quality versus design time imposed by design reuse strategies, yielding optimal implementations in very short time.
1. Introduction
As design complexity increases, design reuse has become a mandatory approach to keep new design work to humanly addressable sizes. To reach mainstream adoption, a lot of research and industry efforts were needed to address the major obstacles on the path of an efficient and workable reuse methodology. However, several concerns still exist with existing reuse approaches[1]: 1/ building designed-for-reuse components is difficult, 2/ available reusable components may not deliver the required performance, 3/ reusable components may be substantially bigger than a component that was tailored to the design’s specific technology.
By definition, the RTL (Register Transfer Level) source is register accurate and models the needed “clouds of logic” within these register bounds. The design data paths are crafted based on the desired clock frequency and target technology. If the new technology is faster, it may be possible to reduce area by choosing architectures for functional units that are less aggressively optimized for performance. Retargeting to a slower technology (for instance for prototyping an ASIC design on an FPGA) is often hard since the fastest available architectures may have already been selected for all functional units that are in the critical path. In either case, the improvement in either area or performance is considerably limited.
Current IP descriptions are hard-coded micro-architectures resulting from a set of three very distinct design constraints. 1/ Behavioral constraints define what should be performed by the IP. 2/ Architectural constraints define how the IP should behave with regards to other blocks in a system. 3/ Technology constraints define what can be accomplished technologywise and what resources are available to do so.
Unarguably, RTL descriptions are a mandatory format for electronic design automation flows. But a significant drawback is the lack of a clear separation between the behavioral, architectural and technology constraining factors in the final representation. Should one of these design factors change and the IP description becomes suboptimal at best and unusable at worse. Once implementation decisions are committed in the form of an RTL model, there is no turning back. Important decisions such as leveraging high-speed multipliers in FPGAs or affording a dual-port memory on ASIC cannot be modified. Conceptually, extensive parameterization of the model with carefully written documentation could ease the IP modification process, but in practice, this becomes a complicated task denying all the benefits of a reuse methodology.
The proposed methodology recognizes the independent nature of behavior, architecture and technology as design constraints by enforcing a clean separation between the three. We leverage high-level synthesis techniques [2][3] to interactively explore implementation scenarios based on functional and technology requirements. The scenarios are then matched against the architectural goals such as performance, area or power.
The flow effectively has three inputs – one for each type of constraint – and through a synthesis process, produces a technology optimized IP description at the RT-Level (Figure 1). The architectural and technology constraints are toolspecific synthesis directives. The functional input is in ANSI C++ [4], as it would be written by an algorithm designer, i.e., with no details of timing or concurrency, and does not rely proprietary language extensions. The input specification is fast to simulate and requires only a C++ compiler. This synthesis methodology delivers results comparable to hand-coded RTL but with a considerable shorter design time.
There are many advantages to using pure ANSI C++ as an input language:
- Unlike VHDL, Verilog or SystemC, ANSI C++ doesn’t incorporate timing information. The source is purely functional and can be retargeted with the proposed flow to any implementation.
- ANSI C++ is a very popular language and is widely used for algorithm development. Pure C++ with no extensions will most likely be familiar to most engineers involved in the design process.
- Natively compiled on the workstations, C++ programs do not require simulation kernels and execute very fast, enabling significant amount of testing on the algorithm in fractions of the time it would take with event-driven languages.
- The object-oriented nature of C++, with classes, templates and polymorphism makes it an ideal language for extensive model parameterization and easy reuse.
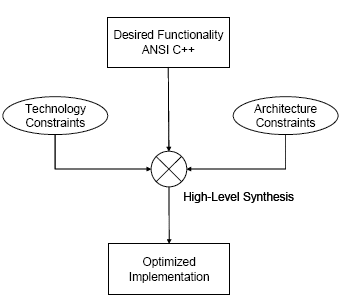
Figure 1
RTL implementations are produced from the pure ANSI C++ specification based on architectural requirements (performance/area/power) and target technology (ASIC/FPGA/clock frequency). Design decisions are made by the designer, but implemented by the synthesis tool. Interactive feedback provided by synthesis enables the designer to further explore and refine the architecture of the design.
2. High-Level Synthesis
In this section, we will discuss how high-level synthesis helps transitioning from a purely functional C++ description to a technology and architecture specific RTL implementation. At the centre of this transformation, synthesis directives provide a mechanism to specify high level decisions on how the design communicates with the outside world, how data is stored and how parallelism is exploited to obtain the desired performance.
Functional C++ specification
The coding style used for functional specification is plain C++ that provides a sequential implementation of the behaviour without any notion of timing or concurrency. Both the syntax and the semantics of the C++ language are fully preserved. This section provides a brief overview of how the behaviour and the hardware interface is specified as well as style issues that need to be taken into account to maximize the benefits of the proposed design reuse strategy. A more detailed description of this coding style can be found in [5]. Compound data types such as classes, structs and arrays are also supported for synthesis. Furthermore, parameterization through C++ templates is also supported. As shown in [8] this combination of classes and templates provides a powerful mechanism facilitating design re-use. Once developed, templatized objects can be specialized to different bit-widths and sizes. This is a fundamental feature to provide functional flexibility in our high-level reuse flow.
Interface Synthesis
Interface synthesis converts the way the C function communicates with the outside world. There are a number of architectural transformations that take place:
- An optional start/done handshake protocol is added to the design
- The individual function arguments are mapped to a variety of resources such as memories, buses, FIFOs, handshake registers etc.
- The data transfer bit width for any of the arguments is specified
- Arrays accesses over an index may be converted in accesses over time, effectively reading or writing a stream of data
Loop Transformations
Loop pipelining provides a way to increase the throughput of a loop (or decreasing its overall latency) by initiating the (i+1)th iteration of the loop before the ith iteration has completed. Overlapping the execution of subsequent iterations of a loop exploits parallelism across loop iterations. The number of cycles between iterations of the loop is called the initiation interval. In many cases loop pipelining may improve the resource utilization thus increasing the performance/ area metric of the design.
Loop unrolling exposes parallelism that exists across different subsequent iterations of a loop by partially or fully unrolling the loop. In some cases, partial unrolling may also be used in a coordinated way with memory mapping and interface synthesis to increase the effective bandwidth for data transfer. For example, unrolling may expose the possibility of accessing of even and odd elements of an array as one word when it is mapped to memory.
Scheduling and Allocation
Scheduling and allocation is the synthesis engine that optimizes the designs with the given clock period directive, cycle and resource constraints that are either explicitly provided by the user or implied by interface synthesis directives, variable/array mapping directives and loop pipelining/unrolling directives. Scheduling/allocation have the ability to select among combinational, sequential and pipelined components that implement the operations in the algorithm. The above transformations allow writing the C++ specification in a way that does not need to embed features of the desired architecture in the source.
3. Case Study
In this section we present results achieved with the proposed reuse methodology for a video processing unit. The high-level synthesis tool used for the purpose of this study is Catapult C Synthesis [9]. The quality of results achieved with this tool [10] is a mandatory requirement in the event of deploying the proposed approach in a production environment. In this research we are looking at reusing an IP within changing technology, interfaces and micro-architectural specifications. The aim of this research is to highlight how the proposed “functional reuse” methodology allows adapting to such changing requirements.
Horizontal Scaling
Horizontal scaling is required for DVB-T/h.264 streams to restore pixel squareness, so that viewer sees round circles and square squares. In the H.264 standard document, a range of allowed pixel aspect ratios is defined. For instance, if source picture had a pixel aspect ratio of 16:11 and display pixels are square, 11/16 horizontal scaling will restore pixel squareness and allow undistorted representation, as shown in the figure below. The target display may have non-rectangular pixels, in which case the required scaling is obtained as a multiplication of the two aspect ratios.
Algorithm
A set of the required scaling coefficients ranges from 3/4 (slight downscaling) to 8/3 (substantial upscaling). The approach taken is based on the Lagrangian polynomials and does not use tables to store the coefficients. The resulting circuit is bigger but has much greater flexibility in choosing unrelated scaling ratios. To cover all the required ratios, cubic interpolation algorithm was choosen. To reconstruct intermediate pixels, a cubic curve is fitted on a sliding widow of four neghboring pixels. A row of N pixels is converted to M pixels, where s = M/N is a scaling coefficient.
Architecture
The scaling block has two parts: coefficients calculation and loop control. Coefficients calculation is straight forward, the loop control is little bit more complex. In order to support both upsampling and downsampling, the loop is always iterated M times, where M is a number of output pixels. At each iteration, a new input sample is read if running remainder reached (or exceeded) 1 at the previous iteration. If running remainder is below 1 at the beginning of the iteration, an output pixel is generated and the remainder is incremented. Thus, the algorithm is able to skip both approximation coefficients calculation and output sample generation. The former is required for upscaling, when the same set of approximation coefficients may generate more then one output pixel, the later is required for downscaling, when output grid step is bigger then 1 and certain iterations may generate no output pixels.
The C++ Code
The section below shows significant portions of the C++ model of the horizontal scaler. For bit-accurate modelling we use the Algorithm C Datatypes library [6][7] which provides both arbitrary-length integer and fixed-point datatypes. This simple example gives a good overview of the flexibility offered by C++, through the use of classes, pointers, pointer arithmetic, loops, conditional statements, etc...

Listing 1
4. Reusing functional IP on different technologies
Where RTL intimately combines functionality, technology and architecture, our flow proposes a clean separation between these three notions. Here we have varied the technology criteria and kept invariant the two others to investigate the sensitivity of an IP to the target technology and to evaluate the ease of porting a functional IP to a new process with the proposed methodology
We synthesized the same functional IP on 6 ASIC technologies: 180nm, 150nm, 130nm, 110nm, 90nm and 65nm. Figure 2 plots the area of each solution. The smaller the geometry, the faster the operators; in consequence overall results are improved. This confirms how sensitive to the target process node a design is.
Similarly, starting from the same source code, we synthesized the functional IP to 4 different FPGAs, 2 low-power and 2 high-performance devices. Figure 3 plots the pipeline depth for each implementation of the horizontal scaler. The impact of the selected FPGA technology is very visible. For a given frequency, faster FPGAs can accommodate more combinatorial logic. Therefore the pipeline depth can be significantly reduced if the capabilities of the target devices are properly exploited, as with the proposed high-level synthesis flow.
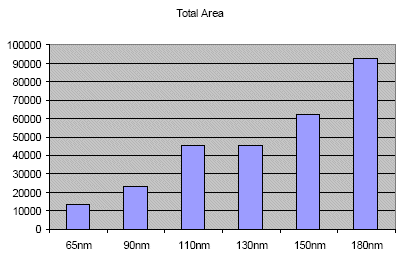
Figure 2
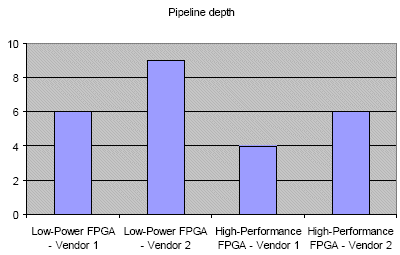
Figure 3
Within a given functionality/architecture pair, there is clearly no “one-size-fits-all”. The core architecture, including the pipeline depth and associated control is fundamentally technology dependant. Reusing a given RTL core from one process to the next or from one FPGA family to another is a suboptimal approach. In comparison, the proposed flow allows optimizing the IP based on the target technology, without manual intervention.
5. Reusing functional IP with different interface requirements
RTL and lower-level representations of IP hardcode interface behaviour in the source. In the context of reuse, this is not desirable as interface constraints are often dictated by the system in which the IP is integrated. This part of the study demonstrates the flexibility offered by the proposed flow to create IP variants with different interfaces.
The design interface is defined by the prototype of the synthesized function and a set of synthesis directives. The source code defines which are the ports, their direction and the maximum quantity of data which can transit through them. Synthesis contraints are then used to define the bandwidth of the port, its protocol as well as clock, reset and enable properties.
Since iInLen, iOutLen and fRatio are scalars passed by value, they will be necessarily inputs to the design. The port direction of anInArray and anOutArray is defined by the C++ code. anInArray is an input as the array is only read and anOutArray is an output as it is only written to. The C++ code also defines that a maximum of 20480 bits (MAX_ROW_SIZE x PixelType) are expected to transit through each of those ports, but no assumption is made about the bandwith, protocol or data rate.
Synthesis constraints can easily be applied in the form of Tcl directives or GUI operations to synthesize various types of interfaces. For instance we could expect the design to read pixel from memory, or alternatively, to receive them as streaming data with optional handshake. Interface Synthesis allows building such interfaces, without modifying the source and only by modifying the constraints, making IP retargeting extremely easy and efficient. Listing 2 shows three sets of constraints used to build different design interfaces.

Listing 2
With the proposed methodology, new interfaces can be instantly synthesized, substituting length and error-prone manual creation of interface adapters.
6. Reusing functional IP with different architectural requirements
The third focus of the study is to analyze the control offered by the proposed flow over the actual micro-architectural implementation of the IP through design-space exploration capabilities.
The C++ source description only gives a functional specification. In parallel to the functional criteria, designers typically have micro-architectural requirement regarding parallelism, data rates, resource sharing or even power consumption. In the proposed methodology, the requirements can be captured through synthesis constraints to build architecturally different yet functionally equivalent IP implementations. Here, we investigated how designs with different data rates could be built and we measured the impact of the data rate on area.
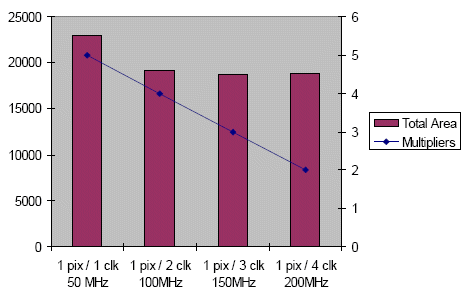
Figure 4
The interpolation part of the design requires 5 multiplications to compute a result. A continuously running design, reading inputs and producing output every cycle (pipeline initiation interval of 1) at 50MHz would therefore need 5 multipliers. An implementation accessing I/Os every two cycles at 100MHz would have two cycles to perform 5 multiplications, which indicates a theoretical minimum of 3 multipliers for this version. We also built solutions with data rates of 1 access every 3 and 4 cycles at 150 and 200MHz.
Figure 4 compares the results obtained for the 4 variants on a 90nm ASIC technology. Total area is plotted on the left hand axis and the total number multipliers is shown on the right axis. The number of multipliers matches the theoretical expectation. Fewer operators are used, and the high-level synthesis flow is able to time-share expensive resources. Area for the fully pipelined implementation is bigger than the other solutions. While the amount of functional logic is reduced in the solutions with more sharing, the impact of a higher clock frequency forces more pipeline stages and introduces more registers. As a result, the other solutions have rather comparable area.
The proposed flow allows sweeping the design-space in a various intuitive fashion, letting designers explore various candidate architectures and choose the best candidate for specific requirements. In contrast, manual modifications to IPs are obviously possible, but defeat the purpose the reuse and negate its core essence. Clearly, high-level synthesis allows separating functionality from technology and architectural aspects, elevating the abstraction of reuse.
7. Conclusion
A novel functional reuse flow based on C++ modelling techniques coupled with high-level synthesis technology was presented. When time pressure and cost issues don't permit the optimization of legacy designs in a reuse flow, design optimization is traded against schedule. The proposed flow promotes reuse at the functional level as opposed to the RTlevel and builds on the clean separation of behaviour, architecture and technology. Results clearly demonstrate that functional specifications in C++ can be synthesized to fundamentally different technology-optimized RTL architectures providing a fast and efficient reuse methodology.
8. References
[1] Margarida F. Jacome and Helvio P. Peixoto. A Survey of Digital Design Reuse. IEEE Design & Test of Computers. Volume: 18, Issue 3. May-June 2001. Pages: 98-107.
[2] John P. Elliott. Understanding Behavioral Synthesis: A Practical Guide to High-Level Design. Kluwer Academic Publishers, 1999.
[3] R. Walker and R. Camposano. A Survey of High-Level Synthesis Systems. Kluwer Academic Pub- lishers, Boston, MA, 1991.
[4] Bjarne Stroustrup. The C++ Programming Language. 3rd edition. Addison-Wesley
[5] Andres Takach, Peter Gutberlet and Simon Waters. Proceeding of the Formal Design Languages Conference. September 2001.
[6] Andres Takach, Simon Waters and Peter Gutberlet. “Fast bit-accurate C++ datatypes for functional system verification and synthesis”, FDL’2004.
[7] AC Datatypes, www.mentor.com/products/c-based_design/news/ac_datatypes.cfm
[8] Sergio R. Ramirez, Object Oriented Programming for Digital Design, DVCon'2006
[9] Catapult C Synthesis, Mentor Graphics, www.mentor.com/c-design/catatpult.html
[10] Fabrice Baray, Henri Michel, Pascal Urard and Andres Takach. "C Synthesis Methodology for Implementing DSP Algorithms", GSPx 2004
Related Semiconductor IP
- UFS 5.0 Host Controller IP
- PDM Receiver/PDM-to-PCM Converter
- Voltage and Temperature Sensor with integrated ADC - GlobalFoundries® 22FDX®
- 8MHz / 40MHz Pierce Oscillator - X-FAB XT018-0.18µm
- UCIe RX Interface
Related Articles
- High-level synthesis, verification and language
- High-Level Synthesis - Ready for prime-time?
- The future is High-Level Synthesis
- Building a NAND flash controller with high-level synthesis
Latest Articles
- Enabling RISC-V Vector Code Generation in MLIR through Custom xDSL Lowerings
- A Scalable Open-Source QEC System with Sub-Microsecond Decoding-Feedback Latency
- SNAP-V: A RISC-V SoC with Configurable Neuromorphic Acceleration for Small-Scale Spiking Neural Networks
- An FPGA Implementation of Displacement Vector Search for Intra Pattern Copy in JPEG XS
- A Persistent-State Dataflow Accelerator for Memory-Bound Linear Attention Decode on FPGA