RaiderChip NPU leads edge LLM benchmarks against GPUs and CPUs in academic research paper
The startup’s NPU surpasses NVIDIA’s Jetson Orin, the company’s flagship edge platform, in both raw performance and energy efficiency.
Spain, December 12, 2025 -- The University of Cantabria has recently published an independent research paper analyzing the performance and efficiency of different hardware architectures executing generative AI models at the edge.
The study, aimed at comparing the real-world behavior of each platform under intensive inference workloads, evaluates CPUs, GPUs, and NPUs from vendors including Intel, NVIDIA, ARM, and RaiderChip, processing a representative set of Small Language Models such as Meta Llama, Alibaba Qwen, and DeepSeek R1.
To maintain equivalent experimental conditions, the researchers executed the selected models under identical settings and chose platforms with comparable memory bandwidth. Under this controlled framework, the paper focuses on three key metrics: raw performance (tokens/second), energy efficiency (tokens/joule), and Energy–Delay Product (EDP).
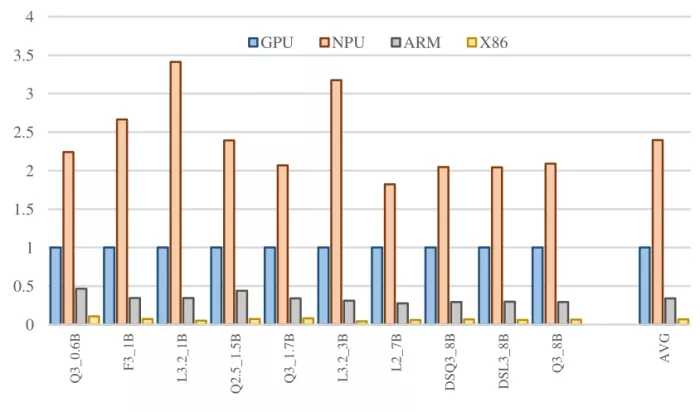
Energy-Performance results (EDP-1, higher is better)
RaiderChip NPU (orange) vs Nvidia GPU (blue)
The results show a clear and consistent advantage for RaiderChip’s NPU over the other platforms analyzed. In non-quantized (FP16) models, the NPU delivers up to 93% more performance and 30% higher energy efficiency than NVIDIA’s GPU, which ranks second. In quantized (Q4) models, the gap widens even further, reaching up to 110% higher performance and 63% higher energy efficiency. When considering EDP, the most comprehensive metric for evaluating inference hardware by combining speed and energy consumption, the difference becomes even more striking, climbing to 140% improvement in quantized (Q4) models. Neither Intel’s x86 CPUs nor the evaluated ARM cores come close to these results, positioning RaiderChip as the most competitive architecture in the study.
The research’s results highlight RaiderChip’s ability to maximize performance per Watt and per memory cycle, meaning it can generate more tokens per unit of energy while extracting more useful work from each memory access. Economically, this translates into lower energy consumption, less hardware required to deliver a given level of capability, and therefore significantly lower operational costs in generative AI deployments.
All of this becomes even more relevant when we acknowledge that the future of AI is inseparably tied to its energy consumption. As these technologies scale and begin to operate autonomously, globally, and continuously across distributed environments, energy will become the next major strategic challenge.
The next generation of artificial intelligence will undoubtedly be driven by more advanced models—but unlocking their full potential will depend on architectures that, like RaiderChip’s NPU, extract maximum value from every Watt, turning it into more intelligence, more autonomy, and greater execution speed.
In short, efficiency will define the pace of progress and determine who leads the new era of Artificial Intelligence.
Related Semiconductor IP
- Embedded AI accelerator IP
- NPU
- Specialized Video Processing NPU IP for SR, NR, Demosaic, AI ISP, Object Detection, Semantic Segmentation
- NPU IP Core for Mobile
- NPU IP Core for Edge
Related News
- RaiderChip Hardware NPU adds Falcon-3 LLM to its supported AI models
- RaiderChip NPU for LLM at the Edge supports DeepSeek-R1 reasoning models
- RaiderChip launches its Generative AI hardware accelerator for LLM models on low-cost FPGAs
- RaiderChip brings Meta Llama 3.2 LLM HW acceleration to low cost FPGAs
Latest News
- EU DARE Project Is Scrambling to Replace Codasip
- Sofics and Alcyon Photonics Partner to Support Next-Generation Photonic Systems
- QuickLogic Appoints Quantum Leap Solutions as Authorized Sales Representative
- Cadence and NVIDIA Expand Partnership to Reinvent Engineering for the Age of AI and Accelerated Computing
- Cadence and Google Collaborate to Scale AI-Driven Chip Design with ChipStack AI Super Agent on Google Cloud