NPU accelerator IP
Filter
Compare
26
IP
from
9
vendors
(1
-
10)
-
RISC-V-Based, Open Source AI Accelerator for the Edge
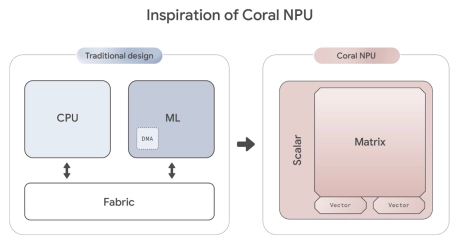
- Coral NPU is a machine learning (ML) accelerator core designed for energy-efficient AI at the edge.
- Based on the open hardware RISC-V ISA, it is available as validated open source IP, for commercial silicon integration.
-
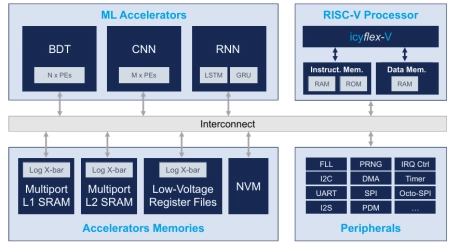
AI/ML Accelerator
- General purpose RISC-V core (RV32IMC)
- Standard communication peripherals: UART, I2C, SPI (x2), Octo-SPI, DCMI, I2S
- JTAG debugging interface
- Up to 4 MB of on-chip SRAM + 0.5MB of MRAM
- Multi neural network execution
-
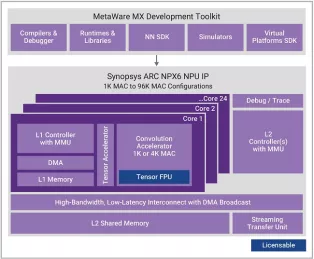
Optional extension of NPX6 NPU tensor operations to include floating-point support with BF16 or BF16+FP16
- Scalable real-time AI / neural processor IP with up to 3,500 TOPS performance
- Supports CNNs, transformers, including generative AI, recommender networks, RNNs/LSTMs, etc.
- Industry leading power efficiency (up to 30 TOPS/W)
- One 1K MAC core or 1-24 cores of an enhanced 4K MAC/core convolution accelerator
-
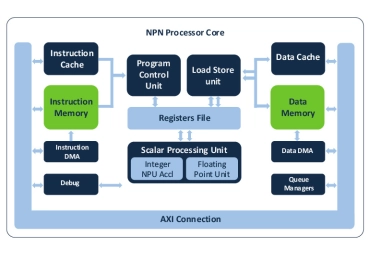
NPU IP for Embedded ML
- Fully programmable to efficiently execute Neural Networks, feature extraction, signal processing, audio and control code
- Scalable performance by design to meet wide range of use cases with MAC configurations with up to 64 int8 (native 128 of 4x8) MACs per cycle
- Future proof architecture that supports the most advanced ML data types and operators
-
Embedded AI accelerator IP
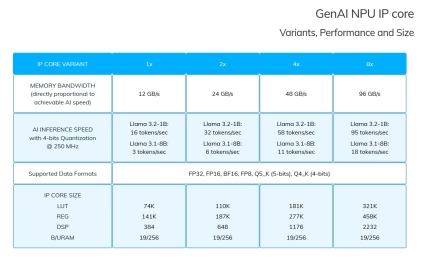
- The GenAI IP is the smallest version of our NPU, tailored to small devices such as FPGAs and Adaptive SoCs, where the maximum Frequency is limited (<=250 MHz) and Memory Bandwidth is lower (<=100 GB/s).
-
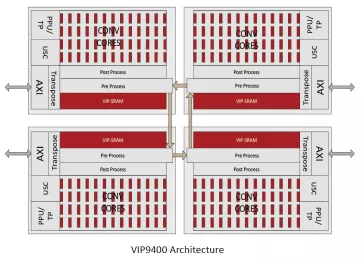
NPU IP for Data Center and Automotive
- 128-bit vector processing unit (shader + ext)
- OpenCL 1.2 shader instruction set
- Enhanced vision instruction set (EVIS)
- INT 8/16/32b, Float 16/32b in PPU
- Convolution layers
-
ARC NPX Neural Processing Unit (NPU) IP supports the latest, most complex neural network models and addresses demands for real-time compute with ultra-low power consumption for AI applications
- ARC processor cores are optimized to deliver the best performance/power/area (PPA) efficiency in the industry for embedded SoCs. Designed from the start for power-sensitive embedded applications, ARC processors implement a Harvard architecture for higher performance through simultaneous instruction and data memory access, and a high-speed scalar pipeline for maximum power efficiency. The 32-bit RISC engine offers a mixed 16-bit/32-bit instruction set for greater code density in embedded systems.
- ARC's high degree of configurability and instruction set architecture (ISA) extensibility contribute to its best-in-class PPA efficiency. Designers have the ability to add or omit hardware features to optimize the core's PPA for their target application - no wasted gates. ARC users also have the ability to add their own custom instructions and hardware accelerators to the core, as well as tightly couple memory and peripherals, enabling dramatic improvements in performance and power-efficiency at both the processor and system levels.
- Complete and proven commercial and open source tool chains, optimized for ARC processors, give SoC designers the development environment they need to efficiently develop ARC-based systems that meet all of their PPA targets.
-
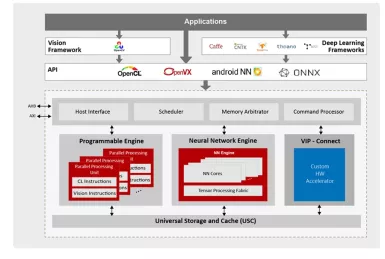
NPU IP for AI Vision and AI Voice
- 128-bit vector processing unit (shader + ext)
- OpenCL 3.0 shader instruction set
- Enhanced vision instruction set (EVIS)
- INT 8/16/32b, Float 16/32b
-
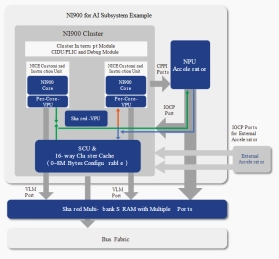
AI DSA Processor - 9-Stage Pipeline, Dual-issue
- NI900 is a DSA processor based on 900 Series.
- NI900 is optimized with features specifically targeting AI applications.
-
Safety Enhanced GPNPU Processor IP
- A True SDV Solution
- Fully programmable – ideal for long product life cycles
- Scalable multicore solutions up to 864 TOPS
- Solutions for ADAS, IVI and ECU products