ReRAM-Powered Edge AI: A Game-Changer for Energy Efficiency, Cost, and Security

In AI inference, trained models apply their knowledge to make predictions and decisions. To achieve lower latency and better security, the world is transitioning steadily towards performing AI inference at the edge – without sending data back and forth to the cloud – for a wide range of applications.
Because edge devices are often small, battery-powered, and resource-constrained, it’s important that the computing resources enabling this process and the associated memories are ultra-low-power and low-cost. This is a challenge for AI workloads, which are known to be power-hungry.
The industry has been making progress towards lower power computation largely by moving to more advanced process nodes. This enables more performance with greater energy efficiency in smaller silicon area. However, non-volatile memories (NVMs) haven’t been able to scale to advanced nodes along with logic. Today we see advanced chips in process nodes of 3nm. At the same time, embedded flash memory is unable to scale below 28nm. This means that NVM and AI engines are often manufactured at very different process nodes and can’t be integrated on the same silicon die.
This is one of many reasons why the industry is exploring new memory technologies like Weebit ReRAM (RRAM).
The need for a single-die solution
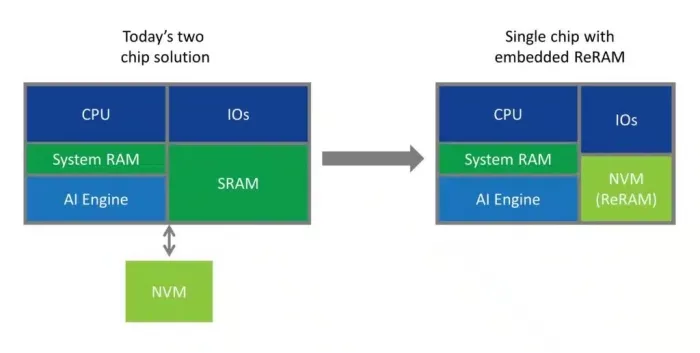
Neural Network coefficients (often referred to as NN weights), which are used for computations by the inference engine, need to be stored in an NVM, so that when the system is powered-on these coefficients are available for compute workloads. Because it’s not possible to integrate flash and an AI engine on one die below 28nm, it is standard practice to implement a two-die solution, with one die at a small process node used for computing, and the other die at a larger process node used for storing the coefficients. These two dies are then either integrated in a single package or in two separate packages. Either way, such a two-die solution is more expensive and has a bigger footprint. Also, copying the coefficients from an external flash to an on-chip SRAM in the AI chip is very power hungry and creates latencies. In addition, the fact that the coefficients are moved from one chip to the other creates a security risk, as it is easy to eavesdrop this communication.
The ideal solution for edge AI computing from power, latency, cost and security perspectives is a single die that hosts both memory and compute.
A scalable, single-chip solution with ReRAM
Embedded ReRAM is the logical alternative to flash for edge AI. ReRAM is significantly more energy efficient than flash, and it provides better endurance and faster program time. Since it is scalable to advanced processes, ReRAM enables a true one-chip solution, with NVM and computing integrated on the same die.
ReRAM-enabled SoCs are less expensive to manufacture because they only require two additional masks in the manufacturing flow, while flash requires 10 or even more such masks. Embedding ReRAM into an AI SoC would eliminate the need for off-chip flash devices and replace most of the large on-chip SRAM used to temporarily store the NN weights. Since the technology is non-volatile, the system can boot much faster as there is no need to wait for loading the AI model and firmware from external NVM, and the security risk is removed. ReRAM is also much denser than SRAM, so more memory can be integrated on-chip to support larger neural networks for the same die size and cost, while enabling more advanced AI algorithms.
New Demo: ReRAM for ultra-low-power edge AI
A new demonstration showcases the advantages of Weebit ReRAM-powered edge AI computing. Developed through a collaboration between Weebit and Embedded AI Systems Pte. Ltd. (EMASS), a subsidiary of Nanoveu, the gesture recognition demo shows Weebit ReRAM working with EMASS’s energy-efficient AI SoC, the EMASS ECS-DOT. The demo emphasizes the ultra-low-power consumption of ReRAM and its ability to enable instant wake-up AI operations. In the real world, such a system could be used to detect driver activity for advanced driver safety systems, or it could be used for safety/surveillance, robotics, and many other applications.
ECS-DOT is an edge AI chip manufactured in a 22nm process that delivers significant energy efficiency and cost advantages, with best-in-class AI capacity. In the demo, ECS-DOT loads the neural network weights from Weebit ReRAM where they are being stored. As noted earlier, this is a powerful feature of ReRAM – it can be used to replace the large on-chip SRAM to store the NN weights, as well as the CPU firmware.
Weebit ReRAM isn’t yet integrated into the ECS-DOT SoC, so the proof-of-concept demo shows a two-chip solution with the 22nm Weebit demo chip communicating with the EMASS chip over an SPI bus. In an end solution, the ReRAM would be integrated on-chip, eliminating latency, cost and security risks, and demonstrating even lower power consumption. Such integration can enhance system performance and also ensure scalability and sustainability, paving the way for smarter, more autonomous edge devices.
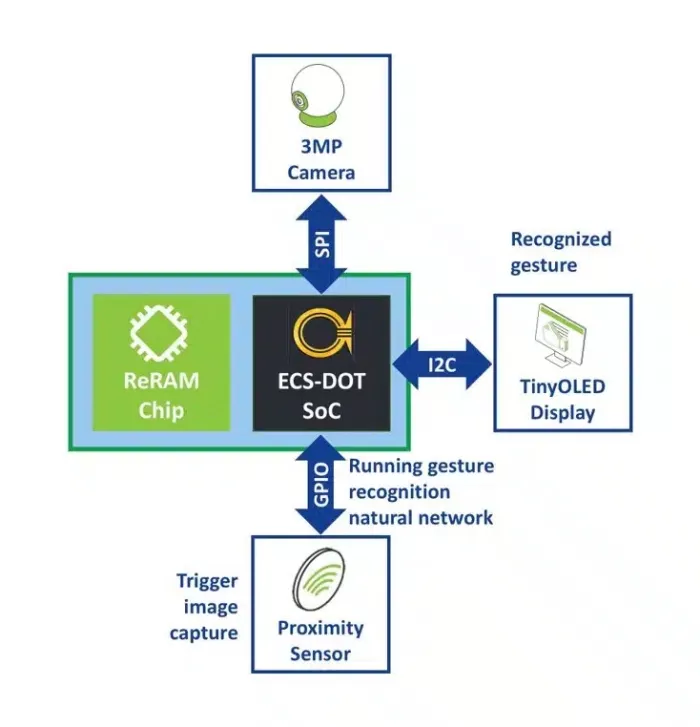
Above: ultra-low-power ReRAM based gesture recognition system
with Weebit ReRAM and EMASS AI SoC
EMASS recently made a strategic pivot away from MRAM technology and is embracing ReRAM. The company says that ReRAM is better able to support next-generation systems in IoT, automotive, and consumer electronics.
Looking Ahead
Research is now underway to bring memory and compute resources even closer together through analog in-memory compute. In this paradigm, compute resources and memory reside in the same location, so there is no need to ever move the coefficients. Such a solution using ReRAM will be orders of magnitude more power-efficient than today’s neural network simulations on traditional processors.
You can see our new demo video here:
Related Semiconductor IP
- ReRAM NVM in SkyWater 130nm
- ReRAM NVM in DB HiTek 130nm BCD
- RERAM Memory Model
- ReRAM Secure Keys
- ReRAM as FTP/OTP Memory
Related Blogs
- The Industry’s First USB4 Device IP Certification Will Speed Innovation and Edge AI Enablement
- Real-Time Intelligence for Physical AI at the Edge
- Ceva-XC21 and Ceva-XC23 DSPs: Advancing Wireless and Edge AI Processing
- Enhancing Edge AI with the Newest Class of Processor: Tensilica NeuroEdge 130 AICP
Latest Blogs
- IDS-Verify™: From Specification to Sign-Off – Automated CSR, Hardware Software Interface and CPU-Peripheral Interface Verification
- RISC-V and GPU Synergy in Practice: A Path Towards High-Performance SoCs from SpacemiT K3
- EDA AI Agents: Intelligent Automation in Semiconductor & PCB Design
- Why Security Can't Exist Without Trust
- Universal Browser Support for JPEG XL: Is Your Hardware Ready for the New Standard?