Edge AI Processor IP
Filter
Compare
38
IP
from
27
vendors
(1
-
10)
-
Dataflow AI Processor IP
- Revolutionary dataflow architecture optimized for AI workloads with spatial compute arrays, intelligent memory hierarchies, and runtime reconfigurable elements
-
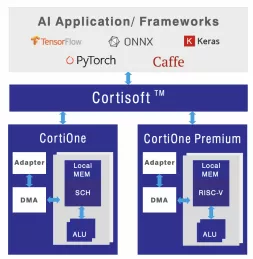
AI Processor Accelerator
- Universal Compatibility: Supports any framework, neural network, and backbone.
- Large Input Frame Handling: Accommodates large input frames without downsizing.
-
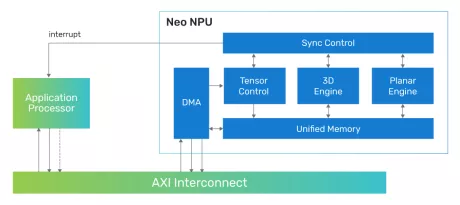
Highly scalable performance for classic and generative on-device and edge AI solutions
- Flexible System Integration: The Neo NPUs can be integrated with any host processor to offload the AI portions of the application
- Scalable Design and Configurability: The Neo NPUs support up to 80 TOPS with a single-core and are architected to enable multi-core solutions of 100s of TOPS
- Efficient in Mapping State-of-the-Art AI/ML Workloads: Best-in-class performance for inferences per second with low latency and high throughput, optimized for achieving high performance within a low-energy profile for classic and generative AI
- Industry-Leading Performance and Power Efficiency: High Inferences per second per area (IPS/mm2 and per power (IPS/W)
-
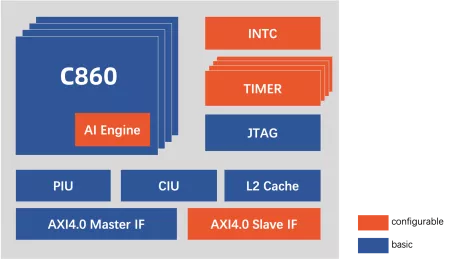
High-performance 32-bit multi-core processor with AI acceleration engine
- Instruction set: T-Head ISA (32-bit/16-bit variable-length instruction set);
- Multi-core: Isomorphic multi-core, with 1 to 4 optional cores;
- Pipeline: 12-stage;
- Microarchitecture: Tri-issue, deep out-of-order;
-
AI inference processor IP
- High Performance, Low Power Consumption, Small Foot Print IP for Deep Learning inference processing.
-
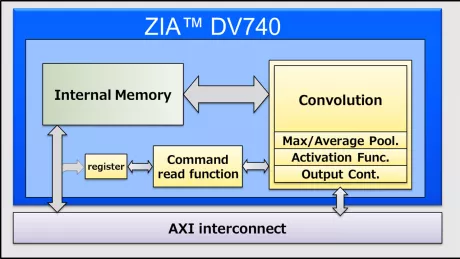
Performance AI Accelerator for Edge Computing
- Up to 16 TOPS
- Up to 16 MB Local Memory
- RISC-V/Arm Cortex-R or A 32-bit CPU
- 3 x AXI4, 128b (Host, CPU & Data)
-
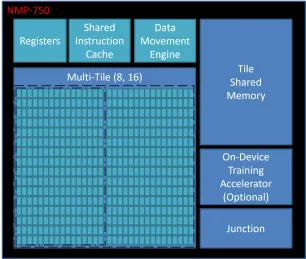
Neural engine IP - The Cutting Edge in On-Device AI
- The Origin E6 is a versatile NPU that is customized to match the needs of next-generation smartphones, automobiles, AV/VR, and consumer devices.
- With support for video, audio, and text-based AI networks, including standard, custom, and proprietary networks, the E6 is the ideal hardware/software co-designed platform for chip architects and AI developers.
- It offers broad native support for current and emerging AI models, and achieves ultra-efficient workload scheduling and memory management, with up to 90% processor utilization—avoiding dark silicon waste.
-
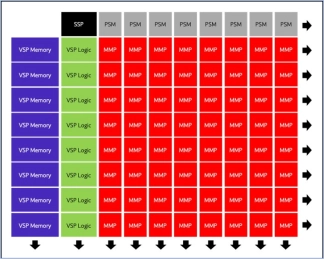
Neural network processor designed for edge devices
- High energy efficiency
- Support mainstream deep learning frameworks
- Low power consumption
- An integrated AI solution
-
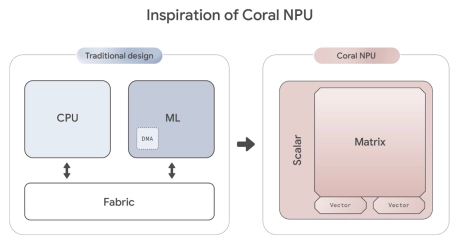
RISC-V-Based, Open Source AI Accelerator for the Edge
- Coral NPU is a machine learning (ML) accelerator core designed for energy-efficient AI at the edge.
- Based on the open hardware RISC-V ISA, it is available as validated open source IP, for commercial silicon integration.
-
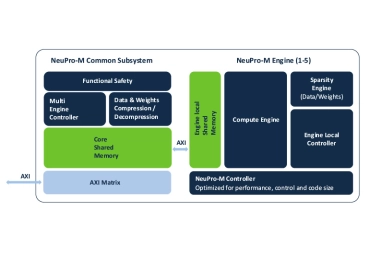
Scalable Edge NPU IP for Generative AI
- Ceva-NeuPro-M is a scalable NPU architecture, ideal for transformers, Vision Transformers (ViT), and generative AI applications, with an exceptional power efficiency of up to 3500 Tokens-per-Second/Watt for a Llama 2 and 3.2 models
- The Ceva-NeuPro-M Neural Processing Unit (NPU) IP family delivers exceptional energy efficiency tailored for edge computing while offering scalable performance to handle AI models with over a billion parameters.