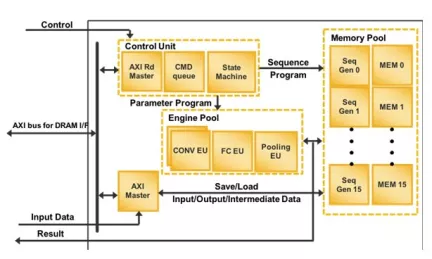
CNN IP
Filter
Compare
43
IP
from
16
vendors
(1
-
10)
-
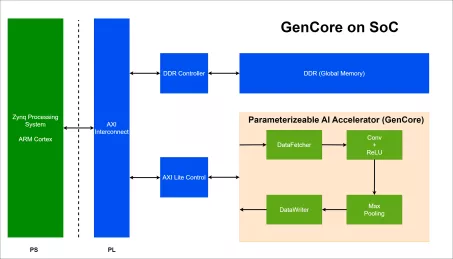
AI Accelerator Specifically for CNN
- A specialized hardware with controlled throughput and hardware cost/resources, utilizing parameterizeable layers, configurable weights, and precision settings to support fixed-point operations.
- This hardware aim to accelerate inference operations, particulary for CNNs such as LeNet-5, VGG-16, VGG-19, AlexNet, ResNet-50, etc.
-
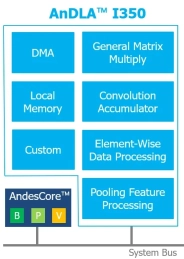
Convolutional Neural Network (CNN) Compact Accelerator
- Support convolution layer, max pooling layer, batch normalization layer and full connect layer
- Configurable bit width of weight (16 bit, 1 bit)
-
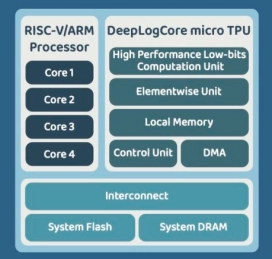
CNN AI IP Core
- DeepMentor has developed an AI IP that combines low-power and high-performance features with the RISC-V SOC.
- This integration allows customers to quickly create unique AI SOC without worrying about software integration or system development issues.
- DeepLogCore supports both RISC-V and ARM systems, enabling faster and more flexible development.
-
Verification IP for CSI/DSI/C-PHY/D-PHY
- A comprehensive VIP solution for CSI-2, DSI-2, D-PHY and C-PHY transmitter and receiver designs.
- CSI/DSI-Xactor implements a complete set of models, protocol checkers and compliance testsuites in 100% native SystemVerilog and UVM.
-
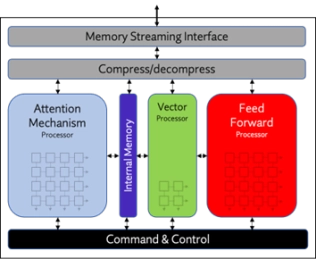
NPU IP Core for Edge
- Origin Evolution™ for Edge offers out-of-the-box compatibility with today's most popular LLM and CNN networks. Attention-based processing optimization and advanced memory management ensure optimal AI performance across a variety of networks and representations.
- Featuring a hardware and software co-designed architecture, Origin Evolution for Edge scales to 32 TFLOPS in a single core to address the most advanced edge inference needs.
-
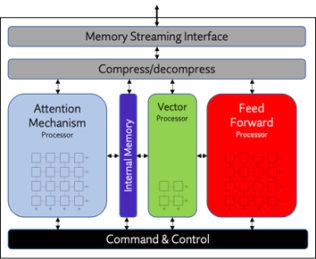
NPU IP Core for Mobile
- Origin Evolution™ for Mobile offers out-of-the-box compatibility with popular LLM and CNN networks. Attention-based processing optimization and advanced memory management ensure optimal AI performance across a variety of today’s standard and emerging neural networks.
- Featuring a hardware and software co-designed architecture, Origin Evolution for Mobile scales to 64 TFLOPS in a single core.
-
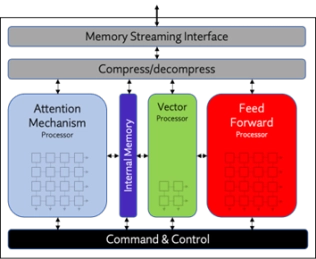
NPU IP Core for Data Center
- Origin Evolution™ for Data Center offers out-of-the-box compatibility with popular LLM and CNN networks. Attention-based processing optimization and advanced memory management ensure optimal AI performance across a variety of today’s standard and emerging neural networks. Featuring a hardware and software co-designed architecture, Origin Evolution for Data Center scales to 128 TFLOPS in a single core, with multi-core performance to PetaFLOPs.
-
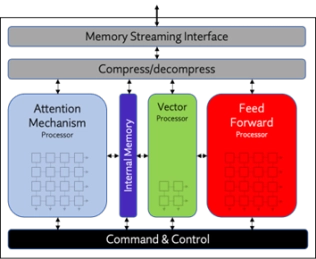
NPU IP Core for Automotive
- Origin Evolution™ for Automotive offers out-of-the-box compatibility with popular LLM and CNN networks. Attention-based processing optimization and advanced memory management ensure optimal AI performance across a variety of today’s standard and emerging neural networks.
- Featuring a hardware and software co-designed architecture, Origin Evolution for Automotive scales to 96 TFLOPS in a single core, with multi-core performance to PetaFLOPs.
-
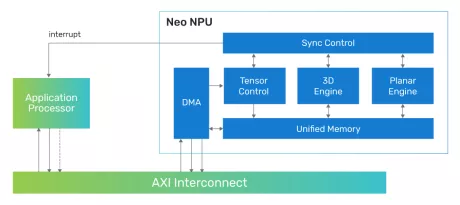
Highly scalable performance for classic and generative on-device and edge AI solutions
- Flexible System Integration: The Neo NPUs can be integrated with any host processor to offload the AI portions of the application
- Scalable Design and Configurability: The Neo NPUs support up to 80 TOPS with a single-core and are architected to enable multi-core solutions of 100s of TOPS
- Efficient in Mapping State-of-the-Art AI/ML Workloads: Best-in-class performance for inferences per second with low latency and high throughput, optimized for achieving high performance within a low-energy profile for classic and generative AI
- Industry-Leading Performance and Power Efficiency: High Inferences per second per area (IPS/mm2 and per power (IPS/W)
-
High performance-efficient deep learning accelerator for edge and end-point inference
- Configurable MACs from 32 to 4096 (INT8)
- Maximum performance 8 TOPS at 1GHz
- Configurable local memory: 16KB to 4MB