Can Your NPU Run DOOM? Chimera Can.
Is your NPU DOOMed? Quadric's Chimera GPNPU runs every AI model — and a complete DOOM engine. Find out why Quadric is different.
Our IP inference accelerators enhance AI computations, providing outstanding performance across various applications.
Note: some files may require an NDA depending on provider policy.

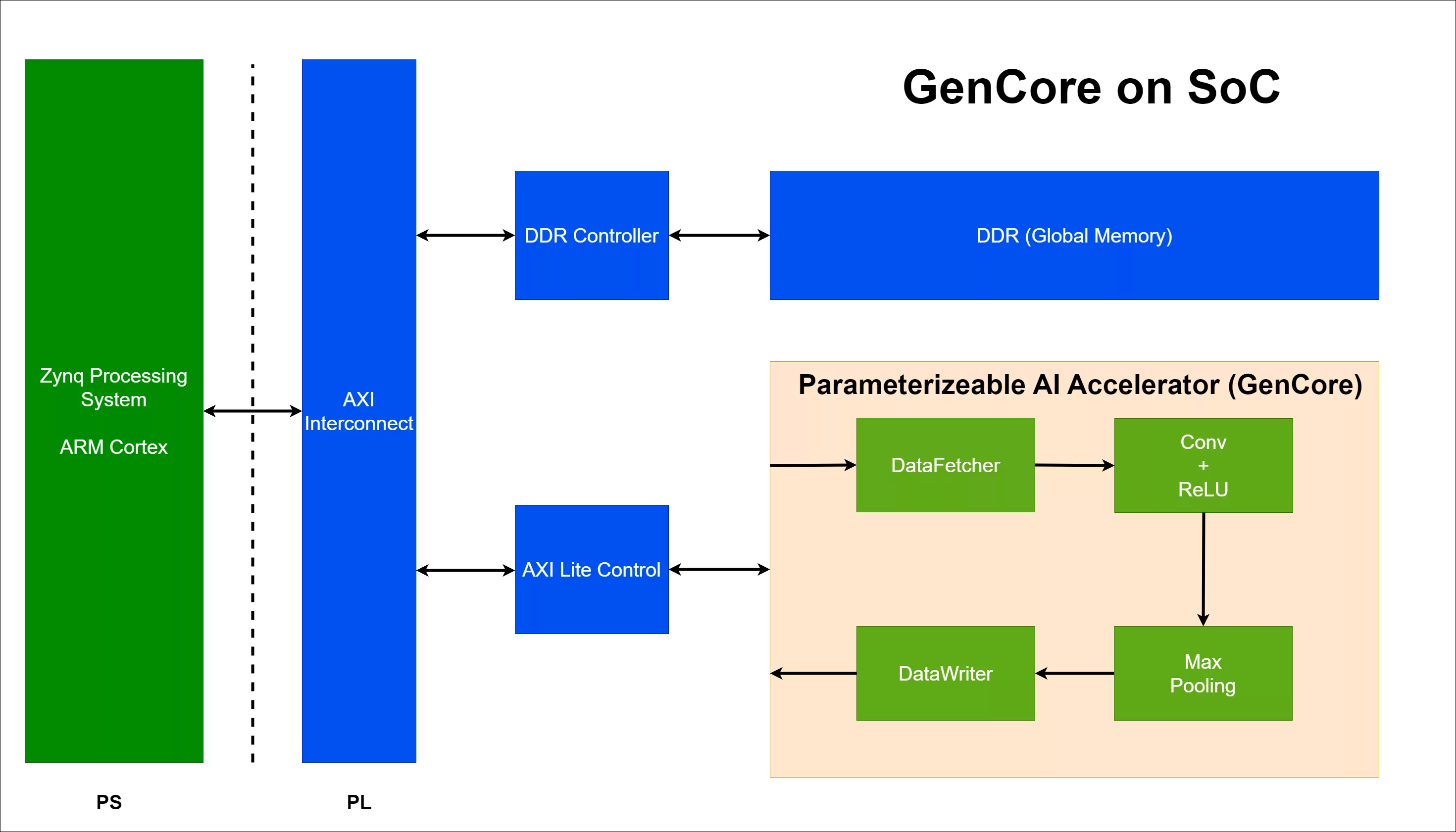
AI Accelerator Specifically for CNN is a NPU IP core from Batik Semiconductor listed on Semi IP Hub.
Engineers should review the overview, key features, supported foundries and nodes, maturity, deliverables, and provider information before shortlisting this NPU IP.
Yes. Buyers can compare this product with similar semiconductor IP cores or IP families based on category, provider, process options, and structured technical specifications.